
Deep Reinforcement Learning. Deep Reinforcement Learning: Pong from Pixels. This is a long overdue blog post on Reinforcement Learning (RL).
RL is hot! You may have noticed that computers can now automatically learn to play ATARI games (from raw game pixels!) 1606.04838v1. Hello, TensorFlow! The TensorFlow project is bigger than you might realize.
The fact that it's a library for deep learning, and its connection to Google, has helped TensorFlow attract a lot of attention. But beyond the hype, there are unique elements to the project that are worthy of closer inspection: The core library is suited to a broad family of machine learning techniques, not “just” deep learning. Linear algebra and other internals are prominently exposed. In addition to the core machine learning functionality, TensorFlow also includes its own logging system, its own interactive log visualizer, and even its own heavily engineered serving architecture. Introducing FBLearner Flow: Facebook's AI backbone. Many of the experiences and interactions people have on Facebook today are made possible with AI.
When you log in to Facebook, we use the power of machine learning to provide you with unique, personalized experiences. End to end dl using px. Video Recordings of the ICML’15 Deep Learning Workshop. Text Mining the History of Medicine. Abstract Historical text archives constitute a rich and diverse source of information, which is becoming increasingly readily accessible, due to large-scale digitisation efforts.
However, it can be difficult for researchers to explore and search such large volumes of data in an efficient manner. Text mining (TM) methods can help, through their ability to recognise various types of semantic information automatically, e.g., instances of concepts (places, medical conditions, drugs, etc.), synonyms/variant forms of concepts, and relationships holding between concepts (which drugs are used to treat which medical conditions, etc.).
TM analysis allows search systems to incorporate functionality such as automatic suggestions of synonyms of user-entered query terms, exploration of different concepts mentioned within search results or isolation of documents in which concepts are related in specific ways. Editor: Luis M. Copyright: © 2016 Thompson et al. Introduction Background Related work Methods. Visualisation of Global Cargo Ships. Markov Chain Monte Carlo sampling – Alexander Galea's Blog. This is the third part in a short series of blog posts about quantum Monte Carlo (QMC).
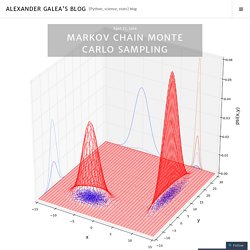
The series is derived from an introductory lecture I gave on the subject at the University of Guelph. Part 1 – calculating Pi with Monte Carlo Part 2 – Galton’s peg board and the central limit theorem So far in this series we have seen various examples of random sampling. Here we’ll look at a simple Python script that uses Markov chains and the Metropolis algorithm to randomly sample complicated two-dimensional probability distributions.
Leaf. Our life is frittered away by detail.

Simplify, simplify. - Henry David Thoreau This short book teaches you how you can build machine learning applications (with Leaf). Leaf is a Machine Intelligence Framework engineered by hackers, not scientists. It has a very simple API consisting of Layers and Solvers, with which you can build classical machine as well as deep learning and other fancy machine intelligence applications. Containerized Data Science and Engineering - Part 2, Dockerized Data Science. (This is part 2 of a two part series of blog posts about doing data science and engineering in a containerized world, see part 1 here) Let's admit it, data scientists are developing some pretty sweet (and potentially valuable) models, optimizations, visualizations, etc.

Unfortunately, many of these models will never actually be used because they cannot be "productionized. " In fact, much of the "data science" happening in industry is happening in isolation on data scientists' laptops, and, in the case in which data science applications are actually deployed, they are often deployed as hacky python/R scripts uploaded AWS and run as a cron job. This is a huge problem and blocker for data science work in industry, as evidenced below: "There was only one problem — all of my work was done in my local machine in R. But don't worry! Pomegranate — pomegranate 0.4.0 documentation. Pomegranate implements fast, efficient, and extremely flexible probabilistic modelling for Python.
It grew out of the YAHMM package where many of the components of hidden Markov models could be rearranged to form other probabilistic models, such as general mixture models and markov chains. pomegranate is flexible enough to allow nesting of these components to form models such as general mixture model hidden Markov models (GMM-HMMs) or Naive Bayes comparing a hidden Markov model to a Markov chain. It currently supports: Documentation and API references for each of these methods are present on the scrollbar to the left. IPython notebook tutorials and examples are present in the github repository. Building Interactive Dashboards with Jupyter. Welcome to Part II of "Advanced Jupyter Notebook Tricks.
" In Part I, I described magics, and how to calculate notebooks in "batch" mode to use them as reports or dashboards. In this post, I describe another powerful feature of Notebooks: the ability to use interactive widgets to build interactive dashboards. Simulated annealing. Simulated annealing interprets slow cooling as a slow decrease in the probability of accepting worse solutions as it explores the solution space.
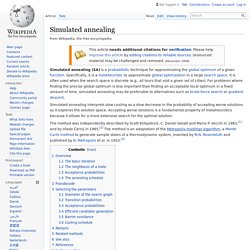
Accepting worse solutions is a fundamental property of metaheuristics because it allows for a more extensive search for the optimal solution. The method was independently described by Scott Kirkpatrick, C. Daniel Gelatt and Mario P. Vecchi in 1983,[1] and by Vlado Černý in 1985.[2] The method is an adaptation of the Metropolis–Hastings algorithm, a Monte Carlo method to generate sample states of a thermodynamic system, invented by M.N. Rosenbluth and published by N. Overview[edit] 1602.04938v1. Lift analysis - A data scientist's secret weapon. Learning a Personalized Homepage. By Chris Alvino and Justin Basilico As we’ve described in our previous blog posts, at Netflix we use personalization extensively and treat every situation as an opportunity to present the right content to each of our over 57 million members. The main way a member interacts with our recommendations is via the homepage, which they see when they log into Netflix on any supported device.
The primary function of the homepage is to help each member easily find something to watch that they will enjoy. A problem we face is that our catalog contains many more videos than can be displayed on a single page and each member comes with their own unique set of interests. Thus, a general algorithmic challenge becomes how to best tailor each member’s homepage to make it relevant, cover their interests and intents, and still allow for exploration of our catalog. How Airbnb uses machine learning to detect host preferences. At Airbnb we seek to match people who are looking for accommodation – guests — with those looking to rent out their place – hosts. Guests reach out to hosts whose listings they wish to stay in, however a match succeeds only if the host also wants to accommodate the guest.
I first heard about Airbnb in 2012 from a friend. Location Relevance at Airbnb. By Maxim Charkov, Riley Newman & Jan Overgoor Here at Airbnb, as you can probably imagine, we’re big fans of travel. We love thinking about the diversity of experiences our host community offers, and we spend a fair amount of time trying to make sense of the tens of thousands of cities where people are booking trips every night. If Apple has the iPad and iPhone, we have New York and Paris. And Kavajë, Außervillgraten, and Bli Bli. Dataquest Blog - Writings about data science, from the makers of Dataquest.io. There have been dozens of articles written comparing Python and R from a subjective standpoint. We’ll add our own views at some point, but this article aims to look at the languages more objectively. We’ll analyze a dataset side by side in Python and R, and show what code is needed in both languages to achieve the same result.
This will let us understand the strengths and weaknesses of each language without the conjecture. Deeplearning4j - Open-source, distributed deep learning for the JVM. Contents Definition & Structure Invented by Geoff Hinton, Restricted Boltzmann machines are useful for dimensionality reduction, classification, regression, collaborative filtering, feature learning and topic modeling. Technical debt machine learning. Working with maps in Python.
This Is What Controversies Look Like in the Twittersphere. Many a controversy has raged on social media platforms such as Twitter. Some last for weeks or months, others blow themselves in an afternoon. Learn data science online, for free - Dataquest. Decision Making Under Uncertainty: An Introduction to Robust Optimization (Part 1) Measuring the Impact of Uncertainty. Dataquest Blog - Writings about data science, from the makers of Dataquest.io. Tracking down the Villains: Outlier Detection at Netflix. Neural networks and deep learning. Agents Teaching humans in reinforcement learning tasks. Latent Dirichlet allocation. ▶ Topic Models.