
Εxodus. BLAST: Basic Local Alignment Search Tool. Human Genome Resources at NCBI - NCBI. Copie de ensemble. “Fake news” et désinformation autour du coronavirus SARS-CoV2. ©M.Rosa-Calatrava/O.Terrier/A.Pizzorno/E.Errazuriz-cerda Comme tous les sujets médiatiquement forts, le coronavirus SARS-CoV2 de 2019 n’échappe pas au sillon de la désinformation.
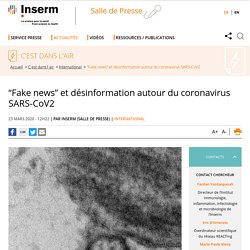
Apparu dans la province chinoise du Hubei, l’épidémie provoquée par ce coronavirus – appelé désormais SARS-CoV2 et COVID-19 pour la maladie qu’il entraîne chez le patient–continue d’alimenter les médias, mais aussi le web et les réseaux sociaux, parfois dans de mauvaises directions. L’Inserm vous propose de revenir sur les différentes formes que prend cette vague de désinformation afin de couper court aux fausses informations et mieux se repérer sur l’océan médiatique. Communiqué de presse INSERM. Carte des provinces chinoises affectées par l’épidémie, colorées en fonction du nombre de cas du virus, au 27 janvier 2020.

Crédits Vittoria Colizza L’Inserm est signataire de la déclaration internationale suivante, émise par le Wellcome Trust[1] : Partager les données et les résultats de la recherche concernant l’épidémie de nouveau coronavirus (nCoV) L’apparition du nouveau coronavirus en Chine (2019-nCoV) représente une menace importante et urgente pour la santé mondiale. Novel Coronavirus (COVID-19) Malaria cases per 100,000 people in Kenya - Malaria cases per 100000 people in Kenya per county.xlsx - Humanitarian Data Exchange. Un déluge de données. Dans de nombreux domaines, scientifiques ou non, les données s’accumulent en masse.
Les gérer et les exploiter est le défi posé à l’informatique du Big Data. Au CERN, près de Genève, le collisionneur LHC (Large Hadron Collider) est équipé d’énormes détecteurs capables d’enregistrer les traces de dizaines à centaines de millions de collisions proton-proton par seconde. Évaluons grossièrement le volume de données que cela représente, en faisant des hypothèses basses. L’information relative aux produits de chaque collision est représentée à l’aide de quatre octets (soit (28)4 = 2564 = 4,3 milliards de possibilités), l’accélérateur fonctionne dix heures par jour en moyenne, et 100 millions de collisions sont enregistrées chaque seconde. On calcule facilement qu’au bout d’un an, le LHC produit ainsi 5 × 1015 octets, soit cinq pétaoctets d’information (une évaluation plus précise fournit des valeurs supérieures). Mais il en faut également pour des applications plus quotidiennes.
Définition : Qu’est-ce que le Big Data ? - LeBigData.fr. Le phénomène Big Data L’explosion quantitative des données numériques a obligé les chercheurs à trouver de nouvelles manières de voir et d’analyser le monde.
Il s’agit de découvrir de nouveaux ordres de grandeur concernant la capture, la recherche, le partage, le stockage, l’analyse et la présentation des données. Ainsi est né le « Big Data ». Il s’agit d’un concept permettant de stocker un nombre indicible d’informations sur une base numérique. Selon les archives de la bibliothèque numérique de l’Association for Computing Machinery (ou ACM) dans des articles scientifiques concernant les défis technologiques à relever pour visualiser les « grands ensembles de données », cette appellation est apparue en octobre 1997.
Le Big Data, c’est quoi ? Les 5 grands défis de la Big Data. Publié le 19 mai 2014 Prendre la data à bras le corps, c’est comprendre sa raison d’être et maitriser ses arcanes.

Et parce que nous n’en sommes qu’à la genèse, il est bon de débuter directement avec les bonnes bases… Promesse d’un monde meilleur, « smart », efficace, où le hasard n’aurait presque plus sa place pour les uns. Do Not Track – S01E05. Donnez-moi des données ordonnées - Manipuler l'information. Récapitulons un peu.

Nous avons donc appris dans les parties précédentes qu’on pouvait tout coder en binaire, des sons aux images en passant par le texte et les nombres. Nous savons aussi qu’on peut en général s’arranger pour gagner plein de place (et donc stocker plus de choses dans le même espace), et que si on veut se protéger contre la perte d’informations on peut ajouter de la redondance afin de détecter, voire même de corriger, une ou plusieurs erreurs. Du coup ça nous permet de stocker plein de choses, de les réutiliser et même de les partager… à condition qu’elles soient bien structurées et bien rangées. Euh oui justement, en pratique comment je m’y retrouve, moi, dans toutes ces données ?
Eh bien tout d’abord, comme dans un livre, il va y avoir dans votre ordinateur une sorte de table des matières, qui va vous dire où est stocké chaque fichier dans la mémoire. Earthquakes - Earthquake today - Latest Earthquakes in the World - EMSC. Données anonymes… bien trop faciles à identifier. Téléphones, ordinateurs, cartes de crédit, dossiers médicaux, montres connectées, ou encore assistants virtuels : chaque instant de nos vies – en ligne et hors ligne – produit des données personnelles, collectées et partagées à grande échelle.
Nos comportements, nos modes de vie, s’y lisent facilement. Mais faut-il s’en inquiéter ? Après tout, ces données qui nous révèlent sont souvent anonymisées par les organismes qui les collectent.