
Statistics Used by the Query Optimizer in Microsoft SQL Server 2005. By Author: Eric N.

Hanson, Contributor: Lubor Kollar Microsoft® SQL Server™ 2005 collects statistical information about indexes and column data stored in the database. These statistics are used by the SQL Server query optimizer to choose the most efficient plan for retrieving or updating data. This paper describes what data is collected, where it is stored, and which commands create, update, and delete statistics. By default, SQL Server 2005 also creates and updates statistics automatically, when such an operation is considered to be useful. Deploying SSDT Projects with TFS Build. As many of you probably have noticed by now, Visual Studio Database Projects are not supported in the next version of Visual Studio (currently named Visual Studio 11 Beta).
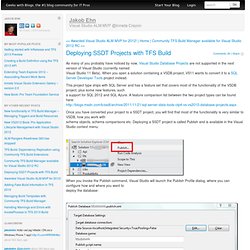
When you open a solution containing a VSDB project, VS11 wants to convert it to a SQL Server Developer Tools project instead. This project type ships with SQL Server and has a feature set that covers most of the functionality of the VSDB project, plus some new features, such a support for SQL 2012 and SQL Azure. A feature comparison list between the two project types can be found here: Once you have converted your project to a SSDT project, you will find that most of the functionality is very similar to VSDB, how you work with schema objects, schema comparisons etc. Deploying a SSDT project is called Publish and is available in the Visual Studio context menu: When you invoke the Publish command, Visual Studio will launch the Publish Profile dialog, where you can configure how and where you want to deploy the database:
SQL Server Index and Statistics Maintenance. IndexOptimize is the SQL Server Maintenance Solution’s stored procedure for rebuilding and reorganizing indexes and updating statistics.

IndexOptimize is supported on SQL Server 2005, SQL Server 2008, SQL Server 2008 R2, SQL Server 2012, and SQL Server 2014. Download Download MaintenanceSolution.sql. This script creates all the objects and jobs that you need. You can also download the objects as separate scripts. Splitting Strings : Now with less T-SQL. Some interesting discussions always evolve around the topic of splitting strings.
In two previous blog posts, "Split strings the right way – or the next best way" and "Splitting Strings : A Follow-Up," I hope I have demonstrated that chasing the "best-performing" T-SQL split function is fruitless. When splitting is actually necessary, CLR always wins, and the next best option can vary depending on the actual task at hand. But in those posts I hinted that splitting on the database side may not be necessary in the first place. The Tests For this test I'm going to pretend we are dealing with a set of version strings. CREATE TABLE dbo.VersionStrings(left_post NVARCHAR(5), right_post NVARCHAR(5)); CREATE CLUSTERED INDEX x ON dbo.VersionStrings(left_post, right_post); ;WITH x AS ( SELECT lp = CONVERT(DECIMAL(4,3), RIGHT(RTRIM(s1. SQL Server Master Data Services. Master Data Services. Master Data Services (MDS) is the SQL Server solution for master data management.
Master data management (MDM) describes the efforts made by an organization to discover and define non-transactional lists of data, with the goal of compiling maintainable master lists. An MDM project generally includes an evaluation and restructuring of internal business processes along with the implementation of MDM technology. The result of a successful MDM solution is reliable, centralized data that can be analyzed, resulting in better business decisions.
With the right training, most business users should be able to implement a Master Data Services solution. In addition, you can use MDS to manage any domain; it's not specific to managing lists of customers, products, or accounts. Other Master Data Services features include hierarchies, granular security, transactions, data versioning, and business rules. Normal Stuff - Paul White: Page Free Space : Undocumented Query Plans: Equality Comparisons. The diagram below shows two data sets, with differences highlighted: To find changed rows using TSQL, we might write a query like this: The logic is clear: join rows from the two sets together on the primary key column, and return rows where a change has occurred in one or more data columns.
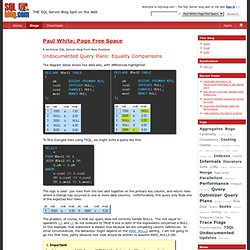
Unfortunately, this query only finds one of the expected four rows: The problem, of course, is that our query does not correctly handle NULLs. The ‘not equal to’ operators <> and ! SQL Indexing tutorial for MySQL, Oracle, SQL Server, PostgreSQL, … How to transpose table(change columns to rows). One of most discussed question about TSQL algorithms is „How to transpose (change columns into rows) a table?” Most solutions based on static code which is adapted to your table.
For every table, you need to write different code. Some authors propose using PIVOT statement, but it is not very handy to use this because PIVOT uses rows aggregation so avoiding this is always so easy. Another question is "What if i need not only data change but gets columns/rows names too?” I you read my previous posts so you know which method we will use: XML-based.This is how it looks:
Optimising Server-Side Paging - Part II. Introduction In part I of this series, we looked at an optimisation that is useful when paging through a wide data set. This part examines four methods commonly employed to return the total number of rows available, at the same time as returning the single page of rows needed for display. Each tested method works correctly; the focus of this article is to identify the performance characteristics of each method, and explore the reasons for those differences.
Free SQL Tuning and Indexing e-book Download. Phil Factor's Phrenetic Phoughts : Listing common SQL Code Smells. Once you’ve done a number of SQL Code-reviews, you’ll know those signs in the code that all might not be well.
These ’Code Smells’ are coding styles that don’t directly cause a bug, but are indicators that all is not well with the code. . Kent Beck and Massimo Arnoldi seem to have coined the phrase in the “OnceAndOnlyOnce” page of www.C2.com, where Kent also said that code “wants to be simple”. Bad Smells in Code was an essay by Kent Beck and Martin Fowler, published as Chapter 3 of the book ‘Refactoring: Improving the Design of Existing Code’ (ISBN 978-0201485677) Although there are generic code-smells, SQL has its own particular coding habits that will alert the programmer to the need to re-factor what has been written.
Disable AutoRecover in Microsoft SQL Server Management Studio. Change Data Capture.
SSIS Related. Table Value Constructor (Transact-SQL) Specifies a set of row value expressions to be constructed into a table.
The Transact-SQL table value constructor allows multiple rows of data to be specified in a single DML statement. The table value constructor can be specified in the VALUES clause of the INSERT statement, in the USING <source table> clause of the MERGE statement, and in the definition of a derived table in the FROM clause. Transact-SQL Syntax Conventions Introduces the row value expression lists. Each list must be enclosed in parentheses and separated by a comma. VALUES() and Long Parameter Lists. To make progress as a relational Database programmer, you have to think in terms of sets, rather than lists, arrays or sequential data.
Until that point, you'll feel the need to pass lists, arrays and the like to functions and procedures. Joe suggests some unusual ways around the difficulty and broods on the power of the VALUES constructor. The original idea of SQL and RDBMS was that all you need to model data is the table. This is a set-oriented approach to data which falls naturally into declarative programming.
Sets are defined by intention or by extension.