
Le principe de la curation en une infographie. Le Web deviendra t-il bientôt le champs de bataille entre les antis et les pros curation ?
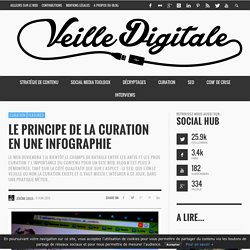
L’importance du contenu pour un site Web, blog n’est plus à démontrer, tant sur la côté qualitatif que sur l’aspect : le SEO. Que l’on le veuille ou non la curation existe et il vaut mieux l’intégrer à ce jour, dans une pratique métier. Pour Marc Rougier CEO de scoop.it la curation est la conjonction de trois axes : SélectionnerOrganiser / EditerPartager des contenus existants Nous pouvons définir 5 étapes dans la curation : Définir son sujet de veilleRécolter les sourcesSélectionner le contenuÉditorialiser le contenuPartager. La curation, pour éviter la noyade. Peu importe nos propres utilisations de l'Internet, parfois fantaisistes, parfois excessives, nous dépendons au quotidien de cet espace.
Quels outils pour quelle curation ? Face à la surabondance de l'information sur le web où l'internaute est à la fois et avec plus ou moins de bonheur consommateur, créateur et organisateur de ressources, comment trier/sélectionner, catégoriser et mettre en valeur selon les besoins individuels, socio-professionnels ou communautaires, mettre à disposition/partager/discuter la masse infinie de données disponibles ?
La veille documentaire sur le web assurée à tous les niveaux s'avère impérative mais reste insuffisante à plus d'un égard et depuis 2008 un nouveau concept s'est imposé pour optimiser notre gestion de l'information : la curation. Veille et curation en vidéos. Diigo, mode d'emploi pour utilisateurs avancés. En navigant sur Internet, on collecte une foule d'informations intéressantes, que l'on ne prend pas toujours la peine d'approfondir sur le moment mais que l'on souhaite conserver pour un examen ultérieur.
Si l'on prend effectivement cette peine, si de plus l'on fait du lien entre diverses informations ainsi collectées et entre celles-ci et ce que l'on sait déjà, nous voilà dans un magnifique processus d'apprentissage non formel, applicable en tous temps et en toutes circonstances. Le web nous transforme en effet potentiellement en puits de savoirs, dès lors que l'on sait utiliser les informations qu'il met à notre disposition. Mais encore faut-il collecter, classer et réutiliser les informations que l'on estime pertinentes, et pas seulement les collectionner dans un coin de sa machine ou dans les nuages, où elles vont doucement mourir faute de n'être pas utilisées.
Les listes Une solution s'offre à vous : classer vos signets dans des listes. Curation et droit d'auteur. Les différentes plateformes de curation manuelle (Scoop.it, Pearltrees) ou automatique (Paper.li) questionnent le droit d'auteur car ces services reproduisent du contenu protégé par le droit de la propriété intellectuelle.
Lionel Maurel (nous rendons compte d'un autre de ses articles ici), conservateur des bibliothèques à la Bibliothèque nationale de France essaie d'apporter quelques réponses juridiques à ce sujet sur son blog S.I.Lex. Scoop.it : un service aux "bases juridiques fragiles" Scoop.it est un service en ligne qui permet à l'usager du web de créer son propre magazine en ligne. Lors de l'ajout d'une actualité, l'outil se charge de récupérer le titre, l'image et parfois les premières lignes du texte sauf si le curateur choisit de personnaliser cette présentation.
Si le droit de courte citation peut éventuellement s'appliquer au niveau du titre et du texte, cette exception n'est pas à priori recevable au niveau graphique.
Veille et curation : Méthodologie de projet en 6 étapes. Jean-Christophe Dichant, éditeur et expert en gestion de contenu Web, a récemment consacré sur son blog un dossier complet à la méthodologie de veille et de la curation, un processus ordonné basé sur l’expérience professionnelle de l’auteur.

L’objectif est aussi bien de formaliser une démarche de veille et de curation que de se familiariser avec des outils en ligne pertinents à utiliser qui font gagner du temps et satisfont à ses thématiques de prédilection pour une collecte d’informations et leur diffusion. Méthodologie de curation de contenus Rappelons que la curation de contenus « consiste à sélectionner, éditer et partager les contenus les plus pertinents du Web pour une requête ou un sujet donné ». C’est par la pratique, avec astuces et conseils, que Jean-Christophe Dichant accompagne les internautes dans une approche projet cohérente en 6 articles explicatifs ; des tutoriels qui apposent un sens à la démarche et un apprentissage pas-à-pas des outils présentés. 1. 2. 3. 4. 5. 6.
Propulsion, Curation, Partage… et le droit dans tout ça. Alors que Google vient d’annoncer le lancement de son bouton de partage +1, à l’image du fameux like de Facebook, la juriste Murielle Cahen publie sur le site Avocat Online une intéressante analyse, qui confronte ce type de fonctionnalités avec les principes du droit d’auteur à la française.
Son raisonnement, finement nuancé, tend à prouver que plusieurs principes du droit d’auteur, et notamment le droit moral, fragilisent ces pratiques de propulsion des contenus en direction des réseaux sociaux. Trois usages professionnels de la curation. La curation est souvent présentée comme une pratique destinée aux « amateurs » , en raison de son adoption par un grand nombre de personnes, qui utilisent ce moyen de sélectionner, éditer et partager les contenus les plus pertinents du Web (selon la définition proposée par Wikipedia) pour diffuser les résultats d’une veille effectuée à titre personnel.
Or elle est aussi utilisée par des professionnels qui se servent de ce moyen simple de structurer et diffuser l’information dans le cadre de leurs activités professionnelles courantes. Des organisations peuvent aussi afficher aussi leur noms sur les dispositifs de curation, renforçant ainsi cette appropriation professionnelle. Ainsi, trois organismes, Marianne, Thot-Cursus, l’Urfist de Rennes se servent des outils : Pearltrees, Scoop-It et Diigo afin de classer, présenter du contenu web.
En choisissant ces dispositifs de curation, quels peuvent être leurs objectifs ? Scoop-It met en valeur les ressources du site Thot-Cursus.