
深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam) - 知乎专栏. 前言 (标题不能再中二了)本文仅对一些常见的优化方法进行直观介绍和简单的比较,各种优化方法的详细内容及公式只好去认真啃论文了,在此我就不赘述了。
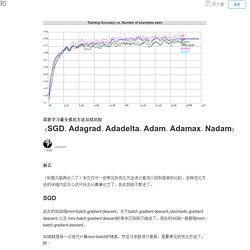
此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mini-batch gradient descent的具体区别就不细说了。 淺談Deep Learning原理及應用. 作者:周秉誼 / 趨勢科技 技術經理 隨著AlphaGo擊敗人類最高端的圍棋職業棋士,及在Atari遊戲或各式電子遊戲上令人驚嘆的表現,深度學習(Deep Learning)在短短幾個月內就成為家喻戶曉的最新科技名詞。
各大科技公司,都不約而同地紛紛投入深度學習的研究,並將研究成果應用在各項產品上。 使得深度學習這項技術在不知不覺中,成為人類生活中不可或缺的一部份。 到底什麼深度學習可以對日常生活帶來那麼大的改變呢? 深度學習 Deep Learning:中文學習資源整理 - 傑瑞窩在這. 大學那時,看著室友們去修「機器學習」這門課,被一堆數學算式打趴,就對這個領域有種畏懼。
Deep Learning with Python. Deep learning is applicable to a widening range of artificial intelligence problems, such as image classification, speech recognition, text classification, question answering, text-to-speech, and optical character recognition.
It is the technology behind photo tagging systems at Facebook and Google, self-driving cars, speech recognition systems on your smartphone, and much more. In particular, Deep learning excels at solving machine perception problems: understanding the content of image data, video data, or sound data. Here's a simple example: say you have a large collection of images, and that you want tags associated with each image, for example, "dog," "cat," etc. Deep learning can allow you to create a system that understands how to map such tags to images, learning only from examples. This system can then be applied to new images, automating the task of photo tagging. . ~ Gustavo Patino ~ Srdjan Santic. 入門 AI 從「深度學習」開始,五本必讀的深度學習聖經書籍. 【我們為什麼挑選這篇文章】本文作者 Daniel Jeffries 針對五本兼具理論與實務的書籍,推薦給不同需求、不同經驗的深度學習者,以期大家在買書前作為參考,依序閱讀。
(責任編輯:楊侑陵) (以下以 Daniel Jeffries 第一人稱撰寫) 淺談Facebook最新CNN神經翻譯機:Convolutional Sequence to Sequence Learning. 今天小編要介紹的是來自FAIR團隊這幾天出的基於純CNN架構翻譯機:Convolutional Sequence to Sequence Learning.

其結果跟Google最新的方法比較後重點結果如下: 英翻法產生翻譯(WMT English->French)速度的表現: Dosudo 讀書肚矽谷工程師讀書會 Deep learning study group – Dosudo 讀書肚. [系列活動] 手把手的深度學習實務. Machine Learning - Stanford University. [學習筆記] 統計學:假設檢定 Hypothesis Testing @ Murphy的書房. 以統計方法進行決策的過程中,會提出兩個假設: H0: null hypothesis (虛無假設)。
![[學習筆記] 統計學:假設檢定 Hypothesis Testing @ Murphy的書房](http://cdn.pearltrees.com/s/pic/th/hypothesis-testing-murphy-152563045)
H1: alternative or research hypothesis(對立假設、研究假設)。 把想要檢定的假設定為 H1,H0 則為其相反之假設。 首先,假設 null hypothesis 為真。 據此進行推論。 可能的結論: (i) 有足夠的統計證據可推論 alternative hypohesis 為真 (rejecting the null hypothesis in favor of the alternative)。 假設檢定可能犯的錯誤: Type I error (第一型錯誤): reject a true null hypothesis. Welcome to Machine Learning! - Stanford University. 想成為年薪 300 萬台幣的資料科學大師?一整年的武功秘籍自學清單都在這了! 本文由微信公眾號「大數據文摘」授權轉載,選文:孫強,翻譯:趙娟、王珏。 大數據文摘微信 ID:BigDataDigest。 ,以下為作者 MANISH SARASWAT 第一人稱描述。 新年並非僅僅是更換日曆或是清晨起床後揉開雙眼。 新年是充滿喜悅的一個嶄新開始。 它給我們一個完美的理由養成一個新習慣,它意味著新「希望」的到來。 如果你正在閱讀這篇文章,我確信資料科學會讓你興奮! 註:這些通用的學習計畫是為有抱負的 / 有經驗的資料科學家準備的。 3 分鐘搞懂深度學習到底在深什麼 - PanX 泛科技. 深度學習其實跟 VR 很像,他們都不是全新的概念,卻在這幾年因為硬體進步而死灰復燃。
淺談Deep Learning原理及應用. Unsupervised Feature Learning and Deep Learning Tutorial. Overview A Convolutional Neural Network (CNN) is comprised of one or more convolutional layers (often with a subsampling step) and then followed by one or more fully connected layers as in a standard multilayer neural network.

The architecture of a CNN is designed to take advantage of the 2D structure of an input image (or other 2D input such as a speech signal). This is achieved with local connections and tied weights followed by some form of pooling which results in translation invariant features. Another benefit of CNNs is that they are easier to train and have many fewer parameters than fully connected networks with the same number of hidden units.
In this article we will discuss the architecture of a CNN and the back propagation algorithm to compute the gradient with respect to the parameters of the model in order to use gradient based optimization. Architecture A CNN consists of a number of convolutional and subsampling layers optionally followed by fully connected layers. Keras Documentation. 一文讀懂卷積神經網絡CNN - 壹讀. 據說阿爾法狗戰勝李世乭靠的是卷積神經網絡算法,所以小編找到了一篇介紹該算法的文章,大家可以看一看。
Unsupervised Feature Learning and Deep Learning Tutorial. Consider a supervised learning problem where we have access to labeled training examples . Neural networks give a way of defining a complex, non-linear form of hypotheses , with parameters that we can fit to our data. To describe neural networks, we will begin by describing the simplest possible neural network, one which comprises a single “neuron.” We will use the following diagram to denote a single neuron: This “neuron” is a computational unit that takes as input (and a +1 intercept term), and outputs , where is called the activation function. In these notes, we will choose to be the sigmoid function: Thus, our single neuron corresponds exactly to the input-output mapping defined by logistic regression.
Although these notes will use the sigmoid function, it is worth noting that another common choice for is the hyperbolic tangent, or tanh, function: Here are plots of the sigmoid, and rectified linear functions: Neural Network model We call this step forward propagation.