
1406. 1409. LSTM Networks for Sentiment Analysis — DeepLearning 0.1 documentation. In a traditional recurrent neural network, during the gradient back-propagation phase, the gradient signal can end up being multiplied a large number of times (as many as the number of timesteps) by the weight matrix associated with the connections between the neurons of the recurrent hidden layer.

This means that, the magnitude of weights in the transition matrix can have a strong impact on the learning process. If the weights in this matrix are small (or, more formally, if the leading eigenvalue of the weight matrix is smaller than 1.0), it can lead to a situation called vanishing gradients where the gradient signal gets so small that learning either becomes very slow or stops working altogether. Лучшие 10 бесплатных инструментов, о которых должен знать каждый педагогический дизайнер. Автор The knowbly™ Team Время чтения 5мин Большой список бесплатных шаблонов сценариев eLearning от eLearning Industry Исчерпывающий бесплатный список шаблонов сценариев для электронного обучения Одним из первых шагов в большинстве учебных проектов является создание истории.
На этом этапе дизайнеры создают документ для отправки другим заинтересованным сторонам проекта, таким как предметные эксперты (SMEs), в котором излагается содержание и описываются взаимодействия электронного обучения. Nltk.translate package — NLTK 3.4.3 documentation. Nltk.translate.api module class nltk.translate.api.AlignedSent(words, mots, alignment=None)[source] Bases: object Return an aligned sentence object, which encapsulates two sentences along with an Alignment between them.
Typically used in machine translation to represent a sentence and its translation. >>> from nltk.translate import AlignedSent, Alignment>>> algnsent = AlignedSent(['klein', 'ist', 'das', 'Haus'],... Parameters. Moses - FactoredTraining/PrepareData. The parallel corpus has to be converted into a format that is suitable to the GIZA++ toolkit.
Two vocabulary files are generated and the parallel corpus is converted into a numberized format. The vocabulary files contain words, integer word identifiers and word count information: ==> corpus/de.vcb <== 1 UNK 0 2 , 928579 3 . 723187 4 die 581109 5 der 491791 6 und 337166 7 in 230047 8 zu 176868 9 den 168228 10 ich 162745 ==> corpus/en.vcb <== 1 UNK 0 2 the 1085527 3 . 714984 4 , 659491 5 of 488315 6 to 481484 7 and 352900 8 in 330156 9 is 278405 10 that 262619. Your Python Trinket. Project Jupyter. LlSourcell/tensorflow_chatbot: Tensorflow chatbot demo by @Sirajology on Youtube.
Kite. Alignment. 2012 01 30 0404739. Inf8225_lm.pdf. Python - Text Translation. Is13/elman.py at master · mesnilgr/is13. Нейронный машинный перевод с применением GPU. Часть 3. Автор оригинальной публикации: Киунхьюн Чо (Kyunghyun Cho) В предыдущей статье мы рассмотрели простую модель для машинного перевода типа кодер-декодер (encoder-decoder model).
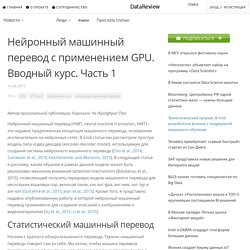
Эта модель превосходно переводит с английского на французский. В то же время она имеет свой недостаток, о котором мы поговорим в этой статье. Также я расскажу вам, как с помощью механизма внимания (attention mechanism) можно преодолеть этот недостаток и значительно повысить качество перевода. Нейронный машинный перевод с применением GPU. Часть 2. Автор оригинальной публикации: Киунхьюн Чо (Kyunghyun Cho) В предыдущей статье мы рассмотрели статистический машинный перевод и выяснили, что он может и должен рассматриваться, как машинное обучение с учителем, при котором вход и выход являются последовательностями переменной длины.
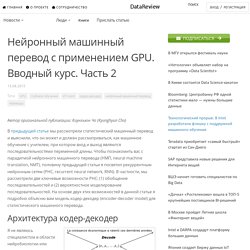
Нейронный машинный перевод с применением GPU. Часть 1. Автор оригинальной публикации: Киунхьюн Чо (Kyunghyun Cho) Нейронный машинный перевод (НМП, neural machine translation, NMT) – это недавно предложенная концепция машинного перевода, основанная исключительно на нейронных сетях.
В этой статье мы рассмотрим простую модель типа кодер-декодер (encoder-decoder model), используемую для создания системы нейронного машинного перевода [Cho et al., 2014; Sutskever et al., 2014; Kalchbrenner and Blunsom, 2013]. В следующей статье я расскажу, каким образом в рамках данной модели может быть реализован механизм внимания (attention mechanism) [Bahdanau et al., 2015], позволяющий получить передовую модель машинного перевода для нескольких языковых пар, включая такие, как анг-фра, анг-нем, анг-тур и анг-кит [Gulcehre et al., 2015; Jean et al., 2015]. Нейронный машинный перевод с применением GPU. Часть 3. [1409.1259] On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. Как написать игру на Python3. Нейронный машинный перевод Google. Microsoft Translator launching Neural Network based translations for all its speech languages - Microsoft Translator Blog. OpenNMT - Open-Source Neural Machine Translation. For Parents - Education - Microsoft Translator. Википедия — свободная энциклопедия.
Книга «Прикладной анализ текстовых данных на Python» / Блог компании Издательский дом «Питер» Технологии анализа текстовой информации стремительно меняются под влиянием машинного обучения.
Нейронные сети из теоретических научных исследований перешли в реальную жизнь, и анализ текста активно интегрируется в программные решения. Нейронные сети способны решать самые сложные задачи обработки естественного языка, никого не удивляет машинный перевод, «беседа» с роботом в интернет-магазине, перефразирование, ответы на вопросы и поддержание диалога.
Почему же Сири, Алекса и Алиса не хотят нас понимать, Google находит не то, что мы ищем, а машинные переводчики веселят нас примерами «трудностей перевода» с китайского на албанский? Ответ кроется в мелочах – в алгоритмах, которые правильно работают в теории, но сложно реализуются на практике. Научитесь применять методы машинного обучения для анализа текста в реальных задачах, используя возможности и библиотеки Python. О чем рассказывается в этой книге Кому адресована эта книга Отрывок. Извлечение графа из текста — сложная задача. Об авторах. (DOC) Диплом Машинный перевод.