
Ontology Instances. Smart data now! Graffoo - Graphical Framework for OWL Ontologies. Graffoo, a Graphical Framework for OWL Ontologies, is an open source tool that can be used to present the classes, properties and restrictions within OWL ontologies, or sub-sections of them, as clear and easy-to-understand diagrams.
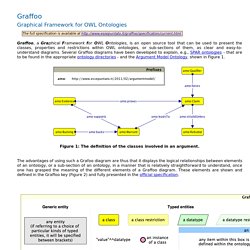
Several Graffoo diagrams have been developed to explain, e.g., SPAR ontologies - that are to be found in the appropriate ontology directories - and the Argument Model Ontology, shown in Figure 1. Figure 1: The definition of the classes involved in an argument. The advantages of using such a Grafoo diagram are thus that it displays the logical relationships between elements of an ontology, or a sub-section of an ontology, in a manner that is relatively straightforward to understand, once one has grasped the meaning of the different elements of a Graffoo diagram.
These elements are shown and defined in the Graffoo key (Figure 2) and fully presented in the official specification. Figure 2: The legend for all possible Graffoo objects How to install Graffoo. C Tracks@WWW2013, Brazil, 13-16 May 2013. 13-16 May 2013, Rio de Janeiro, Brazil At this year's 22th International World Wide Web Conference - WWW2013 , W3C organizes a W3C tutorial track and a W3C track where conference participants are invited to learn from, meet and discuss with our team of experts!

In addition , Tim Berners-Lee , W3C director and inventor of the Web, will participate in a "Net Neutrality and Internet Freedom" panel on Thursday 16 May, from 15h00 to 16h30, in the conference Segovias plenary room. All events will take place at the conference venue (Windsor Barra Hotel). The W3C tutorials will be held in the Alhambra I and Alhambra II rooms, on the 2nd floor. As for the W3C track, it will be held in the Imperial room, on the 1st floor . W3C Tutorial Track This track is supported by W3DevCampus , the W3C online training program for Web developers. Integrative Bioinformatics. Entanglement is an embarrassingly-scalable platform for graph-based data mining and data integration, developed by the integrative biology group at Newcastle University, allowing us to integrate datasets that were intractable using previous technologies.
Background Bioinformatics and biomedicine have a long history of using graph-based approaches to data integration. These have used a mixture of standard technologies (e.g. RDF, OWL, SQL) and more custom solutions (e.g. ONDEX, InterMine). At the same time as the bio datasets have been growing, grid and cloud services have been maturing. Entanglement has been designed to address this space. Architecture The entanglement architecture embraces grid environments, being built from symmetric VMs. Ontology - Home. Graph Databases: The New Way to Access Super Fast Social Data. Emil Eifrem is the founder of the Neo4j graph database project and CEO of Neo Technology, the world’s leading graph database.
Emil is an internationally recognized thought leader in new database technology, having spoken at conferences in three continents. Until the NOSQL wave hit a few years ago, the least fun part of a project was dealing with its database. Now there are new technologies to keep the adventuresome developer busy. The catch is, most of these post-relational databases, such as MongoDB, Cassandra, and Riak, are designed to handle simple data.
However, the most interesting applications deal with a complex, connected world. A new type of database significantly changes the standard direction taken by NOSQL. Pancake, for example, which is Mozilla’s next-generation browser project, uses a graph database to store browsing history in the cloud, since the web is just one big graph. It turns out that graphs are a very intuitive way to represent relationships between data. RDF triple stores — an overview. There's a huge range of triple stores out there, and it's not trivial to find the one most suited for your exact needs.
I reviewed all those I could find earlier this year for a project, and here is the result. I've evaluated the stores against the requirements that mattered for that particular project. I haven't summarized the scores, as everyone's weights for these requirements will be different. By a triple store I mean a tool that has some form of persistent storage of RDF data and lets you run SPARQL queries against that data. Open Linkeddata Definition. Selling RDF technology to Big Data. I think I've figured it out.

(This is a follow-up to my previous post SPARQL and Big Data (and NoSQL): How to pursue the common ground?) Here's how to sell the Semantic Web and Linked Data visions to the Big Data folk: don't. Sell them on RDF technology. Instead of telling these people about the Semantic Web or Linked Data visions, we should show them how we have technology that fulfills the vision that's apparently captured their imaginations. The process of selling a set of technologies usually means selling a vision, getting people psyched about that vision, and then telling them about the technology that implements that vision.
Big Data is itself a vision. Hadoop and NoSQL are currently the technologies being used to implement this vision. Besides PostgreSQL, the other database managers covered by the book are all considered to be NoSQL systems. It's a cliché in engineering-related sales that you have to focus on customer requirements. Open Linked Data Solutions - Chapter 23 (with image, tweets) · evectis. Open Linked Data Solutions - Chapter 24 (with image, tweets) · evectis. Open Linked Data Solutions - Chapter 25 (with image, tweets) · evectis. Open Linked Data Solutions - Chapter 26 (with images) · evectis. Open Linked Data Solutions - Chapter 27 (with images, tweets) · evectis. Open Linked Data Solutions - Chapter 28 · evectis. Open Linked Data Solutions - Chapter 29 (with images, tweets) · evectis.
Open Linked Data Solutions - Chapter 30 (with image, tweets) · evectis. Open Linked Data Solutions - Chapter 31 (with images) · evectis. Open Linked Data Solutions - Chapter 32 (with image, tweets) · evectis. Open Linked Data Solutions - Chapter 39 (with images, tweet) · evectis. Open Linked Data Solutions - Chapter 38 (with images, tweets) · evectis. Open Linked Data Solutions - Chapter 19 (with image, tweet) · evectis. Open Linked Data Solutions - Chapter 18 (with image, tweets) · evectis. Open Linked Data Solutions - Chapter 17 (with tweets) · evectis. Open Linked Data Solutions - Chapter 16 · evectis. Open Linked Data Solutions - Chapter 22 (with tweets) · evectis. Open Linked Data Solutions - Chapter 21 (with tweets) · evectis. Open Linked Data Solutions - Chapter 20 (with tweets) · evectis. Open Linked Data Solutions - Chapter 37 (with images, tweet) · evectis.
Open Linked Data Solutions - Chapter 36 (with images) · evectis. Open Linked Data Solutions - Chapter 35 (with image, tweets) · evectis. Is Linked Data the future of data integration in the enterprise? In today’s multi-screen world we need to be able to get relevant content to the customer, at the right time in their format and language of choice.

Life is no longer as simple as making PDF documents, we need to feed consistent information to all our multi-channel publications (web/mobile/print) and those of our partners. This blog post explains how NXP is tackling these challenges. At NXP, similar to many other large organizations, we have what you might call a ‘brownfield’ information landscape. Data and content is scattered and duplicated across numerous applications and databases leading to inconsistent information, complex systems and inefficient processes. The outcome is that people are unable to find what they are looking for, or find conflicting information. Our aim is to provide a single, up-to-date ‘canonical’ source of information that is easy to use and that data consumers (be they human or machine) can trust. Linked Data Patterns. Open Linked Data Solutions - Chapter 4 (with image, tweets) · evectis.
Open Linked Data Solutions - Chapter 3 (with tweets) · evectis. Open Linked Data Solutions - Chapter 2 (with tweets) · evectis. Open Linked Data Solutions - Chapter 1 (with tweets) · evectis. Graph Per Aspect. How can we avoid contention around updates to a single graph when applying the Graph Per Resource pattern?
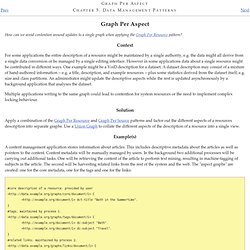
For some applications the entire description of a resource might be maintained by a single authority, e.g. the data might all derive from a single data conversion or be managed by a single editing interface. However in some applications data about a single resource might be contributed in different ways. One example might be a VoiD description for a dataset. A dataset description may consist of a mixture of hand-authored information -- e.g. a title, description, and example resources -- plus some statistics derived from the dataset itself, e.g. size and class partitions. An administrator might update the descriptive aspects while the rest is updated asynchronously by a background application that analyses the dataset. Multiple applications writing to the same graph could lead to contention for system resources or the need to implement complex locking behaviour. Linked Data Platform 1.0. 5.1 Introduction This section is non-normative.
Many HTTP applications and sites have organizing concepts that partition the overall space of resources into smaller containers. Blog posts are grouped into blogs, wiki pages are grouped into wikis, and products are grouped into catalogs. Each resource created in the application or site is created within an instance of one of these container-like entities, and users can list the existing artifacts within one. Containers answer some basic questions, which are: To which URLs can I POST to create new resources? This document defines the representation and behavior of containers that address these issues.
SEMIC - Semantic Interoperability Community. Description SEMIC is a European Commission initiative (funded under Action 1.1 and Action 2.15 of the ISA Programme) to improve the semantic interoperability of interconnected e-Government systems.

It focuses on the following activities: Raise awareness on the need for semantic interoperability; Encourage sharing and reuse by making collections of reusable interoperability solutions searchable on Joinup. Develop, promote and use core vocabularies at the European, national and local level to reach a minimum level of semantic interoperability. Foster the interoperability of open data portals by building consensus on the DCAT Application profile for data portals in Europe (DCAT-AP). An overview of the most relevant publications, presentations and pilots is accessible throughout the top menu of the community.
Open Linked Data Solutions - Chapter 34 (with image, tweet) · evectis. Open Linked Data Solutions - Chapter 33 (with images) · evectis. Open Linked Data Solutions - Chapter 15 (with tweets) · evectis. Open Linked Data Solutions - Chapter 14 (with tweets) · evectis. Open Linked Data Solutions - Chapter 13 (with tweets) · evectis. Open Linked Data Solutions - Chapter 12 (with tweets) · evectis. Open Linked Data Solutions - Chapter 11 (with image, tweets) · evectis. Open Linked Data Solutions - Chapter 10 (with tweets) · evectis. Open Linked Data Solutions - Chapter 9 (with tweet) · evectis. Open Linked Data Solutions - Chapter 8 (with tweets) · evectis. Open Linked Data Solutions - Chapter 7 (with tweets) · evectis. Open Linked Data Solutions - Chapter 6 (with tweets) · evectis. Open Linked Data Solutions - Chapter 5 (with image, tweets) · evectis.
INFOrmation SHAR(E)ing STRATegy.
Spinner, a SPARQL 1.1 compliant query processor and optimizer. Overview Spinner is a SPARQL query processor.
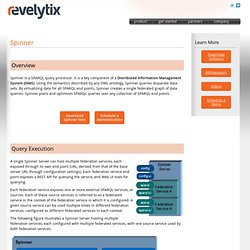
It is a key component of a Distributed Information Management System (DIMS). Using the semantics described by any OWL ontology, Spinner queries disparate data sets. By virtualizing data for all SPARQL end points, Spinner creates a single federated graph of data queries. Spinner plans and optimizes SPARQL queries over any collection of SPARQL end points.
Query Execution A single Spinner Server can host multiple federation services, each exposed through its own end point (URL, derived from that of the base server URL through configuration settings). Each federation service exposes one or more external SPARQL services, or sources. The following figure illustrates a Spinner Server hosting multiple federation services, each configured with multiple federated services, with one source service used by both federation services. Using Spinner Install in your shop and connect it up! Support.