
OpenBR: Main Page. Portraits- Collections at OpenProcessing. Face Detection Matlab Code. We present a unified model for face detection, pose estimation, and landmark estimation in real-world, cluttered images.

Our model is based on a mixtures of trees with a shared pool of parts; we model every facial landmark as a part and use global mixtures to capture topological changes due to viewpoint. We show that tree-structured models are surprisingly effective at capturing global elastic deformation, while being easy to optimize unlike dense graph structures. We present extensive results on standard face benchmarks, as well as a new "in the wild" annotated dataset, that suggests our system advances the state-of-the-art, sometimes considerably, for all three tasks. Though our model is modestly trained with hundreds of faces, it compares favorably to commercial systems trained with billions of examples (such as Google Picasa and face.com). X. CALVIN software. Energy Minimization with Learned State Filters Project page This is a MATLAB implementation of Learned State Filters for fast discrete pairwise energy minimization as presented in the CVPR2013 publication.
For convenient comparison to other energy minimization work, we have also included code for TRW-S, alpha-expansion, alpha-expand beta-shrink and loopy belief propagation. Fast Video Segmentation v1.1 (February 2013) This software release covers the segmentation method presented in "Fast object segmentation in unconstraint video", A. Marcos Nieto - Personal webpage - Research on computer vision. LEAR. LDAHash: Binary Descriptor for Large-scale Applications. Dynamic and Scalable Large Scale Image Reconstruction SIFT-like local feature descriptors are ubiquitously employed in such computer vision applications as content-based retrieval, video analysis, copy detection, object recognition, photo-tourism and 3D reconstruction.

Feature descriptors can be designed to be invariant to certain classes of photometric and geometric transformations, in particular, affine and intensity scale transformations. However, real transformations that an image can undergo can only be approximately modeled in this way, and thus most descriptors are only approximately invariant in practice. Secondly, descriptors are usually high-dimensional (e.g. Research. Alpha Matting Evaluation Website. Test Dataset (Hidden ground-truth alpha) *Objects photographed in front of a natural 3D scene.
**Objects photographed in front of a monitor showing natural images. Training Dataset (With public availaible ground-truth alpha) Move the mouse over the images to see the corresponding ground truth alpha. *Objects photographed in front of a natural 3D scene. Del Moral - Filtering. DirectShow Virtual Video Capture Source Filter in C# Introduction Implementation of this filter is based on my BaseClasses.NET library which described in my previous post (Pure .NET DirectShow Filters in C#).
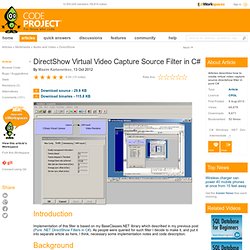
As people were queried for such filter I decide to make it, and put it into separate article as here, I think, necessary some implementation notes and code description. Background Implementation Core functionality of the filter will be capturing screen and provide that data as a video stream, it works same way as in previous post. [ComVisible(false)] public class VirtualCamStream: SourceStream , IAMStreamControl , IKsPropertySet , IAMPushSource , IAMLatency , IAMStreamConfig , IAMBufferNegotiation ......... As you can see I have made support of other interfaces for output pin, actually you can implement all same interfaces as the real WDM Proxy Filter, but I made only most useful interfaces for applications. IKsPropertySet interface Using this interface we specify pin category guid. IAMStreamConfig interface. K-means and X-means implementations. Read the K-means paper (PS), or K-means paper (PDF) .Note: recently a similar, though independent, result, was brought to our attention.

It predates our work. For completeness, you can read that too. SWT: Stroke Width Transform. Library Reference: ccv_swt.c (This documentation is still largely work in progress, use with caution) What’s SWT?

The original paper refers to: Stroke Width Transform, Boris Epshtein, Yonathan Wexler, and Eyal Ofek 2010. How it works? It is a long story, as always, please read their paper. . Checkout output.png, luckily, the text area is labeled. Virtual Video Camera - Computer Graphics Lab - TU Braunschweig. KLT: Kanade-Lucas-Tomasi Feature Tracker. KLT is an implementation, in the C programming language, of a feature tracker for the computer vision community.
Project: Shape and motion from image streams: A factorization method - Naotoshi Seo. Project: Shape and motion from image streams: A factorization method Introduction The structure from motion - recovering scene geometry and camera motion from a sequence of images - is an important task and has wide applicability in many tasks, such as navigation and robot manipulation.

Tomasi and Kanade [1] first developed a factorization method to recover shape and motion under an orthographic projection model, and obtained robust and accurate results. Poelman and Kanade [2] have extended the factorization method to paraperspective projection. Triggs [3] further extended the factorization method to fully perspective projection. In this project, we implemented these three factorization methods, and comparisons are shown. The report is available at. Gmmreg - Robust Point Set Registration Using Gaussian Mixture Models. Imanalyse/lena.jpg from the code source imanalyse : logiciel de traitement de l'image + dithering [win32] c / c++ / c++.net ☼ CodeS-SourceS Files, browse 49 452 812 lines of code available inside the zip. ImAnalyse est un logiciel de traitement de l'image offrant la possibilité à l'utilisateur d'effectuer toute une série de traitement avec juste la souris.
![Imanalyse/lena.jpg from the code source imanalyse : logiciel de traitement de l'image + dithering [win32] c / c++ / c++.net ☼ CodeS-SourceS Files, browse 49 452 812 lines of code available inside the zip](http://cdn.pearltrees.com/s/pic/th/imanalyse-traitement-dithering-74065319)
L'interface graphique a été complètement repensée et réécrite de A à Z en pour plus de simplicité. LIBVISO2: C++ Library for Visual Odometry 2. LIB VISO2 : Library for VIS ual O dometry 2 Author: Andreas Geiger Institute of Measurement and Control Systems Karlsruhe Institute of Technology Please send any feedback or bugreports to: geiger@kit.edu. Blog:pca_in_opencv [ Vision Website. Y-Vladimir/SmartDeblur. Erion Hasanbelliu » Shape Matching. Abstract Describe several algorithms that provide both rigid and non-rigid point-set registration.
The point sets are represented as probability density functions and the registration problem is treated as distribution alignment. Using the PDFs instead of the points provides a more robust way of dealing with outliers and noise, and it mitigates the need to establish a correspondence between the points in the two sets. The algorithms operate on the distance between the two PDFs to recover the spatial transformation function needed to register the two point sets. The distance measures used are based on various famous inequalities/divergence measures. Слежение за точечными особенностями сцены (Point feature tracking) A simple object classifier with Bag-of-Words using OpenCV 2.3 [w/ code] Just wanted to share of some code I've been writing. So I wanted to create a food classifier, for a cool project down in the Media Lab called FoodCam. It's basically a camera that people put free food under, and they can send an email alert to the entire building to come eat (by pushing a huge button marked "Dinner Bell").
Really a cool thing. OK let's get down to business. Метод Виолы-Джонса (Viola-Jones) как основа для распознавания лиц. Compvision.ru. 4YP Report.pdf - cudaseg - Thesis - Level Set Segmentation in CUDA. OpenCV. I introduced CUDA + OpenCV on this page -> In this post, I will introduce TBB + CUDA + OpenCV install(setup) method. TBB is abbreviation of Intel Threading Builidng Block. This supports speed up method using parallel processing of CPU.
OpenCV. Image Processing. Home of pHash, the open source perceptual hash library. Hash Functions First of all, it is important to mention that a perceptual hash (phash) is a signature of an underlying media source file's perceptual content. I say this because it is important to remember what it is not. It cannot do image or audio recognition of certain phrases or image features. It probably cannot even detect similar artifacts from two different source files - e.g. two different photographs of the same person.
Although it may detect a similarity if the lighting and camera angles are nearly identical. So far, pHash is capable of computing hashes for audio, video and image files. Int ph_dct_imagehash(const char *file, ulong64 &hash); ulong64* ph_dct_videohash(const char *file, int &Length); uint32_t* ph_audiohash(float *buf, int N, int sr, int &nbFrames); The image hash is returned in the hash parameter. Float* ph_readaudio(const char *filename, int sr, int channels, int &N); Visual Geometry Group - Texture Classification. Filter Banks We describe the rotationally invariant MR filter sets that are used in the our algorithm for classifying textures with filter banks.
We also describe two other filter sets (LM and S) that will be used in classification comparisons. The aspects of interest are the dimension of the filter space, and whether the filter set is rotationally invariant or not. The Leung-Malik (LM) Filter Bank. Computer Visition, Intelligent Algorithm. Transparent image overlays in OpenCV. Time for some fun! Today we’ll be creating an interesting program today. I’ll be referring to a few old posts I’ve done. The the final result will be you’ll see histograms of R, G and B on top of a live video feed. And they will be semi transparent.
Okay, so lets get started with this! Haar-like features and OpenCV It's just like pok. Введение в компьютерное зрение. Algolist.manual.ru/compress/image/leo_lev/index-1.php. Source Checkout - openvis3d - Open Source 3D Vision Library. CompVision.