Data science
> Skac
Cultural Insights - Geert Hofstede. GDELT: Global Database of Events, Language, and Tone. YAGO - D5: Databases and Information Systems (Max-Planck-Institut für Informatik)
Overview YAGO is a huge semantic knowledge base, derived from Wikipedia WordNet and GeoNames.
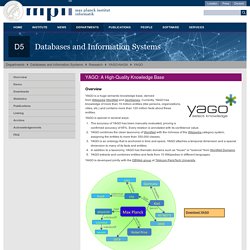
Currently, YAGO has knowledge of more than 10 million entities (like persons, organizations, cities, etc.) and contains more than 120 million facts about these entities. YAGO is special in several ways: The accuracy of YAGO has been manually evaluated, proving a confirmed accuracy of 95%. Every relation is annotated with its confidence value.YAGO combines the clean taxonomy of WordNet with the richness of the Wikipedia category system, assigning the entities to more than 350,000 classes.YAGO is an ontology that is anchored in time and space. YAGO is developed jointly with the DBWeb group at Télécom ParisTech University.
Word2vec - Tool for computing continuous distributed representations of words.
Freebase. Freebase is a large collaborative knowledge base consisting of metadata composed mainly by its community members.

It is an online collection of structured data harvested from many sources, including individual 'wiki' contributions.[2] Freebase aims to create a global resource which allows people (and machines) to access common information more effectively. It was developed by the American software company Metaweb and has been running publicly since March 2007. Metaweb was acquired by Google in a private sale announced July 16, 2010.[3] Google's Knowledge Graph is powered in part by Freebase.[4] Freebase data is freely available for commercial and non-commercial use under a Creative Commons Attribution License, and an open API, RDF endpoint, and database dump are provided for programmers.
Overview[edit] Described by Tim O'Reilly upon their launch, "Freebase is the bridge between the bottom up vision of Web 2.0 collective intelligence and the more structured world of the semantic web. Applying Graph Theory and Network Science. Data-gov Wiki. Catalog. The Socrata Open Data API (SODA) allows software developers to access data hosted in Socrata data sites programmatically.
Developers can create applications that use the SODA APIs to visualize and “mash-up” Socrata datasets in new and exciting ways. Create an iPhone application that visualizes government spending in your area, a web application that allows citizens to look up potential government benefits they'd overlooked, or a service that automatically emails you when new earmarks are added to bills that you wish to track. To start accessing this dataset programmatically, use the API endpoint provided below. For more information and examples on how to use the Socrata Open Data API, reference our Developer Documentation.
API Access Endpoint: Column IDs: Type type Domain domain Name name Description description Category category Keywords keywords Rating rating Comments comments Uid system_id Update Frequency update_frequency Time Period time_period Agency agency Sub-Agency sub_agency High Value Dataset Identifier id. Home. Orange – Data Mining Fruitful & Fun. 5 of the Best Free and Open Source Data Mining Software. The process of extracting patterns from data is called data mining.
It is recognized as an essential tool by modern business since it is able to convert data into business intelligence thus giving an informational edge. At present, it is widely used in profiling practices, like surveillance, marketing, scientific discovery, and fraud detection. There are four kinds of tasks that are normally involve in Data mining: * Classification - the task of generalizing familiar structure to employ to new data* Clustering - the task of finding groups and structures in the data that are in some way or another the same, without using noted structures in the data.* Association rule learning - Looks for relationships between variables.* Regression - Aims to find a function that models the data with the slightest error.
Data science. Data Science Data science is the study of the generalizable extraction of knowledge from data,[1] yet the key word is science.[2] It incorporates varying elements and builds on techniques and theories from many fields, including signal processing, mathematics, probability models, machine learning, computer programming, statistics, data engineering, pattern recognition and learning, visualization, uncertainty modeling, data warehousing, and high performance computing with the goal of extracting meaning from data and creating data products.
Data Science need not be always for big data, however, the fact that data is scaling up makes big data an important aspect of data science. A practitioner of data science is called a data scientist.
SciPy -
Machine learning in Python — scikit-learn 0.13.1 documentation. Weka 3 - Data Mining with Open Source Machine Learning Software in Java. Weka is a collection of machine learning algorithms for data mining tasks. It contains tools for data preparation, classification, regression, clustering, association rules mining, and visualization. Found only on the islands of New Zealand, the Weka is a flightless bird with an inquisitive nature. The name is pronounced like this, and the bird sounds like this.
Weka is open source software issued under the GNU General Public License. We have put together several free online courses that teach machine learning and data mining using Weka. Weka supports deep learning!
Machine Learning Repository: Covertype Data Set. Source: Original Owners of Database: Remote Sensing and GIS Program Department of Forest Sciences College of Natural Resources Colorado State University Fort Collins, CO 80523 (contact Jock A.

Blackard, jblackard '@' fs.fed.us or Dr. Denis J. Dean, denis.dean '@' utdallas.edu) Donors of database: 1. 2. 3.
