
Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase vs Couchbase vs Hypertable vs ElasticSearch vs Accumulo vs VoltDB vs Scalaris comparison. (Yes it's a long title, since people kept asking me to write about this and that too :) I do when it has a point.)

While SQL databases are insanely useful tools, their monopoly in the last decades is coming to an end. And it's just time: I can't even count the things that were forced into relational databases, but never really fitted them. (That being said, relational databases will always be the best for the stuff that has relations.) But, the differences between NoSQL databases are much bigger than ever was between one SQL database and another. This means that it is a bigger responsibility on software architects to choose the appropriate one for a project right at the beginning. In this light, here is a comparison of Open Source NOSQL databases Cassandra, Mongodb, CouchDB, Redis, Riak, RethinkDB, Couchbase (ex-Membase), Hypertable, ElasticSearch, Accumulo, VoltDB, Kyoto Tycoon, Scalaris, OrientDB, Aerospike, Neo4j and HBase: The most popular ones Redis (V3.2) Cassandra (2.0) MongoDB (3.2)
The Log: What every software engineer should know about real-time data's unifying abstraction. I joined LinkedIn about six years ago at a particularly interesting time.
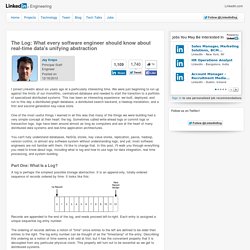
We were just beginning to run up against the limits of our monolithic, centralized database and needed to start the transition to a portfolio of specialized distributed systems. This has been an interesting experience: we built, deployed, and run to this day a distributed graph database, a distributed search backend, a Hadoop installation, and a first and second generation key-value store. One of the most useful things I learned in all this was that many of the things we were building had a very simple concept at their heart: the log. Sometimes called write-ahead logs or commit logs or transaction logs, logs have been around almost as long as computers and are at the heart of many distributed data systems and real-time application architectures.
NoSQL. E/startups-should-use-relational-database.html. Article #1 — December 21, 2013 One of the main goals of a startup is to find a market with a problem and to create a solution that solves that problem.
This is a hard process. A lot of your time will be spent learning about your (potential) customers. Once you have discovered a market need, the next thing to do is create the simplest solution that solves that problem. This is when you must make some simple yet important decisions about your early development process. In a startup, technical decisions must be made quickly. There are a lot of databases to choose from now a days. So what does “databases are hard” and the startups choice of their primary database have to do with each other? After you have discovered a market need and implemented your initial prototype (MVP), your database will become increasingly important for one thing: validating hypothesize. At some point, you will need to ask your primary database questions. NoSQL Development speed is a trickier subject. Schemaless. BigQueryTechnicalWP. Storing Hierarchical Data in a Database Article.
Now, let’s have a look at another method for storing trees.
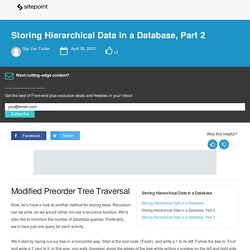
Recursion can be slow, so we would rather not use a recursive function. We’d also like to minimize the number of database queries. Preferably, we’d have just one query for each activity. We’ll start by laying out our tree in a horizontal way. Start at the root node (‘Food’), and write a 1 to its left. We’ll call these numbers left and right (e.g. the left value of ‘Food’ is 1, the right value is 18). Before we continue, let’s see how these values look in our table: Note that the words ‘left’ and ‘right’ have a special meaning in SQL.
Retrieve the Tree If you want to display the tree using a table with left and right values, you’ll first have to identify the nodes that you want to retrieve. SELECT * FROM tree WHERE lft BETWEEN 2 AND 11; That returns: Well, there it is: a whole tree in one query. SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC; The only problem left is the indentation. <? The Path to a Node.