
Facebook Graph Search Marries Big Data With NLP. Facebook recently launched its upcoming feature, currently in beta, called Graph Search.
The new feature allows anyone to perform a search on Facebook using simple text based queries. These differ from a conventional web search you normally do on Google or Bing in a way that you're not really entering keywords here. If you were to search on Facebook's Graph Search, you'd normally type - "My friends who like beer", "My friends who like beer and Apple", and so on. Facebook's Graph Search is a unique blend of big data and natural language processing (NLP). We had earlier reported how Facebook's Graph Search is a lean way to put its enormous amount of data to good use.
Using natural language processing (NLP), Facebook is slowly trying to bring users to a different side of the search world. Data is the center of every search function. Search is expected to grow in the coming years. In Depth: Data privacy: how safe is your data in the cloud? By Thomas L FriedmanMOUNTAIN VIEW, Calif: - How's my kid going to get a job?
There are few questions I hear more often than that one.In February, I interviewed Laszlo Bock, who is in charge of all hiring at Google - about 100 new hires a week - to try to understand what an employer like Google was looking for and why it was increasingly ready to hire people with no college degrees. Bock's remarks generated a lot of reader response, particularly his point that prospective bosses today care less about what you know or where you learned it - the Google machine knows everything now - than what value you can create with what you know. Your Cloud, Your Data, Your Way! Big Data Studio. Big Data at Aadhaar With Hadoop, HBase, MongoDB, MySQL, and Solr. It’s unfortunate that the post focuses mostly on the usage of Spring and RabitMQ and the slidedeck doesn’t dive deeper into the architecture, data flows, and data stores, but the diagrams below should give you an idea of this truly polyglot persistentency architecture: The slide deck presenting architecture principles and numbers about the platform after the break.

Original title and link: Big Data at Aadhaar With Hadoop, HBase, MongoDB, MySQL, and Solr (NoSQL database©myNoSQL) Hadoop Net. DeveloperWorks India. BD001V2EN - Hadoop Fundamentals I - Version 2: About this course. Innovation Insights - New Thinking for a New Era. What is MapReduce? Improving MySQL performance with Hadoop. Using Hadoop And PHP. Getting Started So first things first.
If you haven’t used Hadoop before you’ll first need to download a Hadoop release and make sure you have Java and PHP installed. To download Hadoop head over to: Click on download a release and choose a mirror. I suggest choosing the most recent stable release. User@computer:$ tar xpf hadoop-0.20.2.tar.gz I like to create a symlink to the hadoop-<release> directory to make things easier to manage. user@computer:$ link -s hadoop-0.20.2 hadoop Now you should have everything you need to start creating a Hadoop PHP job. Creating The Job For this example I’m going to create a simple Map/Reduce job for Hadoop. We want to read from an input system – this is our mapperWe want to do something with what we’ve mapped – this is our reducer At the root of your development directory, let’s create another directory called script.
User@computer:$ ls ...hadoop-0.20.2hadoop-0.20.2.tar.gzhadoop user@computer:$ mkdir script Now let’s being creating our mapper script in PHP. . #! #! As Memcached Alternative. Challenges with a memcached tier Reference Architecture The architecture diagram below depicts a memcached environment before and after the caching tier is replaced by Couchbase Server.
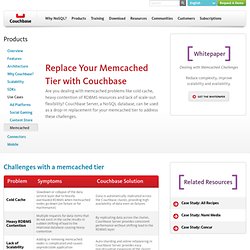
One of the use cases of Couchbase Server is to function as a caching layer within a typical web-based architecture, as shown above. The low latency, consistent performance and linear scalability of Couchbase Server make it suitable as a memcache tier replacement; its built-in caching technology enables sub-millisecond response times that match those of memcached. Data in Couchbase Server is automatically partitioned and distributed across cluster nodes. Additionally, the admin console in Couchbase Server enables you to monitor and manage at the cluster level (not the server level, as with memcached), simplifying your system management and operations, and saving you time. Hadoop Tutorial for Beginners -1. Large Scale Data Processing with Hadoop and PHP - David Zuelke. The MapReduce framework promises to make computing of large sets of data very easy.
The approach offers excellent scalability across many computing nodes, and can easily be integrated with existing systems. This session will give an introduction to the basic techniques and ideas behind MapReduce, followed by hands-on examples using Apache Hadoop, a major implementation of MapReduce, and Hadoop's streaming functionality that allows users to write processing jobs not just in Java, but in any programming language, including PHP.
Talk by David Zuelke at PHP UK Conference The MapReduce framework promises to make computing of large sets of data very easy. The approach offers excellent scalability across many computing nodes, and can easily be integrated with existing systems.