
IntelliJ IDEA, Mac OS X and Hibernate ORM. Machine Learning in Action. Resources Summary Machine Learning in Action is unique book that blends the foundational theories of machine learning with the practical realities of building tools for everyday data analysis.

You'll use the flexible Python programming language to build programs that implement algorithms for data classification, forecasting, recommendations, and higher-level features like summarization and simplification. About the Book A machine is said to learn when its performance improves with experience. Angular.js: Autocomplete and enabling a form with $watch and blur. I have that small form, consisting of an jQuery autocomplete and a submit button.
When the user selects something from the autocompleter, I want to store an ID in the model. Only when this ID is set the submit button should be enabled. It sounds easy in first glance, and it is, if you know how. Machine Learning From Streaming Data: Two Problems, Two Solutions, Two Concerns, and Two Lessons. There’s a lot of hype these days around predictive analytics, and maybe even more hype around the topics of “real-time predictive analytics” or “predictive analytics on streaming data”.
Like most things that are over-hyped, what is actually meant by the term is often lost in the noise. In this case that’s really a shame, because these terms refer to at least two different things, either or both of which may be important in a given context. This post forms the basis of a lightning talk I’m giving (remotely) at the Real-time Big Data Meetup in Menlo Park, California. Join the group if you’re interested! Generally, when I hear people talking about “machine learning from streaming data”, they may be talking about a couple of things. They want a model that takes into account recent history when it makes its predictions.
These two phenomena sound like the same thing, but they are potentially very different. So is the sacrifice worth it? Machine Learning Video Library - Learning From Data (Abu-Mostafa) Official VideoLectures.NET Blog » 100 most popular Machine Learning talks at VideoLectures.Net. Enjoy this weeks list!
26971 views, 1:00:45, Gaussian Process Basics, David MacKay, 8 comments7799 views, 3:08:32, Introduction to Machine Learning, Iain Murray16092 views, 1:28:05, Introduction to Support Vector Machines, Colin Campbell, 22 comments5755 views, 2:53:54, Probability and Mathematical Needs, Sandrine Anthoine, 2 comments7960 views, 3:06:47, A tutorial on Deep Learning, Geoffrey E. Avid Barber : Brml - Online browse. Good Freely Available Textbooks on Machine Learning. An Introduction to WEKA - Machine Learning in Java. WEKA (Waikato Environment for Knowledge Analysis) is an open source library for machine learning, bundling lots of techniques from Support Vector Machines to C4.5 Decision Trees in a single Java package.

My examples in this article will be based on binary classification, but what I say is also valid for regression and in many cases for unsupervised learning. Why and when would you use a library? I'm not a fan of integrating libraries and frameworks just because they exist; but machine learning is something where you have to rely on a library if you're using codified algorithms as they're implemented more efficiently than what you and I can possibly code in an afternoon. Efficiency means a lot in machine learning as supervised learning is one of the few programs that is really CPU-bound and can't be optimized further with I/O improvements. 1.J48 classifier = new J48(); 2.classifier.setOptions(new String[] { "-U" }); With respect to: 1.SVM classifier = new SMO(); 3. 01.double targetIndex;
Machine Learning: A Love Story. » Devs Love Bacon: Everything you need to know about Machine Learning in 30 minutes or less hilarymason.com. Hilarymason.com. Courses and Tutorials - Machine Learning Resources. From Machine Learning Resources *Dr. Tom Mitchell, CMU : *Dr. Chris Atkinson, CMU (Old Link) : [1] *Dr. Jude Shavlik, University of Wisconsin: *Dr. Tom Dietterich, Oregon State University: *Dr. This section provides links to various tutorials on machine learning and its sub-fields, which are available online. [ edit ] Tutorials General. Machine Learning in Gradient Descent. In Machine Learning, gradient descent is a very popular learning mechanism that is based on a greedy, hill-climbing approach.
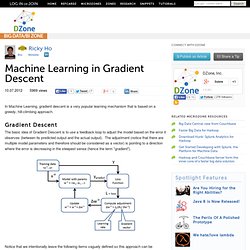
Gradient Descent The basic idea of Gradient Descent is to use a feedback loop to adjust the model based on the error it observes (between its predicted output and the actual output). The adjustment (notice that there are multiple model parameters and therefore should be considered as a vector) is pointing to a direction where the error is decreasing in the steepest sense (hence the term "gradient"). Notice that we intentionally leave the following items vaguely defined so this approach can be applicable in a wide range of machine learning scenarios. Reading and Text Mining a PDF-File in R.
0inShare Here is an R-script that reads a PDF-file to R and does some text mining with it:
GATE.ac.uk - index.html. Apprentissage artificiel : Moyens d’apprendre pour la classification et les regroupements (biais et modèles) Par: Benoît TROUVILLIEZ Introduction La suite de la saga sur la notion d’apprentissage artificiel (que l’on désigne également par apprentissage automatique) appliquée aux tâches de classification et regroupement.

Dans ce volet, nous allons introduire les notions complémentaires de biais et modèles d’apprentissage. Moyens d’apprendre : de la nécessité du biais d’apprentissage… Dans le billet précédent, nous avons vu que les algorithmes d’apprentissage artificiel avait pour but de s’adapter à la résolution d’une tâche au travers d’un protocole d’apprentissage. Pour bien comprendre les enjeux des moyens à employer pour l’apprentissage, nous devons partir de la problématique concrète. Afin d’apprendre à distinguer les deux types de documents, nous devons concrètement apprendre à les séparer, c’est à dire déterminer un séparateur.
=> Lequel de ces séparateurs est meilleur que les autres? Mais revenons pour l’heure à nos différents séparateurs.