
13.6.3 InnoDB Startup Options and System Variables. Linux HugeTLBfs: Improve MySQL Database Application Performance. Applications that perform a lot of memory accesses (several GBs) may obtain performance improvements by using large pages due to reduced Translation Lookaside Buffer (TLB) misses.
HugeTLBfs is memory management feature offered in Linux kernel, which is valuable for applications that use a large virtual address space. It is especially useful for database applications such as MySQL, Oracle and others. Other server software that uses the prefork or similar (e.g. Apache web server) model will also benefit. The CPU's Translation Lookaside Buffer (TLB) is a small cache used for storing virtual-to-physical mapping information. Only selected hardware and operating system support memory pages greater than the default 4KB.
How do I verify that my kernel supports hugepage? Type the following command: $ grep -i huge /proc/meminfo Sample output: Michael Tokarev: Re: O_DIRECT question. Bugs: #40757: server crash after failed plugin/engine initialization. Heikki Tuuri answers to Innodb questions, Part II. I now got answers to the second portions of the questions you asked Heikki.
If you have not seen the first part it can be found here. Same as during last time I will provide my comments for some of the answers under PZ and will use HT for original Heikkis answer. Q26: You also say on Unix/Linux only one read-ahead can happen at the same time. How many read-aheads can be waiting in Queue when or Innodb will schedule more read-aheads only when given read-ahead is completed?
Variable's Day Out #12: innodb_flush_method. Properties: Description: This variable changes the way InnoDB open files and flush data to disk and is should be considered as very important for InnoDB performance.
Linux 64-bit, MySQL, Swap and Memory. The VM for Linux prefers system cache over application memory.
What does this mean? The best way I can explain is by example. Imagine you have 32 GB of RAMMySQL is set to take 20 GB of RAM for a process based buffer and up to 6M for the various thread buffers. Over a period of time the box swaps. Choosing innodb_buffer_pool_size. November 3, 2007 by Peter Zaitsev39 Comments My last post about Innodb Performance Optimization got a lot of comments choosing proper innodb_buffer_pool_size and indeed I oversimplified things a bit too much, so let me write a bit better description.

Innodb Buffer Pool is by far the most important option for Innodb Performance and it must be set correctly. I’ve seen a lot of clients which came through extreme sufferings leaving it at default value (8M). So if you have dedicated MySQL Box and you’re only using Innodb tables you will want to give all memory you do not need for other needs for Innodb Buffer Pool. This of course assumes your database is large so you need large buffer pool, if not – setting buffer pool a bit larger than your database size will be enough. You also may choose to set buffer pool as if your database size is already larger than amount of memory you have – so you do not forget to readjust it later. Evaluating IO subsystem performance for MySQL Needs.
I’m often asked how one can evaluate IO subsystem (Hard drive RAID or SAN) performance for MySQL needs so I’ve decided to write some simple steps you can take to get a good feeling about it, it is not perfect but usually can tell you quite a lot of what you should expect from the system. What I usually look for MySQL is performance in random reads and random writes.
Sequential reads and writes are rarely the problem for OLTP workloads, so we will not look at them. I also prefer to look at performance with O_DIRECT flag set to bypass OS cache. This may execute separate code path in kernel and so has a bit different performance pattern compared to buffered IO (even followed by fsync regularly) , but it allows to easily bypass OS cache both for reads and for writes and so does not require creating large working sets for boxes with significant amounts of memory (or reducing amount of usable memory). To prepare small 128MB single file working set we can use the following command: Data Recovery - Percona. Percona MySQL Consulting can often recover lost or corrupted data from MyISAM and InnoDB tables or from corrupted MySQL binary logs and general query logs.
We have created special data recovery software that can recover data from InnoDB tables to assist with your MySQL restore. If you want to try InnoDB data recovery yourself, see the Percona Data Recovery Tool for InnoDB. These scenarios are often recoverable: Accidentally deleted data in MySQLDropped InnoDB tablesTruncated or recreated MySQL tablesInnoDB tablespace corruption that innodb_force_recovery will not repairMySQL database with a filesystem corruption We always encrypt your sensitive data and we destroy our copy of it after we are done.
Compiling sysbench 0.4.12 for Debian. Home » Bugs, Debian, Featured, How-to, Linux, Shell 9 July 200919 Comments On the Linux market are a lot of distributions and every distribution is unique in his way.

Is normal to have different compilers and tools from distribution to distribution so is almost normal to have programs what doesn’t compile on all distributions. sysbench 0.4.12 is one of them. Accessing Files With O_DIRECT. MySQL Conference from O'Reilly Media. In mid 2006, YouTube served approximately 100 million videos in a single day.

To maintain a website of that scale, one would imagine YouTube has hundreds of DBAs. But in fact, there are just three people that make it all work. Paul Tuckfield, the MySQL DBA at YouTube shares horror stories about scalability at YouTube and how he coped with them to keep the show going everyday, while learning important lessons along the way. YouTube uses MySQL as the back-end. 7.9.8 Enabling Large Page Support. Kernel Korner - I/O Schedulers. Although most Linux users are familiar with the role of process schedulers, such as the new O(1) scheduler, many users are not so familiar with the role of I/O schedulers.
I/O schedulers are similar in some aspects to process schedulers; for instance, both schedule some resource among multiple users. A process scheduler virtualizes the resource of processor time among multiple executing processes on the system. So, what does an I/O scheduler schedule? La mémoire sous Linux : analyse du fichier /proc/meminfo - Sygus.net. Dans cet article, je vais tenter d'expliquer les différentes informations que le noyau Linux nous donne au travers du fichier /proc/meminfo.
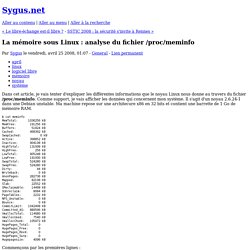
Comme support, je vais afficher les données qui concernent mon système. Il s'agit d'un noyau 2.6.24-1 dans une Debian unstable. Ma machine repose sur une architecure x86 en 32 bits et contient une barrette de 1 Go de mémoire RAM. Commençons par les premières lignes : Sur une architecture x86 32 bits, la mémoire physique est séparée en trois zones. Drop_caches. /proc/sys/vm. Linux System Administrator's Guide - The buffer cache. Linux System Administrators Guide: Prev Chapter 6. Memory Management Next 6.6. The buffer cache Reading from a disk is very slow compared to accessing (real) memory. In addition, it is common to read the same part of a disk several times during relatively short periods of time. Since memory is, unfortunately, a finite, nay, scarce resource, the buffer cache usually cannot be big enough (it can't hold all the data one ever wants to use). The Linux Page Cache and pdflush. As you write out data ultimately intended for disk, Linux caches this information in an area of memory called the page cache.
You can find out basic info about the page cache using tools like free, vmstat or top. See to learn how to interpret top's memory information, or atop to get an improved version. Full information about the page cache only shows up by looking at /proc/meminfo. MySQL Swapping to Disk. Over the past couple of months we've been finding some of our MySQL servers swapping to disk. This behaviour is very unusual because we allocate a lot of memory to every MySQL server and run large caches to ensure the database performs as well as it can. We were finding that MySQL consumes memory up to about 90-95% and then chunks of memory start swapping.
The majority of memory usage is cache, as the swap became active, memory was made available and MySQL would cache more, unfortunately retrieving paged caches then became slow as they were sitting in a page file on disk and not in memory as we expected. We'll detail in this article how we have resolved this after a couple of months of investigating and testing alternative options.
The Environment. 5.1.5 Server Status Variables. 7.4.8 Quand MySQL ouvre et ferme les tables. 7.9.3 Tuning Server Parameters. 7.9.5 How MySQL Uses Memory. 16.1.1 How to Set Up Replication. 16.1.1.3 Creating a User for Replication.