
Deep Learning Drizzle. One Shot Learning with Siamese Networks using Keras. Lecture04. Introducción al Deep Learning Parte 4: SOMs. Deep Learning Básico Parte Final: Autoencoders. Understanding and implementation of Residual Networks(ResNets) Data Augmentation y Transfer Learning con Keras / TensorFlow 2.0. Contenido abierto del Capítulo 6 del libro DEEP LEARNING Introducción práctica con KerasEste post es una versión preliminar del capítulo 6 del libro “Deep Learning – Introducción práctica con Keras (SEGUNDA PARTE)” que se publicará este otoño en Kindle Direct Publishing con ISBN 978-1-687-47399-8 en la colección WATCH THIS SPACE – Barcelona (Book 6).
Como autor agradeceré que cualquier error o comentario que el lector o lectora encuentre en este texto me lo comunique por email a libro.keras@gmail.com para mejorar su contenido. Muchas gracias de antemano. En este capítulo presentaremos DataAugmentation, una de las técnicas para mitigar el sobreajuste en los modelos de redes neuronales. En nuestro caso de estudio, esta técnica mejorará el modelo anterior que presentaba una Accuracy de 73.9%, alcanzando una Accuracy de 80.1%.
A continuación introduciremos dos variantes de la técnica llamada Transfer Learning que nos permitirán mejorar aún más el modelo anterior. 6.1 Data Augmentation. ¿Cuál es la diferencia entre aprendizaje de transferencia, adaptación de dominio, aprendizaje de tareas múltiples y aprendizaje semi-supervisado? Así es como entiendo estos términos: 1.

Aprendizaje de transferencia: cuando la salida de un tipo de algoritmo ayuda a aumentar la precisión de otro algoritmo. Técnicas de Regularización Básicas para Redes Neuronales. Generative Adversarial Networks. L13 Intro to Convolutional Neural Networks (Part 2) 2/2 [Stat453, SS20] ECE 6504 Deep Learning for Perception. Virginia Tech, Electrical and Computer Engineering.
Syllabus. The Spring 2020 iteration of the course will be taught virtually for the entire duration of the quarter.

(more information available here ) Unless otherwise specified the lectures are Tuesday and Thursday 12pm to 1:20pm. Discussion sections will (generally) be Fridays 12:30pm to 1:20pm. Check Piazza for any exceptions. Lectures and discussion sections will be both on Zoom, and they will be recorded for later access from Canvas. This is the syllabus for the Spring 2020 iteration of the course.
Deep Learning (with PyTorch) Deep Learning Crash Course. CS230: Deep Learning. CS294-158-SP20 Deep Unsupervised Learning Spring 2020. Q: How do I get into this course?
A: Please fill out this survey, which we will use for admissions. Q: Can undergraduates take this course? A: This course is targeted towards a PhD level audience. But certainly exceptional undergraduates could be good fits, too, and your ability to take this course is not directly affected by your grad/undergrad student status, but by things we 'll evaluate from the survey. Generative Adversarial Networks GAN - Santiago Pascual - UPC Barcelona 2018. ▶ Lecture 18: Videos - EECS 498.007 / 598.005: Deep Learning for Computer Vision - Fall 2019 Recordings - CAEN Lecture Viewer.
Don’t Overfit! — How to prevent Overfitting in your Deep Learning Models. I’m going to be talking about three common ways to adapt your model in order to prevent overfitting. 1: Simplifying the model The first step when dealing with overfitting is to decrease the complexity of the model.
In the given base model, there are 2 hidden Layers, one with 128 and one with 64 neurons. Additionally, the input layer has 300 neurons. Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates. Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates This post provides an overview of a phenomenon called “Super Convergence” where we can train a deep neural network in order of magnitude faster compared to conventional training methods.
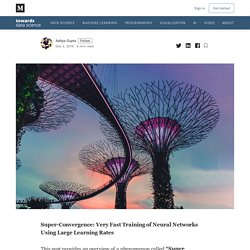
Introducing Activation Atlases. Read PaperView CodeTry Demo Modern neural networks are often criticized as being a “black box.”
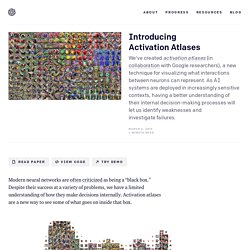
Despite their success at a variety of problems, we have a limited understanding of how they make decisions internally. Activation atlases are a new way to see some of what goes on inside that box. Activation atlases build on feature visualization, a technique for studying what the hidden layers of neural networks can represent. Early work in feature visualization primarily focused on individual neurons. Understanding what’s going on inside neural nets isn’t solely a question of scientific curiosity — our lack of understanding handicaps our ability to audit neural networks and, in high stakes contexts, ensure they are safe.
For example, a special kind of activation atlas can be created to show how a network tells apart frying pans and woks. How AI Training Scales. Read Paper In the last few years AI researchers have had increasing success in speeding up neural network training through data-parallelism, which splits large batches of data across many machines.

Researchers have successfully used batch sizes of tens of thousands for image classification and language modeling, and even millions for RL agents that play the game Dota 2. These large batches allow increasing amounts of compute to be efficiently poured into the training of a single model, and are an important enabler of the fast growth in AI training compute. However, batch sizes that are too large show rapidly diminishing algorithmic returns, and it’s not clear why these limits are larger for some tasks and smaller for others.
The gradient noise scale (appropriately averaged over training) explains the vast majority (r2 = 80%) of the variation in critical batch size over a range of tasks spanning six orders of magnitude. OpenAI Blog. OpenAI Progress. CNN Long Short-Term Memory Networks. Last Updated on August 14, 2019 Gentle introduction to CNN LSTM recurrent neural networks with example Python code.
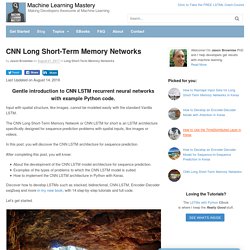
Input with spatial structure, like images, cannot be modeled easily with the standard Vanilla LSTM. The CNN Long Short-Term Memory Network or CNN LSTM for short is an LSTM architecture specifically designed for sequence prediction problems with spatial inputs, like images or videos. In this post, you will discover the CNN LSTM architecture for sequence prediction. After completing this post, you will know: About the development of the CNN LSTM model architecture for sequence prediction.Examples of the types of problems to which the CNN LSTM model is suited.How to implement the CNN LSTM architecture in Python with Keras. Discover how to develop LSTMs such as stacked, bidirectional, CNN-LSTM, Encoder-Decoder seq2seq and more in my new book, with 14 step-by-step tutorials and full code. Let’s get started. A 3D CNN-LSTM-Based Image-to-Image Foreground Segmentation. Keras, Regression, and CNNs. b903af1d8f26a8894a3773915c74f038883e.
Continuous video classification with TensorFlow, Inception and Recurrent Nets. Part 2 of a series exploring continuous classification methods. A video is a sequence of images. In our previous post, we explored a method for continuous online video classification that treated each frame as discrete, as if its context relative to previous frames was unimportant. Today, we’re going to stop treating our video as individual photos and start treating it like the video that it is by looking at our images in a sequence. GAN Lab: Play with Generative Adversarial Networks in Your Browser!
What is a GAN? Many machine learning systems look at some kind of complicated input (say, an image) and produce a simple output (a label like, "cat"). By contrast, the goal of a generative model is something like the opposite: take a small piece of input—perhaps a few random numbers—and produce a complex output, like an image of a realistic-looking face. A generative adversarial network (GAN) is an especially effective type of generative model, introduced only a few years ago, which has been a subject of intense interest in the machine learning community.
You might wonder why we want a system that produces realistic images, or plausible simulations of any other kind of data. Besides the intrinsic intellectual challenge, this turns out to be a surprisingly handy tool, with applications ranging from art to enhancing blurry images. Tdeboissiere/DeepLearningImplementations: Implementation of some deep learning models. Image-to-Image Translation with Conditional Adversarial Networks.
Image-to-Image Demo - Affine Layer. Interactive Image Translation with pix2pix-tensorflow The pix2pix model works by training on pairs of images such as building facade labels to building facades, and then attempts to generate the corresponding output image from any input image you give it. The idea is straight from the pix2pix paper, which is a good read. [1903.10274] A data-driven approach to precipitation parameterizations using convolutional encoder-decoder neural networks. Prl900/DeepWeather: Convolutional Neural Networks for Weather Forecasting. 1stDeepStructWS paper 2. Model Zoo - Deep learning code and pretrained models for transfer learning, educational purposes, and more.
Model Pruning in Keras with Keras-Surgeon - Anuj shah (Exploring Neurons) - Medium. Visual Interpretability for Convolutional Neural Networks. An introduction to visualization techniques in ConvNets In application programming, we have debugging and error checking statements like print, assert, try-catch, etc. Visualizing intermediate activation in Convolutional Neural Networks with Keras.
In this article we’re going to train a simple Convolutional Neural Network using Keras with Python for a classification task. For that we will use a very small and simple set of images consisting of 100 pictures of circle drawings, 100 pictures of squares and 100 pictures of triangles which I found here in Kaggle. These will be split into training and testing sets (folders in working directory) and fed to the network.
Most importantly, we are going to replicate some of the work of François Chollet in his book Deep Learning with Python in order to learn how our layer structure processes the data in terms of visualization of each intermediate activation, which consists of displaying the feature maps that are output by the convolution and pooling layers in the network. What this means is that we are going to visualize the result of each activation layer. A simple 2D CNN for MNIST digit recognition. Convolutional Neural Networks (CNNs) are the current state-of-art architecture for image classification task.
Whether it is facial recognition, self driving cars or object detection, CNNs are being used everywhere. In this post, a simple 2-D Convolutional Neural Network (CNN) model is designed using keras with tensorflow backend for the well known MNIST digit recognition task. The whole work flow can be: Preparing the dataBuilding and compiling of the modelTraining and evaluating the modelSaving the model to disk for reuse Preparing the data The data set used here is MNIST dataset as mentioned above. Common architectures in convolutional neural networks. In this post, I'll discuss commonly used architectures for convolutional networks.
As you'll see, almost all CNN architectures follow the same general design principles of successively applying convolutional layers to the input, periodically downsampling the spatial dimensions while increasing the number of feature maps. CS231n Convolutional Neural Networks for Visual Recognition. 3D Visualization of a Convolutional Neural Network. 2D Visualization of a Convolutional Neural Network. 2D Visualization of a Convolutional Neural Network. Picasso: A free open-source visualizer for Convolutional Neural Networks. While it’s easier than ever to define and train deep neural networks (DNNs), understanding the learning process remains somewhat opaque. 1901.02413. [1901.02413] Interpretable CNNs. Cs224w 47 final. Getting Started With Google Colab. You know it’s out there. You know there’s free GPU somewhere, hanging like a fat, juicy, ripe blackberry on a branch just slightly out of reach. The Building Blocks of Interpretability.
CS231n Convolutional Neural Networks for Visual Recognition. (this page is currently in draft form) Visualizing what ConvNets learn Several approaches for understanding and visualizing Convolutional Networks have been developed in the literature, partly as a response the common criticism that the learned features in a Neural Network are not interpretable. Jason Yosinski. Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson. Visual Interpretability for Convolutional Neural Networks. Visualizing intermediate activation in Convolutional Neural Networks with Keras. Getting the Most Out of Your Google Colab (Tutorial) Two months ago we started working on an academic project that makes use of deep neural networks.
To train our model, we used Google Colaboratory platform as it is the only free GPU platform we have found. After exploring a good tutorial for using this platform, we managed to find this excellent tutorial. Although very useful, we still found it difficult to train our model effectively. For that reason Ori Licht and myself are writing this tutorial, that will hopefully help you to get the most out of your Google Colab. Visualizing Convolutional Filters from a CNN - deeplizard. Class activation maps in Keras for visualizing where deep learning networks pay attention. □ From TensorFlow to PyTorch - HuggingFace - Medium. Zhixuhao/unet: unet for image segmentation. Divamgupta/image-segmentation-keras: Implementation of Segnet, FCN, UNet and other models in Keras. U-Net for segmenting seismic images with keras - Depends on the definition. U-net/data.py at master · yihui-he/u-net. Satellite Image Segmentation: a Workflow with U-Net. Top 10 Pretrained Models to get you Started with Deep Learning (Part 1 - Computer Vision)
A Non-Expert’s Guide to Image Segmentation Using Deep Neural Nets. A 2017 Guide to Semantic Segmentation with Deep Learning. Python Deep Learning Frameworks Reviewed. CS231n Convolutional Neural Networks for Visual Recognition.