
7 Books to Grasp Mathematical Foundations of Data Science and Machine Learning. Aspiring data scientist? Master these fundamentals. Data science is an exciting, fast-moving field to become involved in.
There’s no shortage of demand for talented, analytically-minded individuals. Companies of all sizes are hiring data scientists, and the role provides real value across a wide range of industries and applications. Often, people’s first encounters with the field come through reading sci-fi headlines generated by major research organizations. AI Is Going to Change the 80/20 Rule. Many high-performance organizations remain passionate about Vilfredo Pareto, the incisive Italian engineer and economist.

They continue to be inspired by his 80/20 principle, the idea that 80% of effects (sales, revenue, etc.) come from 20% of causes (products, employees, etc). As machine learning and AI algorithmic innovation transform analytics, I’m betting that next-generation algorithms will supercharge Pareto’s empirically provocative paradigm. Here are three important ways that AI and machine learning will redefine how organizations use the Pareto principle to digitally drive profitable innovation to levels beyond conventional analytics.
Smart Paretos. Good Data Management Practices For Data Analysis: Part 1. By: Frank Farach, Staff Scientist As far as research experiences go, it’s hard to beat the moment when you finally get to analyze and interpret the data you worked so hard to obtain.
Unfortunately, it’s common to spend many tedious and frustrating hours cleaning and wrangling your data into a usable format, followed by careful exploration to provide context and reveal potential problems with the analyses you want to run. Many researchers view these data management tasks as arduous, frustrating, and brittle—and rightly so. Entire books and articles have been written about data cleaning. 8 Skills You Need to Be a Data Scientist. Demystifying Data Science: 4 Kinds of Data Science Jobs and 8 Skills that Will Get You Hired Interested in landing a job as a data scientist?
You’re in good company – a recent article by Thomas Davenport and D.J. The End of Theory: The Data Deluge Makes the Scientific Method Obsolete. "All models are wrong, but some are useful.
" So proclaimed statistician George Box 30 years ago, and he was right. But what choice did we have? Only models, from cosmological equations to theories of human behavior, seemed to be able to consistently, if imperfectly, explain the world around us. Until now. How Data Failed Us in Calling the Election. The election prediction business is one small aspect of a far-reaching change across industries that have increasingly become obsessed with data, the value of it and the potential to mine it for cost-saving and profit-making insights.
It is a behind-the-scenes technology that quietly drives everything from the ads that people see online to billion-dollar acquisition deals. Examples stretch from Silicon Valley to the industrial heartland. Microsoft, for example, is paying $26 billion for LinkedIn largely for its database of personal profiles and business connections on more than 400 million people. General Electric, the nation’s largest manufacturer, is betting big that data-generating sensors and software can increase the efficiency and profitability of its jet engines and other machinery. How mathematics can fight the abuse of big data algorithms. “Is maths creating an unfair society?”
That seems to be the question on many people’s lips. The rise of big data and the use of algorithms by organisations has left many blaming mathematics for modern society’s ills – refusing people cheap insurance, giving false credit ratings, or even deciding who to interview for a job. We have been here before. Following the banking crisis of 2008, some argued that it was a mathematical formula that felled Wall Street. Small Data vs. Big Data: Back to the Basics. Small data is data in a volume and format that makes it accessible, informative and actionable.
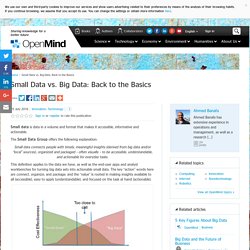
The Small Data Group offers the following explanation: Small data connects people with timely, meaningful insights (derived from big data and/or “local” sources), organized and packaged – often visually – to be accessible, understandable, and actionable for everyday tasks. This definition applies to the data we have, as well as the end-user apps and analyst workbenches for turning big data sets into actionable small data. The key “action” words here are connect, organize, and package, and the “value” is rooted in making insights available to all (accessible), easy to apply (understandable), and focused on the task at hand (actionable). The Mathematical Shape Of Big Science Data. Forbes Welcome. The Problem with Our Data Obsession. A contentious question on the California ballot in 2008 inspired a simple online innovation: a website called Eightmaps.com.

The number in the name referred to Proposition 8, which called for the state’s constitution to be amended to prohibit gay marriage. Under California’s campaign finance laws, all donations greater than $100 to groups advocating for or against Proposition 8 were recorded in a publicly accessible database.
The Internet, peer-reviewed. It could be one of the most important innovations on the Internet since the browser.
Imagine an open-source, crowd-sourced, community-moderated, distributed platform for sentence-level annotation of the Web. In other words, a way to cut through the babble and restore some sanity and trust. False beliefs persist, even after instant online corrections. It seems like a great idea: Provide instant corrections to web-surfers when they run across obviously false information on the Internet. But a new study suggests that this type of tool may not be a panacea for dispelling inaccurate beliefs, particularly among people who already want to believe the falsehood. “Real-time corrections do have some positive effect, but it is mostly with people who were predisposed to reject the false claim anyway,” said R.
Kelly Garrett, lead author of the study and assistant professor of communication at Ohio State University. “The problem with trying to correct false information is that some people want to believe it, and simply telling them it is false won’t convince them.” For example, the rumor that President Obama was not born in the United States was widely believed during the past election season, even though it was thoroughly debunked. Factual’s Gil Elbaz Wants to Gather the Data Universe. FACTUAL sells data to corporations and independent software developers on a sliding scale, based on how much the information is used. Small data feeds for things like prototypes are free; contracts with its biggest customers run into the millions. Sometimes, Factual trades data with other companies, building its resources. Some current uses are for adding information like restaurant locations to cellphone maps, or for planning sales campaigns.
Snopes.com: Urban Legends Reference Pages. 5D optical memory in glass could record the last evidence of civilization. Scientists ‘freeze’ light for an entire minute. Million-Year Data Storage Disk Unveiled. Back in 1956, IBM introduced the world’s first commercial computer capable of storing data on a magnetic disk drive. The IBM 305 RAMAC used fifty 24-inch discs to store up to 5 MB, an impressive feat in those days. How Quantum Computers and Machine Learning Will Revolutionize Big Data - Wired Science.
When subatomic particles smash together at the Large Hadron Collider in Switzerland, they create showers of new particles whose signatures are recorded by four detectors. The LHC captures 5 trillion bits of data — more information than all of the world’s libraries combined — every second. After the judicious application of filtering algorithms, more than 99 percent of those data are discarded, but the four experiments still produce a whopping 25 petabytes (25×1015 bytes) of data per year that must be stored and analyzed. That is a scale far beyond the computing resources of any single facility, so the LHC scientists rely on a vast computing grid of 160 data centers around the world, a distributed network that is capable of transferring as much as 10 gigabytes per second at peak performance. The LHC’s approach to its big data problem reflects just how dramatically the nature of computing has changed over the last decade. Since Intel co-founder Gordon E. Memory and Movement.
Curation.
The Mathematical Shape of Big Science Data. Simon DeDeo, a research fellow in applied mathematics and complex systems at the Santa Fe Institute, had a problem. Data Scientist: The Sexiest Job of the 21st Century. Artwork: Tamar Cohen, Andrew J Buboltz, 2011, silk screen on a page from a high school yearbook, 8.5" x 12" Download a free chapter from Thomas H. The Question to Ask Before Hiring a Data Scientist - Michael Li. By Michael Li | 10:00 AM August 6, 2014. For Start-Ups, Sorting the Data Cloud Is the Next Big Thing. How Big Data Gets Real. The business of Big Data, which involves collecting large amounts of data and then searching it for patterns and new revelations, is the result of cheap storage, abundant sensors and new software.
It has become a multibillion-dollar industry in less than a decade. Growing at speed like that, it is easy to miss how much remains to do before the industry has proven standards. Until then, lots of customers are probably wasting much of their money. There is essential work to be done training a core of people in very hard problems, like advanced statistics and software that ensures data quality and operational efficiency. Broad-based literacy in the uses of data should probably happen too, along with new kinds of management, better tools for reading the information, and privacy safeguards for corporate and personal information.
Why the world’s governments are interested in creating hubs for open data. The Limits of Big Data: A Review of Social Physics by Alex Pentland. Big Data, Trying to Build Better Workers. Tears in rain: how Snapchat showed me the glory of data death. "I've seen things you people wouldn't believe. Attack ships on fire off the shoulder of Orion. I watched c-beams glitter in the dark near the Tannhäuser Gate. All those moments will be lost in time, like tears in rain. Time to die. " Anyone who's seen Ridley Scott's sci-fi masterpiece Blade Runner probably knows this famous speech from its climax: the final words of Roy Batty, the ruthless but ultimately tragic leader of a band of androids rampaging across a dystopian future Los Angeles. IBM's Watson wants to fix America's doctor shortage.
Words by the Millions, Sorted by Software. Kris Snibbe/Harvard University At Harvard, Erez Lieberman Aiden and Jean-Baptiste Michel, standing center and right, are among those working on a browser to note changes in language over time. Denise Applewhite/Princeton University David Blei, a professor at Princeton. David M. Down in the Data Dumps: Researchers Inventory a World of Information.
How Companies Learn Your Secrets. What are you revealing online? Much more than you think. What data is being collected on you? Some shocking info. Everything We Know About What Data Brokers Know About You. How Facebook Uses Your Data to Target Ads, Even Offline.