
Fds.pdf. Principles of Distributed Computing. Web.stanford.edu/class/cs347/reading/zab.pdf. Conflict-free replicated data type. In distributed computing, a conflict-free replicated data type (abbreviated CRDT) is a type of specially-designed data structure used to achieve strong eventual consistency (SEC). [1] There are two alternative routes to ensuring SEC: operation-based CRDTs [2] and state-based CRDTs. [3] The two alternatives are equivalent, as one can emulate the other,[1] but operation-based CRDTs require additional guarantees from the communication middleware.[1] The CRDT concept was first formally defined in 2007 by Marc Shapiro and Nuno Preguiça in terms of operation commutativity, [5] and development was initially motivated by collaborative text editing. [6] [7] The concept of semilattice evolution of replicated states was first defined by Baquero and Moura in 1997, [8] [3] and development was initially motivated by mobile computing.
The two concepts were later unified in 2011. [1] [4] Overview[edit] History[edit] Strong eventual consistency[edit] Safety, liveness and fault tolerance—the consensus choices. This week, the Stellar network experienced a ledger fork that is related to a failure of the underlying Ripple/Stellar consensus system.

We are completing our review of the impact, but early reports indicate that the impact was not major. We are reaching out to all the known gateways and exchanges to see what we can do to assist. Given how novel consensus systems are and our belief that we should be transparent about the technology, which includes its strengths and weaknesses, we wanted to provide some context for the ledger fork and how it happened in Stellar.
Issue 1: Sacrificing safety over liveness and fault tolerance—potential for double spends The existing Ripple/Stellar consensus algorithm is implemented in a way that favors fault tolerance and termination over safety. Groups.csail.mit.edu/tds/papers/Lynch/jacm85.pdf. Concerning the size of logical clocks in distributed systems. Tolstenko.net/dados/Unicamp/2010.1/mc714/extras/301_recomendada_Raynal-92-LogicalClocks.pdf. Jacm85.pdf. Db.cs.berkeley.edu/cs286/papers/bayou-sosp1995.pdf. Css.csail.mit.edu/6.824/2014/papers/paxos-simple.pdf. Research.microsoft.com/en-us/um/people/lamport/pubs/lamport-paxos.pdf. Steve.vinoski.net/pdf/IC-Rediscovering-Distributed-Systems.pdf.
Untitled. Research.microsoft.com/en-us/um/people/lamport/pubs/time-clocks.pdf. Steve.vinoski.net/pdf/IC-Rediscovering-Distributed-Systems.pdf. Static.googleusercontent.com/media/research.google.com/ru//pubs/archive/36356.pdf. Metadata. Facebook's software architecture. I had summarized/discussed a couple papers (Haystack, Memcache caching) about Facebook's architecture before.
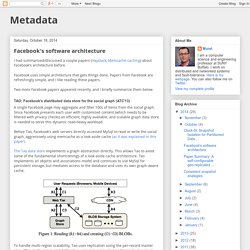
Facebook uses simple architecture that gets things done. Papers from Facebook are refreshingly simple, and I like reading these papers. Two more Facebook papers appeared recently, and I briefly summarize them below. TAO: Facebook's distributed data store for the social graph (ATC'13) A single Facebook page may aggregate and filter 100s of items from the social graph. Before Tao, Facebook's web servers directly accessed MySql to read or write the social graph, aggressively using memcache as a look aside cache (as it was explained in this paper). The Tao data store implements a graph abstraction directly. To handle multi-region scalability, Tao uses replication using the per-record master idea. F4: Facebook's warm BLOB storage system (OSDI'14) Facebook uses Haystack to store all media data, which we discussed earlier here.
Facebook has big data! Discussion. Ddg.jaist.ac.jp/pub/DSU03b.pdf. Research.microsoft.com/en-us/um/people/lamport/pubs/lamport-paxos.pdf. Css.csail.mit.edu/6.824/2014/papers/paxos-simple.pdf. Css.csail.mit.edu/6.824/2014/papers/paxos-simple.pdf. Research.microsoft.com/en-us/um/people/lamport/pubs/lamport-paxos.pdf. Untitled. Chubby-osdi06.pdf. 2014-04.pdf. SyncFree - Publications. Www.guidosalvaneschi.com/attachments/papers/2014_We-Have-a-DREAM-Distributed-Reactive-Programming-with-Consistency-Guarantees_pdf.pdf.
Version Vectors are not Vector Clocks. Most people still confuse Version Vectors and Vector Clocks.
Well, I did confuse them for several years. In fact they look the same and the update rules are almost the same. Both of these mechanisms are practical ways of capturing causality in distributed systems. Causality (in distributed systems) is an abstract concept, can was formalized in 1978 by Leslie Lamport in one of the most cited articles in computer science. In 1983 Version Vectors are developed to track the causal relations among data items that can be concurrently updated. First, in order to simplify a little bit, lets consider that we have a fixed number of processes and a fixed number of replicas. Vector Clocks need to establish a partial order among a, potentially ever growing, set of events occurring in the processes. Lets consider a simple example, thats shows that vectors of integers are over-expressive . The message is, use the right tools and know the differences. Like this: Like Loading... Web.stanford.edu/class/cs240/readings/lamport.pdf.
Www.bailis.org/papers/hat-vldb2014.pdf. Pdos.csail.mit.edu/~neha/phaser.pdf. When Does Consistency Require Coordination? Peter Bailis. Ddg.jaist.ac.jp/pub/DSU03b.pdf. Non-blocking Transactional Atomicity. Non-blocking Transactional Atomicity 28 May 2013 tl;dr: You can perform non-blocking multi-object atomic reads and writes across arbitrary data partitions via some simple multi-versioning and by storing metadata regarding related items.

N.B. This is a long post, but it’s comprehensive. Reading the first third will give you most of the understanding. Edit 4/2014: We wrote a SIGMOD paper on these ideas! Performing multi-object updates is a common but difficult problem in real-world distributed systems. Existing Techniques: Locks, Entity Groups, and “Fuck-it Mode” The state of the art in transactional multi-object update typically employs one of three strategies. Use locks to update multiple items at once. In this post, I’ll provide a simple alternative (let’s call it Non-blocking Transactional Atomicity, or NBTA) that uses multi-versioning and some extra metadata to ensure transactional atomicity without the use of locks.
Good, pending, and Invariants Races and Pointers. Dotted-version-vectors-2012.pdf. Dvvset-dais.pdf. Doppel:osdi14.pdf. Datasys.cs.iit.edu/publications/2014_SCRAMBL14_HDMQ.pdf. Basho Riak - NoSQL Key Value Store Designed for Scale. Introducing Dynomite - Making Non-Distributed Databases, Distributed. Netflix has long been a proponent of the microservices model.
This model offers higher-availability, resiliency to failure and loose coupling. The downside to such an architecture is the potential for a latent user experience. Every time a customer loads up a homepage or starts to stream a movie, there are a number of microservices involved to complete that request. Most of these microservices use some kind of stateful system to store and serve data. A few milliseconds here and there can add up quickly and result in a multi-second response time. The Cloud Database Engineering team at Netflix is always looking for ways to shave off milliseconds from an application’s database response time, while maintaining our goal of local high-availability and multi-datacenter high-availability. Inspired by the Dynamo White Paper as well as our experience with Apache Cassandra, Dynomite is a sharding and replication layer.
Motivation Dynomite Topology Replication Highly available reads Cold cache warm-up. Www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf. Christopher Meiklejohn. Srds07-leitao.pdf. Sosp_sparrow.pdf. [1210.3368] An optimized conflict-free replicated set. Testing in a Distributed World. Achieving Rapid Response Times in Large Online Services. Achieving Rapid Response Times in Large Online Services Jeffrey Dean Abstract Today’s large-scale web services provide rapid responses to interactive requests by applying large amounts of computational resources to massive datasets.
They typically operate in warehouse-sized datacenters and run on clusters of machines that are shared across many kinds of interactive and batch jobs. As these systems distribute work to ever larger numbers of machines and sub-systems in order to provide interactive response times, it becomes increasingly difficult to tightly control latency variability across these machines, and often the 95%ile and 99%ile response times suffer in an effort to improve average response times. As systems scale up, simply stamping out all sources of variability does not work. Joint work with Luiz Barroso and many others at Google. Pfraze/crdt_notes. Randommood/RICON2014. A Brief History of Time in Riak. RICON. Vr-revisited.pdf. Distributed systems theory for the distributed systems engineer : Paper Trail. Gwen Shapira, SA superstar and now full-time engineer at Cloudera, asked a question on Twitter that got me thinking.

My response of old might have been “well, here’s the FLP paper, and here’s the Paxos paper, and here’s the Byzantine generals paper…”, and I’d have prescribed a laundry list of primary source material which would have taken at least six months to get through if you rushed. But I’ve come to thinking that recommending a ton of theoretical papers is often precisely the wrong way to go about learning distributed systems theory (unless you are in a PhD program). Papers are usually deep, usually complex, and require both serious study, and usually significant experience to glean their important contributions and to place them in context. What good is requiring that level of expertise of engineers? What distributed systems theory should a distributed systems engineer know? A little theory is, in this case, not such a dangerous thing. First steps Failure and Time You should know:
Lpd.epfl.ch/sgilbert/pubs/BrewersConjecture-SigAct.pdf. PhDThesis.pdf. Driscoll-Hall-Sivencrona-Xumsteg-03.pdf. Parker83detection.pdf. Volume 2.