Organizing, understanding, analysis, & publishing
> John_blue
What are some approaches to taking in information, looking at it for understanding, figuring out some bits / nuggets of additional info, and then sharing (publishing) back to an audience? This is a collection to help understand this topic.
The Day Steph Curry Made 105 3 Point Shots in a Row. The 10-Step Process to Build a Thriving Community from Scratch. How do you get a brand new community off the ground?

Recently, I shared six important lessons on this topic. But I know what you really want… you want a clear process. How do you actually build the community? What are the steps? I get this question constantly, so I decided to share my process for getting new communities off the ground. Every successful community I’ve launched has followed these steps.
No Ghost in the Machine - <a href=' Halpern</a>
iStock It is desirable to guard against the possibility of exaggerated ideas that might arise as to the powers of the Analytical Engine.
In considering any new subject, there is frequently a tendency, first, to overrate what we find to be already interesting or remarkable; and, secondly, by a sort of natural reaction, to undervalue the true state of the case, when we do discover that our notions have surpassed those that were really tenable. The Analytical Engine has no pretensions whatever to originate anything.
Portacle - A Portable Common Lisp Development Environment. The Website Obesity Crisis. Let me give you a concrete example.
I recently heard from a competitor, let’s call them ACME Bookmarking Co., who are looking to leave the bookmarking game and sell their website.
Knowledge extraction from unstructured texts. Foreword There is an unreasonable amount of information that can be extracted from what people publicly say on the internet.

At Heuritech we use this information to better understand what people want, which products they like and why. This post explains from a scientific point of view what is Knowledge extraction and details a few recent method on how to do it.
Sheet2Site — Create a website from Google Sheets without writing code. STELLA Manual: STELLA Manual. Wkhtmltopdf. Famous Writers’ Sleep Habits vs. Literary Productivity, Visualized. “In both writing and sleeping,” Stephen King observed in his excellent meditation on the art of “creative sleep” and wakeful dreaming, “we learn to be physically still at the same time we are encouraging our minds to unlock from the humdrum rational thinking of our daytime lives.”
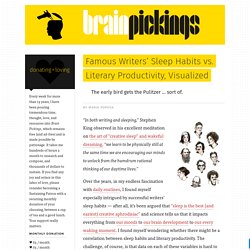
Over the years, in my endless fascination with daily routines, I found myself especially intrigued by successful writers’ sleep habits — after all, it’s been argued that “sleep is the best (and easiest) creative aphrodisiac” and science tells us that it impacts everything from our moods to our brain development to our every waking moment. I found myself wondering whether there might be a correlation between sleep habits and literary productivity. The challenge, of course, is that data on each of these variables is hard to find, hard to quantify, or both.
The 50 Best Free Datasets for Machine Learning - Gengo AI. What are some open datasets for machine learning?

We at Gengo decided to create the ultimate cheat sheet for high quality datasets. These range from the vast (looking at you, Kaggle) or the highly specific (data for self-driving cars).
Blog.md. Stacking the Bricks: What I learned making a living on eBay. Tim Ewald - Clojure: Programming with Hand Tools. The digital guru who helped Donald Trump to the presidency. OEC: The Observatory of Economic Complexity.
The Psychology of Social Media: Why We Like, Comment, and Share Online. What would happen if you were to “like” everything you saw on social media?
The developer Rameet Chawla found out when he built a script that liked every photo that passed through his Instagram feed. He grew his followers by about 30 a dayHe got invited to more partiesHe got stopped on the street by people who recognized him from InstagramHe got message after message from friends encouraging him to post more. He said it was “almost like they were frustrated, like they were longing for something to like in return.” The likes, comments and posts we share on social media can often seem inconsequential, but they matter.
Preserving Team Knowledge in the Gig Economy. Do you remember your parents or grandparents staying in the same job for their entire lives?
Conscious Collaboration- Self-Organisation Beyond Hierarchy. The book Reinventing Organizations’ has sparked huge interest in self-organisation beyond hierarchy.
Of the many options available, how do we choose those which will work for our clients and their organisations? This session contextualises the shift beyond hierarchy and provides a map to help you make conscious choices to navigate this complex transition. Our volatile, uncertain, complex and ambiguous 21st century requires new ways of organising and working together - how do we self-organise collaboratively beyond hierarchy?
With intelligence program, Catholic becomes place to learn [REDACTED]
Cambridge Analytica: the Geotargeting and Emotional Data Mining Scripts. Last year, Michael Phillips, a data science intern at Cambridge Analytica, posted the following scripts to a set of “work samples” on his personal GitHub account.

The Github profile, MichaelPhillipsData is still around. It contains a selection of Phillips’ coding projects.
LOOPY: a tool for thinking in systems. Enhancing Twitter Data Analysis with Simple Semantic Filtering: Example in Tracking Influenza-Like Illnesses. The great British Brexit robbery: how our democracy was hijacked. “The connectivity that is the heart of globalisation can be exploited by states with hostile intent to further their aims.[…] The risks at stake are profound and represent a fundamental threat to our sovereignty.” Alex Younger, head of MI6, December, 2016.
How the Trump-Russia Data Machine Games Google to Fool Americans. A year ago I was part of a digital marketing team at a tech company.
About 1999.io. How is 1999.io different fromother blogging platforms? 1999.io is easy for writers to get started with, is completely customizable by designers, and can be extended by programmers through easy APIs and full access to the server code. Create a new post in two steps. Enter text into the box, then click the Post button.
New DataBasic Tool Lets You “Connect the Dots” in Data. Catherine D'Ignazio and I have launched a new DataBasic tool and activity, Connect the Dots, aimed at helping students and educators see how their data is connected with a visual network diagram.
By showing the relationships between things, networks are useful for finding answers that aren’t readily apparent through spreadsheet data alone. To that end, we’ve built Connect the Dots to help teach how analyzing the connections between the “dots” in data is a fundamentally different approach to understanding it. The new tool gives users a network diagram to reveal links as well as a high level report about what the network looks like. Using network analysis helped Google revolutionize search technology and was used by journalists who investigated the connections between people and banks during the Panama Papers Leak. Learn more about Connect the Dots and all the DataBasic tools here. Have you used DataBasic tools in your classroom, organization, or personal projects?
NodeXL Graph Gallery: Graph Details. The graph represents a network of 1,613 Twitter users whose recent tweets contained "#agchat", or who were replied to or mentioned in those tweets, taken from a data set limited to a maximum of 18,000 tweets.
The network was obtained from Twitter on Tuesday, 13 December 2016 at 16:56 UTC. The tweets in the network were tweeted over the 9-day, 18-hour, 37-minute period from Saturday, 03 December 2016 at 22:04 UTC to Tuesday, 13 December 2016 at 16:42 UTC. There is an edge for each "replies-to" relationship in a tweet, an edge for each "mentions" relationship in a tweet, and a self-loop edge for each tweet that is not a "replies-to" or "mentions". The graph is directed.
Pattern recognition - Wikipedia. Pattern recognition algorithms generally aim to provide a reasonable answer for all possible inputs and to perform "most likely" matching of the inputs, taking into account their statistical variation.
This is opposed to pattern matching algorithms, which look for exact matches in the input with pre-existing patterns. A common example of a pattern-matching algorithm is regular expression matching, which looks for patterns of a given sort in textual data and is included in the search capabilities of many text editors and word processors.
In contrast to pattern recognition, pattern matching is generally not considered a type of machine learning, although pattern-matching algorithms (especially with fairly general, carefully tailored patterns) can sometimes succeed in providing similar-quality output to the sort provided by pattern-recognition algorithms. Overview[edit]
What is Pattern Analysis?
PATN is a software package that performs Pattern Analysis. PATN aims to try and display patterns in complex data.
SAVI. Spreadsheets Are Graphs Too! - Neo4j Graph Database. Tutorial 1: Introducing Graph Data. Next: Introducing RDF The semantic web can seem unfamiliar and daunting territory at first.
SKOS Simple Knowledge Organization System - home page. What is an ontology and why we need it. Figure 8.
MooWheel: a javascript connections visualization library. View the project on Google Code 06.29.2008 version 0.2 now available!
SPARQL in 11 minutes. OntoWiki — Agile Knowledge Engineering and Semantic Web. CubeViz -- Exploration and Visualization of Statistical Linked Data Facilitating the Exploration and Visualization of Linked Data Supporting the Linked Data Life Cycle Using an Integrated Tool Stack Increasing the Financial Transparency of European Commission Project Funding Managing Multimodal and Multilingual Semantic Content Improving the Performance of Semantic Web Applications with SPARQL Query Caching.
Swj210 1. 20 Big Data Repositories You Should Check Out. DBpedia. Welcome - the Datahub. Tutorial 4: Introducing RDFS & OWL. Next: Querying Semantic Data Having introduced the advantages of modeling vocabulary and semantics in data models, let's introduce the actual technology used to attribute RDF data models with semantics. RDF data can be encoded with semantic metadata using two syntaxes: RDFS and OWL. After this tutorial, you should be able to: Understand how RDF data models are semantically encoded using RDFS and OWLUnderstand that OWL ontologies are RDF documentsUnderstand OWL classes, subclasses and individualsUnderstand OWL propertiesBuild your own basic ontology, step by stepEstimated time: 5 minutes.
How to organize your EndNote library. Knowledge management. Knowledge base.
