
Handling Strings with R. Strex: Extra String Manipulation Functions. There are some things that I wish were easier with the stringr or stringi packages.

The foremost of these is the extraction of numbers from strings. stringr makes you figure out the regex for yourself; strex takes care of this for you. There are many more useful functionalities in strex. In particular, there’s a match_arg() function which is more flexible than the base match.arg(). Contributions to this package are encouraged: it is intended as a miscellany of string manipulation functions which cannot be found in stringi or stringr. The github repo of strex is at Installation You can install the release version of strex from CRAN with: You can install the development version of strex from GitHub with: How to use the package The following articles contain all you need to get going: A bit of benchmarking with string distances.
After my last post about the stringdist package, Zachary Mayer pointed out to me that the implementation of the Levenshtein and Jaro-Winkler distances implemented in the RecordLinkage package are about two-three times faster.
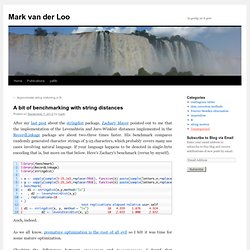
His benchmark compares randomly generated character strings of 5-25 characters, which probably covers many use cases involving natural language. If your language happens to be denoted in single-byte encoding that is, but more on that below. Here's Zachary's benchmark (rerun by myself). Auch, indeed. As we all know, premature optimization is the root of all evil so I felt it was time for some mature optimization. Checking the differences between stringdist and RecordLinkage I found that RecordLinkage uses C code that works directly on the char representation of strings while I designed stringdist to make sure that multibyte characters are treated as a single character. Escape Characters. Frequently Asked Questions on R Version 3.1.2014-04-05 Table of Contents 1 Introduction This document contains answers to some of the most frequently asked questions about R. 1.1 Legalese This document is copyright © 1998–2014 by Kurt Hornik.

This document is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2, or (at your option) any later version. This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. Copies of the GNU General Public License versions are available at. Similiars. Strings in R 4.x vs 3.x (and earlier) Among the several user-facing changes listed in R 4.0.0’s release notes was this point: There is a new syntax for specifying raw character constants similar to the one used in C++: r"(...)

" with ... any character sequence not containing the sequence )". This makes it easier to write strings that contain backslashes or both single and double quotes. For more details see ? Quotes. To get a better sense of this (wonderful) feature addition, I thought it’d be useful to see some before/after examples. Backslashes One of the biggest frustrations when working with strings in R has been backslashes. Stringr.plus. Str_replace(): give `replacement` a function and it applies the function to each match! Ex: turn "1/2" into a decimal. Regular Expressions Every R programmer Should Know. Author: Theo Roe Regular expressions.

How they can be cruel! Well we’re here to make them a tad easier. To do so we’re going to make use of the stringr package install.packages("stringr") library("stringr") We’re going to use the str_detect() and str_subset() functions. From base R. Glue 1.2.0 - Tidyverse. Glue 1.2.0 is now available on CRAN!
Transformers, glue! Package {glue} is designed as “small, fast, dependency free” tools to “glue strings to data in R”.
To put simply, it provides concise and flexible alternatives for paste() with some additional features: library(glue) x <- 10 paste("I have", x, "apples. ") glue("I have {x} apples. ") Recently, fate lead me to try using {glue} in a package. Str_interp - tidyverse - RStudio Community. Glue magic Part I. Tidy Text Mining with R. Edinbr: Text Mining with R. Author: Colin Gillespie During a very quick tour of Edinburgh (and in particular some distilleries), Dave Robinson (Tidytext fame), was able to drop by the Edinburgh R meet-up group to give a very neat talk on tidy text.
The first part of the talk set the scene. Tidytext Tutorials. Recently, we ran our workshop on tidytext.
This is one of the most popular basic text-as-data packages available in R and is a great introductory tool for analyzing English text computationally. One of the benefits of tidytext is that it is easy to use with other packages. Want to analyze Twitter content? Scrape it with rtweets, and then analyze the tweets using tidytext. Interested in analyzing books or news articles instead? Clustering · OpenRefine. How to edit cells by clustering.
OpenRefine's text facets are a great mechanism for surfacing patterns from your data. Consider a data set that contains people's names entered in two different ways: "first_name middle_initial last_name", and "last_name, first_name". A text facet on that column might reveal.