
Concept mining. Concept mining is an activity that results in the extraction of concepts from artifacts.
Solutions to the task typically involve aspects of artificial intelligence and statistics, such as data mining and text mining.[1] Because artifacts are typically a loosely structured sequence of words and other symbols (rather than concepts), the problem is nontrivial, but it can provide powerful insights into the meaning, provenance and similarity of documents. Methods[edit] Traditionally, the conversion of words to concepts has been performed using a thesaurus,[2] and for computational techniques the tendency is to do the same.
The thesauri used are either specially created for the task, or a pre-existing language model, usually related to Princeton's WordNet. The mappings of words to concepts[3] are often ambiguous. There are many techniques for disambiguation that may be used. Information extraction. Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents.
In most of the cases this activity concerns processing human language texts by means of natural language processing (NLP). Recent activities in multimedia document processing like automatic annotation and content extraction out of images/audio/video could be seen as information extraction. Due to the difficulty of the problem, current approaches to IE focus on narrowly restricted domains. An example is the extraction from news wire reports of corporate mergers, such as denoted by the formal relation: from an online news sentence such as: "Yesterday, New York based Foo Inc. announced their acquisition of Bar Corp.
" A broad goal of IE is to allow computation to be done on the previously unstructured data. History[edit] Beginning in 1987, IE was spurred by a series of Message Understanding Conferences. Natural Language Processing (NLP) Terminology extraction. Terminology extraction (also known as term extraction, glossary extraction, term recognition, or terminology mining) is a subtask of information extraction.
The goal of terminology extraction is to automatically extract relevant terms from a given corpus.[1] In the semantic web era, a growing number of communities and networked enterprises started to access and interoperate through the internet. Modeling these communities and their information needs is important for several web applications, like topic-driven web crawlers,[2] web services,[3] recommender systems,[4] etc.
The development of terminology extraction is also essential to the language industry. Bilingual terminology extraction[edit] The methods for terminology extraction can be applied to parallel corpora. See also[edit] References[edit] ^ Alrehamy, Hassan H; Walker, Coral (2018). Part-of-speech tagging. Once performed by hand, POS tagging is now done in the context of computational linguistics, using algorithms which associate discrete terms, as well as hidden parts of speech, in accordance with a set of descriptive tags.
POS-tagging algorithms fall into two distinctive groups: rule-based and stochastic. E. Brill's tagger, one of the first and most widely used English POS-taggers, employs rule-based algorithms. Principle[edit] Part-of-speech tagging is harder than just having a list of words and their parts of speech, because some words can represent more than one part of speech at different times, and because some parts of speech are complex or unspoken. The sailor dogs the hatch. Correct grammatical tagging will reflect that "dogs" is here used as a verb, not as the more common plural noun. Constraint Grammar. The Constraint Grammar concept was launched by Fred Karlsson in 1990 (Karlsson 1990; Karlsson et al., eds, 1995), and CG taggers and parsers have since been written for a large variety of languages, routinely achieving accuracy F-scores for part of speech (word class) of over 99%.[1] A number of syntactic CG systems have reported F-scores of around 95% for syntactic function labels.

CG systems can be used to create full syntactic trees in other formalisms by adding small, non-terminal based phrase structure grammars or dependency grammars, and a number of Treebank projects have used Constraint Grammar for automatic annotation. CG methodology has also been used in a number of language technology applications, such as spell checkers and machine translation systems. Implementations[edit] The first CG implementation was CGP by Fred Karlsson. It was purely LISP-based, and the syntax was based on LISP s-expressions (Karlsson 1990). Treebank. Etymology[edit] Both syntactic and semantic structure are commonly represented compositionally as a tree structure, hence the name treebank (analogous to other repositories such as a seedbank or bloodbank).
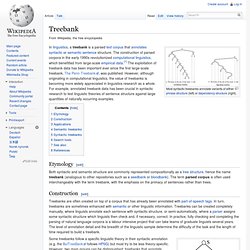
The term parsed corpus is often used interchangeably with the term treebank, with the emphasis on the primacy of sentences rather than trees. Construction[edit] Treebanks are often created on top of a corpus that has already been annotated with part-of-speech tags. In turn, treebanks are sometimes enhanced with semantic or other linguistic information. Example phrase structure tree for John loves Mary Some treebanks follow a specific linguistic theory in their syntactic annotation (e.g. the BulTreeBank follows HPSG) but most try to be less theory-specific. It is important to clarify the distinction between the formal representation and the file format used to store the annotated data.