
Internet Archive: Digital Library of Free Books, Movies, Music & Wayback Machine. Data. MapReduce for the Masses: Zero to Hadoop in Five Minutes with Common Crawl. Common Crawl aims to change the big data game with our repository of over 40 terabytes of high-quality web crawl information into the Amazon cloud, the net total of 5 billion crawled pages.
In this blog post, we’ll show you how you can harness the power of MapReduce data analysis against the Common Crawl dataset with nothing more than five minutes of your time, a bit of local configuration, and 25 cents. When Google unveiled its MapReduce algorithm to the world in an academic paper in 2004, it shook the very foundations of data analysis. By establishing a basic pattern for writing data analysis code that can run in parallel against huge datasets, speedy analysis of data at massive scale finally became a reality, turning many orthodox notions of data analysis on their head. When you’ve got a taste of what’s possible when open source meets open data, we’d like to whet your appetite by asking you to remix this code. Ready to get started? Step 1 – Install Git and Eclipse RHEL/Fedora 1. 2. 3. FindLaw for Legal Professionals. Freshpatents.com: Patent Applications Updated Each Week, RSS, Keyword Monitoring.
Wolfram. Maps. WebCrawler Web Search. All Subject Categories. Google Your Body: Body Browser : bioephemera. Google Labs just released a new “experiment” – Body Browser.
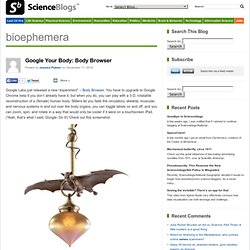
You have to upgrade to Google Chrome beta if you don’t already have it, but when you do, you can play with a 3-D, rotatable reconstruction of a (female) human body. Sliders let you fade the circulatory, skeletal, muscular, and nervous systems in and out over the body organs; you can toggle labels on and off, and you can zoom, spin, and rotate in a way that would only be cooler if it were on a touchscreen iPad. (Yeah, that’s what I said, Google. Do it!) Check out this screenshot: Toggle a few sliders and you can wrap the vessels and nerves in bone: And then you can add muscle: But by far the coolest function is the search box (It’s Google – of course it has one!) Coolest anatomy learning tool ever?
Sadly, it doesn’t go down to cellular resolution – typing in “islets of langerhans” will get you nowhere, and it doesn’t handle brain anatomy very well. Play with Google Chrome Body Browser here. .dtl articles: NEJM.org. Mapping Genetic Risk of Disease Across the World. A Search Engine for Programmers. 28 Sep 2011 If you are a programmer /developer who often shuffles between writing code in multiple languages, check this search engine for all programming related documentation. couch mode print story If you are a programmer or a web developer who often needs to shuffle between writing code in multiple languages, check out searchco.de – this is an instant search engine for all programming related documentation and nothing else.
You type a function name and searchco.de will pull a list of all languages where that function is available along with the syntax and description. Alternately, you may prefix the function name with the language name – like php delete – to limit your search results to a particular language. In addition to regular programming languages, searchco.de also indexes documentation for Windows and Linux commands. Aardvark. Everyone's library.
Spezify. Travel, landscape, and nature pictures - QT Luong stock photos and fine art prints. Domain Name Search Tool. Usenet search engine. WebGL Globe. Directory of Open Access Journals. Top 7 Semantic Search Engines As An Alternative To Google. There’s no denying the power and popularity of the Google search engine, and in comparison to other similar search engines such as Bing, where results are based on page rankings and algorithms, they excel.

But there are other ways to search the web, using what are known as semantic search engines. Using a semantic search engine will ensure more relevant results based on the ability to understand the definition of the word or term that is being searched for, rather than on numbers. Semantic search engines are able to understand the context in which the words are being used, resulting in smart, relevant results. This is a list of the top 7 search engines to get you started in the world of semantic searching. Kngine Kngine’s search results are divided into either web results, or image results. Kngine currently contains more than 8 million Concepts, and that is where the site’s strength lies. Hakia. Siprnet: where America stores its secret cables. How did such an enormous electronic database come into existence and then apparently be so easily leaked?
The answer lies in the tag "Sipdis" which appears on the string of address codes heading each cable. It stands for Siprnet Distribution. Siprnet is itself an acronym, for Secret Internet Protocol Router Network. Siprnet was designed to solve the chronic problem of big bureaucracies – how to share information easily and confidentially among large numbers of people spread around the world. Siprnet is a worldwide US military internet system, kept separate from the ordinary civilian internet and run by the defence department in Washington. Since the terrorist attacks of September 2001, there has been a move in the US to link up separate archives of government information, in the hope that key intelligence no longer gets trapped in information silos or "stovepipes". This means that a diplomatic dispatch marked Sipdis is automatically downloaded on to its embassy's classified website.
Mighty Number. 3D Model Search Engine.