
The Coming Automation of Propaganda. If you want a vision of the future, imagine a thousand bots screaming from a human face – forever (apologies to George Orwell).

As U.S. policymakers remain indecisive over how to prevent a repeat of the 2016 election interference, the threat is looming ever more ominous on the horizon. The public has unfortunately settled on the term “bots” to describe the social media manipulation activities of foreign actors, invoking an image of neat rows of metal automatons hunched over keyboards, when in reality live humans are methodically at work. While the 2016 election mythologized the power of these influence-actors, such work is slow, costly, and labor-intensive. Humans must manually create and manage accounts, hand-write posts and comments, and spend countless hours reading content online to signal-boost particular narratives. Characterizing the Threat Improvements in AI bots, up to this point, have mostly manifested in relatively harmless areas like customer service.
Countering the Effects. Supervised learning: predicting an output variable from high-dimensional observations — scikit-learn 0.18.1 documentation. The problem solved in supervised learning Supervised learning consists in learning the link between two datasets: the observed data X and an external variable y that we are trying to predict, usually called “target” or “labels”.
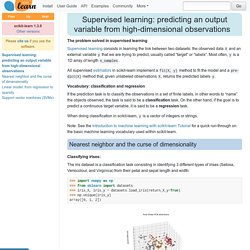
Most often, y is a 1D array of length n_samples. All supervised estimators in scikit-learn implement a fit(X, y) method to fit the model and a predict(X) method that, given unlabeled observations X, returns the predicted labels y. Vocabulary: classification and regression If the prediction task is to classify the observations in a set of finite labels, in other words to “name” the objects observed, the task is said to be a classification task. You Too Can Become a Machine Learning Rock Star! No PhD Necessary.
A company called Bonsai joins a movement to democratize machine learning.
Get ready to build your own neural net. If you are a strong-armed NFL quarterback who reads defenses like genre fiction, a movie star whose name alone can open a film in China, or a stock picker who beats Buffet every time, congratulations: you are almost as valuable as a data scientist or machine learning engineer with a PhD from Stanford, MIT, or Carnegie Mellon. At least it seems that way. Every company in Silicon Valley — increasingly, every company everywhere — is frantically competing for those human prizes, in a human resources version of a truffle hunt. As businesses now realize that their competitiveness relies on machine learning and artificial intelligence in general, job openings for those trained in the field well exceed all the people in the world who aren’t locked up by Facebook, Google, and other superpowers. The real prerequisite for machine learning isn't math, it's data analysis. When beginners get started with machine learning, the inevitable question is “what are the prerequisites?
What do I need to know to get started?” And once they start researching, beginners frequently find well-intentioned but disheartening advice, like the following: You need to master math. You need all of the following: – Calculus – Differential equations – Mathematical statistics – Optimization – Algorithm analysis – and – and – and …….. Why is so much memory needed for deep neural networks? Memory is one of the biggest challenges in deep neural networks (DNNs) today.

Researchers are struggling with the limited memory bandwidth of the DRAM devices that have to be used by today's systems to store the huge amounts of weights and activations in DNNs. DRAM capacity appears to be a limitation too. But these challenges are not quite as they seem. Computer architectures have developed with processor chips specialised for serial processing and DRAMs optimised for high density memory. Inside an AI 'brain' - What does machine learning look like? One aspect all recent machine learning frameworks have in common - TensorFlow, MxNet, Caffe, Theano, Torch and others - is that they use the concept of a computational graph as a powerful abstraction.

A graph is simply the best way to describe the models you create in a machine learning system. These computational graphs are made up of vertices (think neurons) for the compute elements, connected by edges (think synapses), which describe the communication paths between vertices. [1703.01619] Neural Machine Translation and Sequence-to-sequence Models: A Tutorial. Apifier - The web crawler that works on every website. Crawling and Scraping Web Pages with Scrapy and Python 3. Introduction Web scraping, often called web crawling or web spidering, or “programatically going over a collection of web pages and extracting data,” is a powerful tool for working with data on the web.
With a web scraper, you can mine data about a set of products, get a large corpus of text or quantitative data to play around with, get data from a site without an official API, or just satisfy your own personal curiosity. In this tutorial, you’ll learn about the fundamentals of the scraping and spidering process as you explore a playful data set. We'll use BrickSet, a community-run site that contains information about LEGO sets. By the end of this tutorial, you’ll have a fully functional Python web scraper that walks through a series of pages on Brickset and extracts data about LEGO sets from each page, displaying the data to your screen.
A Fast and Powerful Scraping and Web Crawling Framework. Is there an open source crawler to scrape ecommerce sites (product catalog, key elements of the e-commerce site)? - Quora. By sparring with AlphaGo, researchers are learning how an algorithm thinks — Quartz. “The game is amazing.
Crazy. Beautiful.” Fan Hui is speaking to a chatty audience at the 2016 European Go Congress in St. Petersburg, Russia, gushing over a game of Go played by one of his mentors. Hui’s enthusiasm is infectious—the room’s chatter subsides as he pulls up slides of the complex Chinese game, whose players battle to dominate a 19×19 board with black and white tiles called stones. Jobs at OpenAI.
Attacking machine learning with adversarial examples. Adversarial examples are inputs to machine learning models that an attacker has intentionally designed to cause the model to make a mistake; they're like optical illusions for machines.

In this post we'll show how adversarial examples work across different mediums, and will discuss why securing systems against them can be difficult. At OpenAI, we think adversarial examples are a good aspect of security to work on because they represent a concrete problem in AI safety that can be addressed in the short term, and because fixing them is difficult enough that it requires a serious research effort.
(Though we'll need to explore many aspects of machine learning security to achieve our goal of building safe, widely distributed AI.) The approach is quite robust; recent research has shown adversarial examples can be printed out on standard paper then photographed with a standard smartphone, and still fool systems. Adversarial examples have the potential to be dangerous. Terryum/awesome-deep-learning-papers: The most cited deep learning papers. Gallery: 'Brain scans' map what happens during inside machine learning. 7 Types of Regression Techniques you should know.
Multiple regression in machine classification.