
Numeric and logic puzzles. This math question meant for 7-year-olds has everyone stumped - AOL News. UPDATE: May 18, 2017, 5:06 p.m.
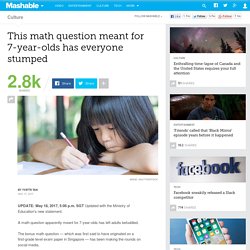
SGT Updated with the Ministry of Education's new statement. A math question apparently meant for 7-year-olds has left adults befuddled. The bonus math question — which was first said to have originated on a first-grade level exam paper in Singapore — has been making the rounds on social media. Singapore's Ministry of Education (MOE) later told Mashable that there were in fact no examinations for Primary 1 students. The seven deadly sins of statistical misinterpretation, and how to avoid them. Statistics is a useful tool for understanding the patterns in the world around us.
But our intuition often lets us down when it comes to interpreting those patterns. In this series we look at some of the common mistakes we make and how to avoid them when thinking about statistics, probability and risk. 1. Assuming small differences are meaningful Many of the daily fluctuations in the stock market represent chance rather than anything meaningful.
You can avoid drawing faulty conclusions about the causes of such fluctuations by demanding to see the “margin of error” relating to the numbers. If the difference is smaller than the margin of error, there is likely no meaningful difference, and the variation is probably just down to random fluctuations. 9 Steps to Become a Data Scientist from Scratch. Because data sciences and data analytics are such rapidly growing fields, there is a dearth of qualified applicants for the number of jobs available.
This makes data science a promising and lucrative field for anyone with an interest and looking for a new career. But how do you become a data scientist? First, the definition of data scientist varies from company to company. There’s no single definition of the term. But in general, a data scientist combines the skills of software engineer with a statistician and throws in a healthy dose of knowledge specific to the industry he or she wants to work in. Roughly 90 percent of data scientists have at least some college education — all the way up to PhDs and doctoral degrees — but the fields they earn their degrees in vary widely.
So, barring a data sciences degree program (which are popping up at prestigious universities around the world) what steps do you need to take to become a data scientist? OpenIntro. Ponavljanka, ki ni sestavljanka. Pred nekaj leti sem se prvič znašla v laboratoriju, v katerem naj bi izvedla raziskovalno nalogo, uporabila pa naj bi neko novo metodo.
Predstavljena je bila v objavi z znanstveni reviji. Ko smo začeli z delom, smo hitro ugotovili, da pri nas ta metoda ne deluje tako, kot jo je opisoval članek. To niti ni bilo tako nenavadno, a vseeno nas je ustavilo pri delu, kajti rezultatov, predstavljenih v primarni objavi, nismo uspeli ponoviti. Metodo smo nato prilagodili in z njo poiskušali odgovoriti na nova raziskovalna vprašanja, ki so se nam porajala na področju fizikalne biologije. Ponovljivost znanstvenih raziskav je ena izmed temeljnih zahtev trdih znanosti. Tako se je združilo več kot 270 raziskovalk in raziskovalcev, ki so pod vodstvom socialnega psihologa Braina Noseka ponovno izvedli 100 raziskav, ki so bile pred leti objavljene v treh psiholoških znanstvenih revijah.
Večjo ponovljivost so imele raziskave, ki so imele nižjo p-vrednost. To je to! Like this: Like Loading... Introduction to Data Analysis. François Briatte and Ivaylo PetevSciences Po, Euro-American Campus Spring 2013 This course is an introduction to analyzing data with the R software.

It features some mathematics and statistics as well as some statistical computing and data visualization. You will need a laptop with an Internet connection to follow the class. To get started, download the entire course. To take a look at what the course material is made of, view it on GitHub first. Tipične napake pri sestavljanju spletnih anketnih vprašalnikov – 2. del. V svoji prejšnji objavi sem poudarila pomen anketnih podatkov v družboslovni znanosti ter opozorila na naraščajoči obseg nekakovostnih spletnih vprašalnikov.

Opisala sem štiri pogoste napake neizkušenih ustvarjalcev spletnih anket: 1. preveliko število vprašanj na stran, 2. preveliko število vprašanj na vprašalnik, 3. nesmotrno rabo podpornih (grafičnih) elementov ter 4. neuporabo filtriranja s pogoji. Nadaljevala bom s predstavitvijo štirih tipičnih težav pri sestavljanju posameznih vprašanj – tudi v tem delu primeri temeljijo na anketah “The Status of Slovenian Women in Academic Fields of Science, Technology, Engineering and Mathematics” (WIS) in “Pojav podjetniške univerze in sodelovanje akademikov pri prenosu znanja in tehnologij” (PU):
Tipične napake pri sestavljanju spletnih anketnih vprašalnikov – 1. del. Brez podatkov ni statistike in ena izmed najpopularnejših metod zbiranja podatkov v sociologiji in drugih družboslovnih znanostih je anketni vprašalnik.

Kljub izraziti vlogi anketnega zbiranja podatkov v znanosti, se v praksi pogosto pozablja na testiranje ter druge postopke, s katerimi odkrivamo in preprečujemo napake. Nadalje smo z razvojem spletnih orodij, ki omogočajo hitro in relativno enostavno izvedbo anketne raziskave, priča porastu naredi-si-sam (do-it-yourself) vprašalnikov. Že tako nizko pripravljenost za sodelovanje v raziskavah tako še dodatno načenja obilica spletnih anket slabe kakovosti. Med ustvarjalci nekakovostnih vprašalnikov niso samo množice študentov, ki morajo izvesti projektno nalogo, ampak včasih grešijo tudi ugledne institucije, ki sestavljanje merskega instrumenta smatrajo bolj za veščino kot znanost.