
Algorithms, 4th Edition by Robert Sedgewick and Kevin Wayne.
Home Page - www.socher.org. Deep-learning « Deep Learning. Yann LeCun posted links for the NIPS 2012 deep learning related talks.
You can reach his post [...] The Chinese Internet company will set up its Institute of Deep Learning later this year to focus its research on developing and enhancing its current web services via deep learning techniques. Source: ZD-Net Emerging [...] ICLR 2013 in conjunction with AISTATS 2013, Scottsdale, Arizona, May 2nd-4th 2013 Submission deadline: January 15th 2013 One can submit a short-workshop like paper (not considered a publication) or a longer paper considered for publication in the ICLR proceedings or in a JMLR special issue. NPR’s Onpoint radio program interviewed Yann LeCun & Peter Norvig interviewed on NPR, on AI and deep learning. [1] On Point: Artificial intelligence, Big Data, and deep learning, 29 [...] A recent article written by John Markoff for New York Times raised the interest in deep learning algorithms[1] by the general audience.
. [2] The New Yorker, Is deep [...] Text Classification for Sentiment Analysis – NLTK + Scikit-Learn. Now that NLTK versions 2.0.1 & higher include the SklearnClassifier (contributed by Lars Buitinck), it's much easier to make use of the excellent scikit-learn library of algorithms for text classification.
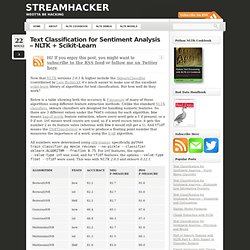
But how well do they work? Below is a table showing both the accuracy & F-measure of many of these algorithms using different feature extraction methods. Unlike the standard NLTK classifiers, sklearn classifiers are designed for handling numeric features. So there are 3 different values under the feats column for each algorithm. bow means bag-of-words feature extraction, where every word gets a 1 if present, or a 0 if not. int means word counts are used, so if a word occurs twice, it gets the number 2 as its feature value (whereas with bow it would still get a 1). And tfidf means the TfidfTransformer is used to produce a floating point number that measures the importance of a word, using the tf-idf algorithm.
Like this: Like Loading... 10-709 Read the Web. Fall 2009. Lecture 12: Information Extraction. General idea: To leverage the redundancy of the web against the difficulty of natural language interpretation.

Somebody somewhere will have stated the fact you want in a form that your program can recognize. Entity extraction in targeted categories. Targeted relation extraction. Open information extraction. Theory extraction Extracting verb relations Extracting synonyms NLP Tools OpenNLP Tokenizing Sentence splitting Stemming/Lemmatizing Part of speech tagging Named-entity recognition. The more sophisticated forms of analysis obviously give richer information.
KnowItAll (Etzioni et al.) Web-scale Information Extraction in KnowItAll (preliminary results) Oren Etzioni et al., WWW 2004. Task: To collect as many instances as possible of various categories. General bootstrapping algorithm: Danger: Semantic drift (once some irrelevant example has been introduced, it builds on itself.) Domain-independent extractor and assessor rules. Extractor rule: E.g. List extractor rules. Data-Intensive Text Processing with MapReduce. Statistics 260: Lecture Notes. UFLDL Tutorial - Ufldl.