
Compress a PDF with pdftk. How To Extract All Text From PDFs (Including Text In Images) [Ubuntu. The following tutorial will explain how to extract all text from PDFs (including text in images), by using a combination of Ghostscript and a command line OCR tool called tesseract-ocr.
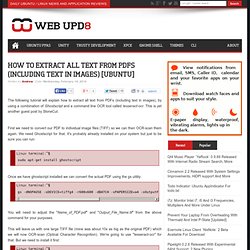
This is yet another guest post by StoneCut. First we need to convert our PDF to individual image files (TIFF) so we can then OCR-scan them again. We need Ghostscript for that. It's probably already installed on your system but just to be sure you can run: sudo apt-get install ghostscript Once we have ghostscript installed we can convert the actual PDF using the gs utility: PDF Data Extraction In Linux. This is a tip sent by WebUpd8 reader Stone Cut, on extracting images and text from PDF files.
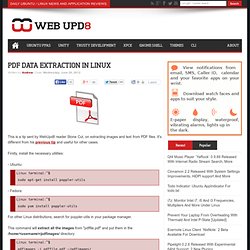
It's different from his previous tip and useful for other cases. Firstly, install the necessary utilities: - Ubuntu: sudo apt-get install poppler-utils - Fedora: sudo yum install poppler-utils For other Linux distributions, search for poppler-utils in your package manager. This command will extract all the images from "pdffile.pdf" and put them in the /home/<username>/pdfimages/ directory: pdfimages -j pdffile.pdf ~/pdfimages/ The JPEG files will be saved with PPM extension with pdfimages unless you specify the "-j" (for JPEG) parameter. The advantage of pdfimages is that it will extract the original images as embedded in the PDF - For example: I extracted a PDF from our local kindergarten so I could use some images for an invitation and I was quite surprised to find out that the embedded image was much larger and showed much more of the photo when extracted than when embedded.
MuPDF. PDFMiner. Last Modified: Mon Mar 24 12:02:47 UTC 2014 Python PDF parser and analyzer Homepage Recent Changes PDFMiner API What's It?

PDFMiner is a tool for extracting information from PDF documents. Unlike other PDF-related tools, it focuses entirely on getting and analyzing text data. Features Written entirely in Python. PDFMiner is about 20 times slower than other C/C++-based counterparts such as XPdf. Online Demo: (pdf -> html conversion webapp) Download Source distribution: github: Where to Ask Questions and comments: How to Install Install Python 2.4 or newer.
For CJK languages In order to process CJK languages, you need an additional step to take during installation: # make cmap python tools/conv_cmap.py pdfminer/cmap Adobe-CNS1 cmaprsrc/cid2code_Adobe_CNS1.txt reading 'cmaprsrc/cid2code_Adobe_CNS1.txt'... writing 'CNS1_H.py'... ... On Windows machines which don't have make command, paste the following commands on a command line prompt: Command Line Tools pdf2txt.py Examples Options. Compact PDF Specification - Iceweasel. Compact PDF is a new format that can give an additional compression of 30 to 60% on many classes of PDF beyond what is possible in PDF 1.5.

For instance, the PDF Reference 1.5 shrinks from 12.2MB as distributed by Adobe down to 4.4MB in Compact format. See Compress results to see what compression ratios one tool is able to achieve with this format. PDFs can be re-compressed with a free tool to achieve smaller sizes in Compact format. Compact PDF is presently supported by the Multivalent Browser and the Multivalent PDF Tools. Compact PDF is not directly supported by Acrobat, but that same tool can convert back to standard PDF whenever needed. Overview PDFs are compressed internally, but for various reasons they are often not as small as they could be.
Bulk compression of most objects in same stream. PDF Specification - Iceweasel. PDF Reference and Adobe Extensions to the PDF Specification. The PDF Reference was first published when Adobe Acrobat was introduced in 1993.
Since then, updated versions of the PDF Reference have been made available from Adobe via the Web, and from time to time, in traditional paper documents made available from book publishers. On January 29, 2007, Adobe announced its intent to release the full Portable Document Format (PDF) 1.7 specification to AIIM, the Enterprise Content Management Association, for the purpose of publication by the International Organization for Standardization (ISO). During 2007 and into early 2008 that intent was turned into a reality.