
Guide to an in-depth understanding of logistic regression. When faced with a new classification problem, machine learning practitioners have a dizzying array of algorithms from which to choose: Naive Bayes, decision trees, Random Forests, Support Vector Machines, and many others.

Where do you start? For many practitioners, the first algorithm they reach for is one of the oldest in the field: logistic regression. Here are just a few of the attributes of logistic regression that make it incredibly popular: it's fast, it's highly interpretable, it doesn't require input features to be scaled, it doesn't require any tuning, it's easy to regularize, and it outputs well-calibrated predicted probabilities. But despite its popularity, it is often misunderstood. Simple guide to confusion matrix terminology. March 25, 2014 · machine learning A confusion matrix is a table that is often used to describe the performance of a classification model (or "classifier") on a set of test data for which the true values are known.

The confusion matrix itself is relatively simple to understand, but the related terminology can be confusing. I wanted to create a "quick reference guide" for confusion matrix terminology because I couldn't find an existing resource that suited my requirements: compact in presentation, using numbers instead of arbitrary variables, and explained both in terms of formulas and sentences. Let's start with an example confusion matrix for a binary classifier (though it can easily be extended to the case of more than two classes): What can we learn from this matrix? There are two possible predicted classes: "yes" and "no". Let's now define the most basic terms, which are whole numbers (not rates): I've added these terms to the confusion matrix, and also added the row and column totals:
Approaching (Almost) Any Machine Learning Problem. Abhishek Thakur, a Kaggle Grandmaster, originally published this post here on July 18th, 2016 and kindly gave us permission to cross-post on No Free Hunch An average data scientist deals with loads of data daily.
Some say over 60-70% time is spent in data cleaning, munging and bringing data to a suitable format such that machine learning models can be applied on that data. This post focuses on the second part, i.e., applying machine learning models, including the preprocessing steps. Recsys14. Social networking and recommendation systems. Due: at 9pm on Friday, February 1.
Submit via this turnin page. When you sign into Facebook, it suggests friends. In this assignment, you will write a program that reads Facebook data and makes friend recommendations. This assignment looks longer than it actually is. Part 1 is background material and explanations; there is nothing to turn in for this part, though you do need to complete the NetworkX tutorial. First, download and unzip the file homework4.zip. What are some good resources to learn data mining and data scraping from websites using Python? - Quora.
HTML Scraping. Web Scraping Web sites are written using HTML, which means that each web page is a structured document. Sometimes it would be great to obtain some data from them and preserve the structure while we’re at it. Web sites don’t always provide their data in comfortable formats such as csv or json. The Anatomy of a Search Engine. Sergey Brin and Lawrence Page {sergey, page}@cs.stanford.edu Computer Science Department, Stanford University, Stanford, CA 94305 Abstract In this paper, we present Google, a prototype of a large-scale search engine which makes heavy use of the structure present in hypertext.

The Ancient Art of the Numerati. Learning a Personalized Homepage. By Chris Alvino and Justin Basilico As we’ve described in our previous blog posts, at Netflix we use personalization extensively and treat every situation as an opportunity to present the right content to each of our over 57 million members.
The main way a member interacts with our recommendations is via the homepage, which they see when they log into Netflix on any supported device. The primary function of the homepage is to help each member easily find something to watch that they will enjoy. Recommending for the World. #AlgorithmsEverywhere The Netflix experience is driven by a number of Machine Learning algorithms: personalized ranking, page generation, search, similarity, ratings, etc.
On the 6th of January, we simultaneously launched Netflix in 130 new countries around the world, which brings the total to over 190 countries. Distributed Time Travel for Feature Generation. We want to make it easy for Netflix members to find great content to fulfill their unique tastes.
To do this, we follow a data-driven algorithmic approach based on machine learning, which we have described in past posts and other publications. We aspire to a day when anyone can sit down, turn on Netflix, and the absolute best content for them will automatically start playing. A Neural Network Playground. Um, What Is a Neural Network?
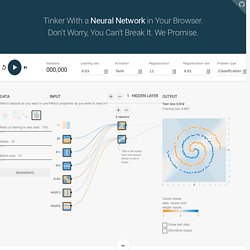
It’s a technique for building a computer program that learns from data. It is based very loosely on how we think the human brain works. First, a collection of software “neurons” are created and connected together, allowing them to send messages to each other. Next, the network is asked to solve a problem, which it attempts to do over and over, each time strengthening the connections that lead to success and diminishing those that lead to failure.
5 Skills You Need to Become a Machine Learning Engineer. Interested in Machine Learning?
You are not alone! More people are getting interested in Machine Learning every day. In fact, you’d be hard pressed to find a field generating more buzz these days than this one. Machine Learning’s inroads into our collective consciousness have been both history making (as when AlphaGo won 4 of 5 Go matches against the world’s best Go player!) Neural Networks Demystified [Part 3: Gradient Descent]
Pattern Mining: Extracting Value from Log Data. The CrunchBase Unicorn Leaderboard. Past, present, and future of Recommender Systems: an industry perspec… Xavier Amatriain, VP of Engineering, Quora @ MLconf SF. Barcelona ML Meetup - Lessons Learned. Overview. The Notebook is the place for all your needs Data Ingestion Data Discovery Data Analytics Data Visualization & Collaboration Multiple language backend Zeppelin interpreter concept allows any language/data-processing-backend to be plugged into Zeppelin.
Currently Zeppelin supports many interpreters such as Scala(with Apache Spark), Python(with Apache Spark), SparkSQL, Hive, Markdown and Shell. Adding new language-backend is really simple. Apache Spark integration Zeppelin provides built-in Apache Spark integration. Zeppelin's Spark integration provides Automatic SparkContext and SQLContext injectionRuntime jar dependency loading from local filesystem or maven repository. Data visualization Some basic charts are already included in Zeppelin. Pivot chart With simple drag and drop Zeppelin aggeregates the values and display them in pivot chart. Learn more about Zeppelin's Display system. ( text, html, table, angular )
IT Shared: Naive Bayes on Apache Flink. In this blog post we are going to implement a Naive Bayes classifier in Apache Flink. We are going to use it for text classification by applying it to the 20 Newsgroup dataset. To understand what is going on, you should be familiar with Java and know what MapReduce is. If you have seen and understood a word count example in any system, you're good to go. If you haven't heard of MapReduce or haven't seen the word count, you may first have a look at our introductory post "Hadoop and MapReduce". Machine Learning Course - CS 156. District Data Labs - An Introduction to Machine Learning with Python.
An Introduction to Machine Learning with Python Rebecca Bilbro The impulse to ingest more data is our first and most powerful instinct. Born with billions of neurons, as babies we begin developing complex synaptic networks by taking in massive amounts of data - sounds, smells, tastes, textures, pictures. It's not always graceful, but it is an effective way to learn. As data scientists, the trick is to encode similar learning instincts into applications, banking more on the volume of data that will flow through the system than on the elegance of the solution (see also these discussions of the Netflix prize and the "unreasonable effectiveness of data").
Fortunately Python and high level libraries like Scikit-learn, NLTK, PyBrain, Theano, and MLPy have made machine learning a lot more accessible than it would be otherwise. Lin Kolcz SIGMOD2012. 35179. Notebook Viewer. Before we start modeling, see what you can figure out just by looking at the chart above. Collection of Machine Learning Interview Questions. The Machine Learning part of the interview is usually the most elaborate one. That’s the reason we have dedicated a complete post to the interview questions from ML. A Huge List of Machine Learning And Statistics Repositories. GitHub - jdwittenauer/ipython-notebooks: A collection of IPython notebooks covering various topics. Stanford University CS231n: Convolutional Neural Networks for Visual Recognition. (The syllabus for the (previous) Winter 2015 class offering has been moved here.) Unless otherwise specified the course lectures and meeting times are Monday, Wednesday 3:00-4:20, Bishop Auditorium in Lathrop Building (map) Update: The class has ended!
Notebook Viewer. GitHub - cs109/2015lab3. Forbes Welcome. Statistical Learning. Ranjan Kumar. The Netflix Recommender System. The New Methodology. In the past few years there's been a blossoming of a new style of software methodology - referred to as agile methods. Alternatively characterized as an antidote to bureaucracy or a license to hack they've stirred up interest all over the software landscape. In this essay I explore the reasons for agile methods, focusing not so much on their weight but on their adaptive nature and their people-first orientation.
Probably the most noticeable change to software process thinking in the last few years has been the appearance of the word 'agile'. We talk of agile software methods, of how to introduce agility into a development team, or of how to resist the impending storm of agilists determined to change well-established practices. This new movement grew out of the efforts of various people who dealt with software process in the 1990s, found them wanting, and looked for a new approach to software process.
Tracking Movers & Shakers: Tackling Human Resources News Classification. A Neural Network in 13 lines of Python (Part 2 - Gradient Descent) - i am trask. Linear regression (2): Gradient descent. An Introduction to Gradient Descent and Linear Regression. Gradient descent is one of those “greatest hits” algorithms that can offer a new perspective for solving problems. Unfortunately, it’s rarely taught in undergraduate computer science programs.
Machine Learning at Quora - Engineering at Quora - Quora. Programming Challenges. Machine Learning for Developers by Mike de Waard. Most developers these days have heard of machine learning, but when trying to find an 'easy' way into this technique, most people find themselves getting scared off by the abstractness of the concept of Machine Learning and terms as regression, unsupervised learning, Probability Density Function and many other definitions. Welcome to Bokeh — Bokeh 0.10.0 documentation. Welcome to Bokeh — Bokeh 0.10.0 documentation. How To Run Linear Regression In Python SciKit-Learn – Big Data Examiner. You know that linear regression is a popular technique and you might as well seen the mathematical equation of linear regression. But do you know how to implement a linear regression in Python?? If so don’t read this post because this post is all about implementing linear regression in Python.
There are several ways in which you can do that, you can do linear regression using numpy, scipy, stats model and sckit learn. Gist:dc649cdc03bf94f1e198. Machine Learning with Python - Linear Regression - Artificial Intelligence in Motion. Melwin Jose: Multivariate Linear Regression. Statistics - Regression [Gerardnico] Prob18. CSEP 546 Data Mining/Machine Learning Winter 2014. Christopher M. Bishop.
Learning From Data MOOC - The Lectures. Installing scikit-learn. Data Science Workflow: Overview and Challenges. Big data. Justmarkham/dive-into-machine-learning. Caesar0301/awesome-public-datasets. Cross Validated. Kaggle: The Home of Data Science. Python Data Analysis Library — pandas: Python Data Analysis Library. Machine learning in Python — scikit-learn 0.16.1 documentation.
The IPython Notebook — IPython.