
Replacing jQuery with D3. [tl;dr] You can easily replace jQuery in your visualization projects by using D3-only functions.
When creating visualizations or interactives we often use a combination of jQuery and D3. Mostly we use many of D3's functions and only a small subset of jQuery's for DOM-manipulation. View Project on Github Although D3 has powerful features like its selectors or an ajax wrapper already built-in, we are often times missing some jQuery functions in our D3 projects. That's why we will show some approaches on how you can replace jQuery by only using D3.
Reduced overhead in your visualization projects by removing unused functions.Only loading a single library (smaller size).Not mixing up libraries that are built for different use-cases.Using functions in a D3-like way. To start off, let's have a look at the similarities of D3 and jQuery. Similarities Selectors Both of the libraries are based on sophisticated selector functions that are easy to use. jQuery Attribute and style manipulation Ajax empty() Advanced Topics in Machine Learning (Part 1) Akka samples with scala and Spring. I was looking around recently for Akka samples with Spring and found a starter project which appeared to fit the bill well.
The project however utilizes Spring-Scala which is an excellent project, but is no longer maintained. So I wanted to update the sample to use core Spring java libraries instead. So here is an attempt on a fork of this starter project with core Spring instead of Spring-scala. The code is available here. The project utilizes Akka extensions to hook in Spring based dependency injection into Akka. Here is what the extension looks like: So the extension wraps around a Spring application context. Given this base code, how does Spring find the actors, I have used scanning annotations to annotate the actors this way: Hadoop Training By Tom White - Parleys.com. Top Languages for analytics, data mining, data science. The most popular languages continue to be R (used by 61% of KDnuggets readers), Python (39%), and SQL (37%).
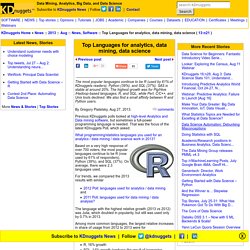
SAS is stable at around 20%. The highest growth was for Pig/Hive/Hadoop-based languages, R, and SQL, while Perl, C/C++, and Unix tools declined. We also find a small affinity between R and Python users. By Gregory Piatetsky, Aug 27, 2013. comments. Islands in the Stream of Extreme Data - Robert Plant. Hadoop Cluster Sizing Guide. Requirement_bigDataLab. Myui/hivemall. Hadoop Backup and Disaster Recovery. QlikTech Unveils Roadmap to Next Generation Business Discovery Platform to Replace Traditional Business Intelligence. Natural Analytics™ delivers actionable intelligence organizations now require Radnor, PA - 25 September 2013 QlikTech, (NASDAQ: QLIK), a leader in user-driven Business Intelligence (BI), today announced the company’s strategic roadmap to once again disrupt the BI industry with its next-generation platform to enable better decision making.

QlikView.Next is designed to expand on QlikTech’s focus of filling the gap between visualization or dashboard solutions and complex BI platforms tied to report-centric ways of doing business. As Business Discovery is being adopted as an alternative BI platform, QlikView.Next will give users the immediate insights they need and IT professionals the enterprise manageability and governance they require. Fundamental to making next-generation BI accessible and useful for a broad range of users is QlikView’s Natural Analytics™ approach, which taps into the natural human ability to process complex information. The Road to QlikView.Next.
Spark and shark. Apache Spark - Lightning-Fast Cluster Computing. Stream Processing in Hadoop: YARN, Storm and the Hortonworks Data Platform. Hortonworks will be making a preview of Apache Storm integration available in Q4 of this year and will be including Apache Storm in the Hortonworks Data Platform in first half of 2014.

Any time now, the Apache Hadoop community will declare the General Availability of Hadoop 2.0 which includes the much anticipated Apache Hadoop YARN. The YARN-based architecture of Hadoop 2 is the most significant change to Hadoop introduced in the past six years and enables Hadoop to expand from a single-purpose, batch-oriented data platform based on MapReduce into a truly multi-purpose platform supporting a wide range of data processing approaches. The general availability of YARN – which in 2.0 essentially becomes the Hadoop Operating System – promises to open up the range of ways Hadoop is used to process data. In fact, one of the most common use cases that we see emerging from our customers is the antithesis of batch: stream processing in Hadoop. Splunk as a Big Data Platform for Developers. Debugging Hadoop Core Dumps. A long time pain point for HubSpot Engineering has been intermittent core dumps with Hadoop jobs.
The issue wasn't destructive; all jobs are idempotent and missing processes are restarted and rerun. Occasionally, however, the resulting queue processing delay would be enough to trigger a PagerDuty alert in the middle of the night. Having tried several times to resolve the issue, engineering was unhappily resigned to living with it -- until our recently-formed SRE team decided to take a shot at resolving the issue. Tl;dr As expected, java is pretty flexible with minor versions in regards to compiling and runtime even with JNI involved.The -Xcheck:jni command line option can cause Hadoop seg faults if native libs are used.Don't use obscure 3rd party libs in production.
Workaround The known workaround was to rename a hadoop directory containing *.so dynamic libraries such that they weren't found upon jvm startup.