Codage, encodage de caractères : UNICODE, ASCII, UTF-8 etc...
HTML Symbols, Entities, Characters and Codes — HTML Arrows. Character Entity Reference Chart. Unicode - Compart. Unicode® Character Table. ✿ Our favorite set — CopyPasteCharacter.com. Glyphs. By Chris Coyier Last Updated On ascii, glyphs, unicode #Special Characters.
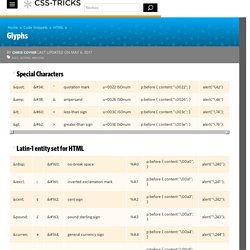
Sans titre. Caractères spéciaux et entités HTML. Character Entities in HTML & XHTML - The Web Standards Project. Single characters can be embedded into documents using character entity references.
These references have a numeric value as well as a named value. You can use either one just so long as it is allowed within the DTD in question. Using character entities is particularly helpful when the encoding set doesn’t express all the characters that you might want to use in the document. For example, if I were authoring a document in English and wanted to use an inverted exclamation mark for a Spanish quotation, I’d use an entity to create that character. Other character entity references help control space, symbols, and so on. There are three types of character entities available in HTML and XHTML.
Markup-Specific Entities in HTML & XHTML - The Web Standards Project. Symbol Entities in HTML & XHTML - The Web Standards Project.
Named Entities in HTML & XHTML - The Web Standards Project. Entities · WebPlatform Docs. UTF-8. L’UTF-8 est utilisé par 82,2 % des sites web en décembre 2014[2], 87,6 % en 2016[3], 90,5 % en 2017[4] et près de 93,1% en février 2019[5].
Par sa nature, UTF-8 est d’un usage de plus en plus courant sur Internet, et dans les systèmes devant échanger de l'information. Il s’agit également du codage le plus utilisé dans les systèmes GNU, Linux et compatibles pour gérer le plus simplement possible des textes et leurs traductions dans tous les systèmes d’écritures et tous les alphabets du monde.
ISO/CEI 8859-1. La norme ISO 8859-1, dont le nom complet est ISO/CEI 8859-1, et qui est souvent appelée Latin-1 ou Europe occidentale, forme la première partie de la norme internationale ISO/CEI 8859, qui est une norme de l’Organisation internationale de normalisation pour le codage des caractères en informatique.
Dans les pays occidentaux, cette norme était utilisée par de nombreux systèmes d’exploitation, dont UNIX, Windows ou AmigaOS. Elle a donné lieu à quelques extensions et adaptations, dont Windows-1252 et ISO 8859-15. La distinction entre ASCII, ISO 8859-1, ISO 8859-15, Windows-1252 et MacRoman est une source de confusion parmi les développeurs de programmes informatiques. Le Multinational Character Set créé par Digital Equipment Corporation pour le terminal informatique VT220 est considéré comme à la fois l’ancêtre d’ISO 8859-1 et d’Unicode[2].
Aujourd’hui, son utilisation tend à décroître au profit d’Unicode.
ISO/CEI 8859-15. Différences avec ISO 8859-1[modifier | modifier le code] Le jeu de caractères ISO/CEI 8859-15 peut être considéré comme une mise à jour de la norme ISO 8859-1, avec laquelle il est identique à l'exception de huit caractères[1].
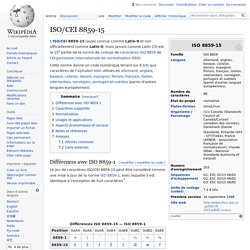
Note : les codes numériques sont donnés en base hexadécimale. En revanche, quelques caractères peu utilisés ont été exclus.
Windows-1252. Un article de Wikipédia, l'encyclopédie libre.
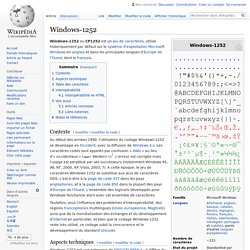
Windows-1252 ou CP1252 est un jeu de caractères, utilisé historiquement par défaut sur le système d'exploitation Microsoft Windows en anglais et dans les principales langues d’Europe de l’Ouest, dont le français. Contexte[modifier | modifier le code] Au début des années 1990, l'utilisation du codage Windows-1252 se développe en Occident, avec la diffusion de Windows 3.x.
Ascii Table - ASCII character codes and html, octal, hex and decimal chart conversion. The Digital Rosetta Stone. ASCII Code - The extended ASCII table. Handling character encodings in HTML and CSS (tutorial)
Intended audience: HTML and CSS content authors.

This material is applicable whether you create documents in an editor, or via scripting. This tutorial gathers together and organizes pointers to articles that, taken together, help you understand how to handle the essential aspects of authoring HTML and CSS related to characters and character encodings. In a nutshell Save your pages as UTF-8. Always declare the encoding of your document. You can use @charset or HTTP headers to declare the encoding of your style sheet, but you only need to do so if your style sheet contains non-ASCII characters and, for some reason, you can't rely on the encoding of the HTML and the associated style sheet to be the same.
Keycodes - Javascript Keyboard Codes, Character Codes, Unicode, HTML Entities. Glyphs. Caractères spéciaux et entités HTML - Doc Alex. Caractères Iso et Unicode. HTML Codes - Table of ascii characters and symbols. Table de caractères Unicode®
ISO/CEI 8859-15. ISO/CEI 8859-1. UTF-8. Code ASCII. Juillet 2017 Le morse a été le premier codage à permettre une communication longue distance.
C'est Samuel F.B.Morse qui l'a mis au point en 1844. Ce code est composé de points et de tirets (un codage binaire en quelque sorte...). Il permit d'effectuer des communications beaucoup plus rapides que ne le permettait le système de courrier de l'époque aux Etats-Unis : le Pony Express. L'interpréteur était l'homme à l'époque, il fallait donc une bonne connaissance du code... De nombreux codes furent inventés dont le code d'Émile Baudot (portant d'ailleurs le nom de code Baudot, les anglais l'appelaient en revanche Murray Code). Le 10 mars 1876, le Dr Graham Bell met au point le téléphone, une invention révolutionnaire qui permet de faire circuler de l'information vocale dans des lignes métalliques.
American Standard Code for Information Interchange. Un article de Wikipédia, l'encyclopédie libre.
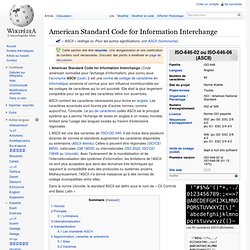
Les 95 caractères ASCII affichables : !
"#$%&'()*+,-./ 0123456789:;<=>? @ABCDEFGHIJKLMNO PQRSTUVWXYZ[\]^_ `abcdefghijklmno pqrstuvwxyz{|}~ Cette section doit être recyclée. L'American Standard Code for Information Interchange (Code américain normalisé pour l'échange d'information), plus connu sous l'acronyme ASCII ([askiː]) est une norme de codage de caractères en informatique ancienne et connue pour son influence incontournable sur les codages de caractères qui lui ont succédé. ASCII contient les caractères nécessaires pour écrire en anglais. L'ASCII est une des variantes de l'ISO/CEI 646.
Unicode. Un article de Wikipédia, l'encyclopédie libre.
Unicode est un standard informatique qui permet des échanges de textes dans différentes langues, à un niveau mondial. Il est développé par le Consortium Unicode, qui vise à permettre le codage de texte écrit en donnant à tout caractère de n'importe quel système d'écriture un nom et un identifiant numérique, et ce de manière unifiée, quelle que soit la plate-forme informatique ou le logiciel.
Codage des caractères. Il est indispensable, pour l'échange d'information sur l'Internet, par exemple, de préciser le codage utilisé. Ne pas le faire peut rendre un document difficilement lisible (remplacement des lettres accentuées par d'autres suites de caractères connu sous le nom de mojibake).
Toutefois, la convergence vers un standard commun devrait enfin répondre à ce problème. Dans certains contextes (en particulier dans les communications et dans l'utilisation de données informatiques), il est important de distinguer un répertoire de caractères, qui est un jeu complet de caractères abstraits qu'un système supporte, et un jeu de caractères codés ou codage de caractères qui spécifie comment représenter un caractère en utilisant un entier. Principe[modifier | modifier le code] Le codage des caractères est une convention qui permet, à travers un codage connu de tous, de transmettre de l'information textuelle, là où aucun support ne permet l'écriture scripturale.
