
SPARQL playground. RDFShape: Query. Undefined - documentation. This page will guide you through running RDFox for the first time.

Before you begin, make sure that you have downloaded the latest RDFox release from www.oxfordsemantic.tech/downloads and unpacked it into a directory of your choosing. We'll refer to the directory as <working_directory> in what follows. You will also need to add a valid license file to <working_directory>. Free evaluation licenses can be requested here. Loading The first step is to load some data into RDFox so that we can query it and, later, enrich it with rules. @prefix : < . Start by copying the Turtle snippet above into a new file, <working_directory>/data.ttl.Next, open your favourite terminal, change to <working_directory> and start the RDFox shell using: . Querying Reasoning Reasoning is the ability to calculate the logical consequences of applying a set of rules to a set of facts.
With reasoning we can have the best of both worlds. Wikidata/Notes/DBpedia and Wikidata. DBpedia is a great and active project dealing with structured data and Wikipedia.
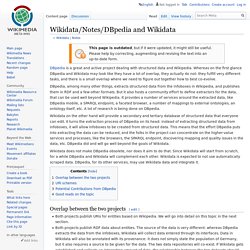
Whereas on the first glance DBpedia and Wikidata may look like they have a lot of overlap, they actually do not: they fulfill very different tasks, and there is a small overlap where we need to figure out together how to best co-evolve. DBpedia, among many other things, extracts structured data from the infoboxes in Wikipedia, and publishes them in RDF and a few other formats.
Galbiston/geosparql-jena: Implemenation of GeoSPARQL 1.0 standard using Apache Jena for SPARQL query or API. Geospatial: A Primer - Stardog. SPARQL/Aggregate functions. Aggregate functions are used in combination with modifier GROUP BY.
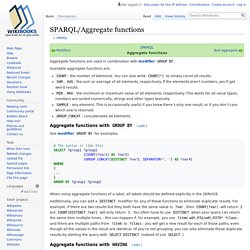
Available aggregate functions are: COUNT: the number of elements. You can also write COUNT(*) to simply count all results.SUM, AVG: the sum or average of all elements, respectively. If the elements aren’t numbers, you’ll get weird results.MIN, MAX: the minimum or maximum value of all elements, respectively. This works for all value types; numbers are sorted numerically, strings and other types lexically.SAMPLE: any element. SPARQL. Introduction Stardog Knowledge Graph supports the SPARQL query language, a W3C standard for querying RDF graphs.
In the Graph Data Model tutorial we looked at the details of RDF graphs and in this tutorial we will learn how to query them. Setup We will use the music dataset in this tutorial and see many features of SPARQL with examples. We will begin the tutorial using the small Beatles graph and then move to the slightly larger music dataset that we created from DBPedia. To refresh, the Beatles graph looks as follows: We highly recommend you to try the queries on your own to better understand the concepts we cover in this tutorial. RedStore. What is RedStore ?
RedStore is a lightweight RDF triplestore written in C using the Redland library. It has a HTTP interface and supports the following W3C standards: Features Built-in HTTP serverMac OS X app availableSupports a wide range of RDF formatsOnly runtime dependancy is Redland.Compatible with rdfproc command line tool for offline operationsUnit and integration test suite. MyExperiment How To SPARQL. The purpose of the GROUP BY clause is to allow aggregation over one or more properties.
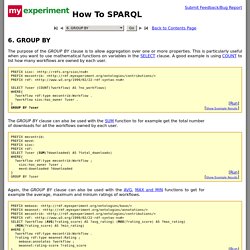
This is particularly useful when you want to use mathematical functions on variables in the SELECT clause. A good example is using COUNT to list how many workflows are owned by each user. [Run][Show Example Results][Hide Example Results] The GROUP BY clause can also be used with the SUM function to for example get the total number of downloads for all the workflows owned by each user. Whikloj/Sparql_101: Querying and SPARQL Update - IslandoraCon 2017. SPARQL/Expressions and Functions. Expressions[edit] BIND[edit] The BIND( expression AS ?
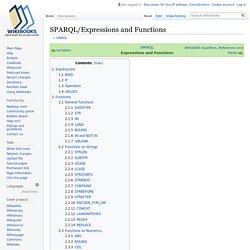
Variable ). clause can be used to assign the result of an expression to a variable (usually a new variable, but you can also overwrite existing ones). Try it! Wikidata Query Service. SPARQL Tips Tricks and Tools. SPARQL Tutorial - Datasets. This section covers RDF Datasets - an RDF Dataset is the unit that is queried by a SPARQL query.
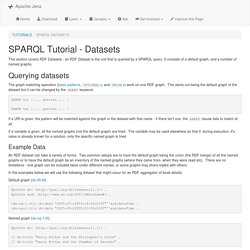
It consists of a default graph, and a number of named graphs. Querying datasets The graph matching operation (basic patterns, OPTIONALs, and UNIONs) work on one RDF graph. This starts out being the default graph of the dataset but it can be changed by the GRAPH keyword. GRAPH uri { ... pattern ... } GRAPH var { ... pattern ... } Using SPARQL to access Linked Open Data. Lesson Goals This lesson explains why many cultural institutions are adopting graph databases, and how researchers can access these data though the query language called SPARQL.
Table of contents Many cultural institutions now offer access to their collections information through web Application Programming Interfaces. While these APIs are a powerful way to access individual records in a machine-readable manner, they are not ideal for cultural heritage data because they are structured to work for a predetermined set of queries. For example, a museum may have information on donors, artists, artworks, exhibitions, and provenance, but its web API may offer only object-wise retrieval, making it difficult or impossible to search for associated data about donors, artists, provenance, etc. RDF databases are well-suited to expressing complex relationships between many entities, like people, places, events, and concepts tied to individual objects. Vapour, a Linked Data validator.
SparqlImplementations. This page lists some implementations of SPARQL, a query language and protocol for RDF acccess released by the W3C RDF Data Access Working Group - DAWG.
SPARQL query language spec SPARQL Protocol spec SPARQL XML results spec SPARQL Implementation Survey See DawgShows for online demos and services. Client Side Gruff provides a Graphical Query View which allows creating SPARQL and Prolog queries as diagrams of nodes and links. YASGUI. NeXtProt SnorQL. What happens if one endpoint fails in federated query. Uk-bnb provided by the Talis Platform. Revisiting Blank Nodes in RDF to Avoid the Semantic Mismatch with SPARQL. WED 730 Wallace 3780. If statement - Binding a variable to one of two values with IF? Linked Data Fragments. Wikibase/Indexing/SPARQL Query Examples. Syntax according to RDF Dump format. See also Further examples can be found at d:Wikidata:SPARQL query service/queries This page is parsed by the web interface of the query service to fill its drop down of example queries.
Keywords in the line below the header are used to be populate the keyword cloud. Consider adding a comment in the query noting what it illustrates, when and by whom it was written and which are its limitations given the current data and use of properties at Wikidata. WDQ queries: Standard Prefixes[edit] These are standard prefixes, however their use is optional as the query endpoint knows to resolve standard prefixes automatically.
Wikidata Query Service (Beta) Normalizing company names with SPARQL and DBpedia. The query below can be run with any SPARQL client that supports 1.1. I wanted it to cover these three cases: Run it with an unofficial company name such as Big Blue, Apple Computer, or Kodak, and it should return the official company name.Run it with an official company name such as IBM, Apple, Inc., or Eastman Kodak, and it should return that name. Run it with something that isn't a company, such as Snee, and it shouldn't return anything. The query's first BIND statement sets the name to check (including a language tag, because DBpedia is pretty consistent about using those) in the ? InputName variable, and the SERVICE keyword sends the bolded part of the query off to DBpedia's SPARQL endpoint.
After finding a resource (? If that graph pattern doesn't return anything because ? After DBpedia returns any bound variables, the local client uses the COALESCE function to bind ? I tested this with both ARQ and TopBraid Composer. Please add any comments to this Google+ post. SEMAKU — Using COALESCE and IF in SPARQL for nested... For a current project we need to load data from an RDF graph store to populate tables in an existing SQL database. The approach we chose is to use SPARQL SELECT queries to express the mapping from the graph to tabular model. The CSV results from such a query can be used to populate the tables in the target database. One of the columns in the target table contains coded values, where each code indicates the ‘type’ of the thing the row describes.
The codes are two or three letters (e.g. FE, FA, NMF) where each code has a predetermined meaning. However the RDF data used more types than in the target database, so it was necessary to create an n:1 mapping. Rdf - Populating an OWL ontology from external SPARQL endpoints. Jena - Is there any free owl reasoner that can reason without load all data into memory? Reasoning and SPARQL through ARQ command line. I'm just getting started with ontologies, so forgive me if I'm missing something blatantly obvious here. I've been experimenting with Protégé, setting up a simple ontology. Among other things, I've got ? X knows ? Y triples, where knows is a symmetric relationship. If I invoke Pellet from Protégé, it indeed infers (for some sample individuals I created) that if ?
Now I'd like to get the same result from ARQ, so I can do some basic tests from the command line. Vocabulary of Interlinked Datasets (VoID) Sparql Services. The datasets are available as linked data - that is in RDF (Resource Description Framework). Datasets. A list of datasets is given below. To find out more about what is in those datasets and how to access them follow the links. Underpinning the datasets is our RDF store - 5Store. 5Store is the very latest software from Garlik and is built upon the experience of their earlier open source versions such as 4Store. 5Store takes the capabilities of RDF stores to the next level, being capable of storing up to 1 trillion triples and providing scalability through an extensible cluster design. 5Store is itself under active development with Garlik and their partners, such as TSO, constantly monitoring changes in RDF store technologies and updating the software as applicable.
The British National Bibliography. Accessing the British National Bibliography Using SPARQL – Lost Boy. This is the third in a series of posts (1, 2, 3, 4) providing background and tutorial material about the British National Bibliography. The tutorials were written as part of some freelance work I did for the British Library at the end of 2012. The material was used as input to creating the new documentation for their Linked Data platform but hasn’t been otherwise published.
They are now published here with permission of the BL. Managing RDF Using Named Graphs. [protege-owl] Tutorial for using SPARQL with OWL. Tools. The OpenUp Client makes use of several features of OpenUp that we're working on, including the Data Enrichment Service (DES) and the RDF store. A Narrative for Understanding SPARQL’s: FROM, FROM NAMED and GRAPH. RDFS, Jena: how to query taking ontology into account. SPARQL query RDF ontology. How to query Classes with Object Property in Sparql - JJask.com. How to query Classes with Object Property in Sparql - JJask.com. Difference between domain and range in rdf schema? Can we combine CONSTRUCT with aggregates in SPARQL 1.1? SPARQL tips and tricks. SPARQL — Personal Wiki. Learn about SPARQL 1.1. RDF Validator. Putting WorldCat Data Into A Triple Store. By Richard Wallis on August 21, 2012 - 14 Comments Published in Consuming Data, Data Publishing, Libraries, Linked Data, OCLCTagged: 4Store, Linked Data, OCLC, RDF, SPARQL, WorldCat I can not really get away with making a statement like “Better still, download and install a triplestore [such as 4Store], load up the approximately 80 million triples and practice some SPARQL on them” and then not following it up.
I made it in my previous post Get Yourself a Linked Data Piece of WorldCat to Play With in which I was highlighting the release of a download file containing RDF descriptions of the 1.2 million most highly held resources in WorldCat.org – to make the cut, a resource had to be held by more than 250 libraries. Semantic Web Practice - Other SPARQL Query Forms (CONSTRUCT, ASK, DESCRIBE) SPARQL Query Examples - Knowledge Wiki - Base22 Wiki. SPARQL Query Examples - Knowledge Wiki - Base22 Wiki. AllegroGraph 4.14.1.
SPARQL Cheat Sheet. Er. SparklePrettyPrinterV4 - sparkle-g - SPARKLE-G Pretty Printer and Syntactic Validator for SPARQL built on ANTLR V4 - The SPARQL (pron: sparkle) query language ANTLR4 Grammar. 4store - Scalable RDF storage. Loading the British National Bibliography into an RDF Database. How to install Jena Fuseki - TheInfoHunger. Fuseki – it really is that easy! SparqlImplementations - W3C Wiki. Milan Markovic - Guides:How to. Query Form - SPARQL Endpoint - Revyu.com. The British National Bibliography. GeoSPARQL. GeoSPARQL - A Geographic Query Language for RDF Data. SPARQL 1.1 Query Language. Home.