Zoom
Trash

Interactive computation. In computer science, interactive computation is a mathematical model for computation that involves communication with the external world during the computation.
This is in contrast to the traditional understanding of computation which assumes a simple interface between a computing agent and its environment, consisting in asking a question (input) and generating an answer (output). The famous Church-Turing thesis attempts to define computation and computability in terms of Turing machines. However the Turing machine model only provides an answer to the question of what computability of functions means and, with interactive tasks not always being reducible to functions, it fails to capture our broader intuition of computation and computability.
While this fact was admitted by Alan Turing himself, it was not until recently that the theoretical computer science community realized the necessity to define adequate mathematical models of interactive computation. See also[edit] CISD: Resources. Corpus linguistics. Corpus linguistics is the study of language as expressed in samples (corpora) of "real world" text.
This method represents a digestive approach to deriving a set of abstract rules by which a natural language is governed or else relates to another language. Originally done by hand, corpora are now largely derived by an automated process. Corpus linguistics adherents believe that reliable language analysis best occurs on field-collected samples, in natural contexts and with minimal experimental interference.
Within corpus linguistics there are divergent views as to the value of corpus annotation, from John Sinclair[1] advocating minimal annotation and allowing texts to 'speak for themselves', to others, such as the Survey of English Usage team (based in University College, London)[2] advocating annotation as a path to greater linguistic understanding and rigour. History[edit] A landmark in modern corpus linguistics was the publication by Henry Kucera and W. Talk:Programming language/Archive 5.
Lead section again Again, I'm not a big fan of italics, but it's good enough so I won't quibble.
Ideogram 01:46, 22 June 2006 (UTC) I feel this article is in good shape now and all outstanding issues have been resolved. The only major obstacle to FAC status now is the paucity of citations. Ideogram 02:09, 22 June 2006 (UTC) Actually the lead could use some work. Search engine (computing) A search engine is an information retrieval system designed to help find information stored on a computer system.
The search results are usually presented in a list and are commonly called hits. Search engines help to minimize the time required to find information and the amount of information which must be consulted, akin to other techniques for managing information overload. [citation needed] The most public, visible form of a search engine is a Web search engine which searches for information on the World Wide Web.
Search algorithm. Classes of search algorithms[edit] For virtual search spaces[edit] Algorithms for searching virtual spaces are used in constraint satisfaction problem, where the goal is to find a set of value assignments to certain variables that will satisfy specific mathematical equations and inequations.
They are also used when the goal is to find a variable assignment that will maximize or minimize a certain function of those variables. Algorithms for these problems include the basic brute-force search (also called "naïve" or "uninformed" search), and a variety of heuristics that try to exploit partial knowledge about structure of the space, such as linear relaxation, constraint generation, and constraint propagation. Sorting algorithm. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order);The output is a permutation (reordering) of the input.
Further, the data is often taken to be in an array, which allows random access, rather than a list, which only allows sequential access, though often algorithms can be applied with suitable modification to either type of data. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement.
Search suggest drop-down list. A search suggest drop-down list is a query feature used in computing.
A quick system to show the searcher shortcuts, while the query is typed. Before the query has been typed, a drop-down list with the suggested complete search queries, is given as options to select and access. The suggested queries then enable the searcher to complete the required search quickly. Text mining. A typical application is to scan a set of documents written in a natural language and either model the document set for predictive classification purposes or populate a database or search index with the information extracted.
Text mining and text analytics[edit] The term text analytics describes a set of linguistic, statistical, and machine learning techniques that model and structure the information content of textual sources for business intelligence, exploratory data analysis, research, or investigation.[1] The term is roughly synonymous with text mining; indeed, Ronen Feldman modified a 2000 description of "text mining"[2] in 2004 to describe "text analytics.
Talk:Programming language/Archive 5. Syntax highlighting. Syntax highlighting is a feature of text editors that displays text, especially source code, in different colors and fonts according to the category of terms.[1] This feature facilitates writing in a structured language such as a programming language or a markup language as both structures and syntax errors are visually distinct.
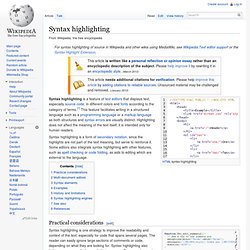
Highlighting does not affect the meaning of the text itself; it is intended only for human readers. Syntax highlighting is a form of secondary notation, since the highlights are not part of the text meaning, but serve to reinforce it. Some editors also integrate syntax highlighting with other features, such as spell checking or code folding, as aids to editing which are external to the language. Practical considerations[edit] Highlighting the effect of missing delimiter in JavaScript Syntax highlighting is one strategy to improve the readability and context of the text; especially for code that spans several pages. Generalized quantifier. Every boy sleeps.
This treatment of quantifiers has been essential in achieving a compositional semantics for sentences containing quantifiers.[1][2] Type theory[edit] Quantification. In logic, quantification is the binding of a variable ranging over a domain of discourse. The variable thereby becomes bound by an operator called a quantifier. Academic discussion of quantification refers more often to this meaning of the term than the preceding one. Information extraction. Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents. In most of the cases this activity concerns processing human language texts by means of natural language processing (NLP).
Recent activities in multimedia document processing like automatic annotation and content extraction out of images/audio/video could be seen as information extraction. Due to the difficulty of the problem, current approaches to IE focus on narrowly restricted domains. An example is the extraction from news wire reports of corporate mergers, such as denoted by the formal relation:
Concept mining. Concept mining is an activity that results in the extraction of concepts from artifacts. Solutions to the task typically involve aspects of artificial intelligence and statistics, such as data mining and text mining.[1] Because artifacts are typically a loosely structured sequence of words and other symbols (rather than concepts), the problem is nontrivial, but it can provide powerful insights into the meaning, provenance and similarity of documents.
Methods[edit] Traditionally, the conversion of words to concepts has been performed using a thesaurus,[2] and for computational techniques the tendency is to do the same. The thesauri used are either specially created for the task, or a pre-existing language model, usually related to Princeton's WordNet. The mappings of words to concepts[3] are often ambiguous. More News Is Being Written By Robots Than You Think. It’s easy to praise robots and automation when it isn’t your ass on the line. I’ve done it lots. But I may have to eat my own Cheerios soon enough. Web scraping. Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites.[1] Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis. Web scraping a web page involves fetching it and extracting from it.[1][2] Fetching is the downloading of a page (which a browser does when you view the page). Regular expression. Website Parse Template. » POS Tagging XML with xGrid and the Stanford Log-linear Part-Of-Speech Tagger Matthew L. Jockers. Semantic network.
Part-of-speech tagging. Once performed by hand, POS tagging is now done in the context of computational linguistics, using algorithms which associate discrete terms, as well as hidden parts of speech, in accordance with a set of descriptive tags. Part-of-speech tagging. POS tagger (Java. OpenNLP Developer Documentation.
To explain what maximum entropy is, it will be simplest to quote from Manning and Schutze* (p. 589): “ Maximum entropy modeling is a framework for integrating information from many heterogeneous information sources for classification. Www.phontron.com/slides/nlp-programming-en-05-hmm.pdf. Artificial intelligence : FileHungry Scripts Search. Web Resource Listings. Speech Recognition By Java - Simplified. Speech recognition is one of the challenging areas in computer science, a lot of pattern recognition methodology tried to resolve a good way and higher percentage of recognition.
One of the best ways to be use is Hidden Markov Model : "The process of speech recognition is to find the best possible sequence of words (or units) that will fit the given input speech. Download Java Speech Recognition Code Sample Software: Say-Now Voice And Speech Recognition, Embedded Speech Recognition Kit, Java Speech API. The Watchmaker Framework for Evolutionary Computation (evolutionary/genetic algorithms for Java) GAJIT. This page is for a mini-project I undertook when I had a spare moment or two to port the C++ based genetic algorithm library GAGS to Java.
Tutorials - Genetic Algorithms Warehouse. Grammatical Analysis - Funpoper.com. Ralph Debusmann - Extensible Dependency Grammar (XDG) Extensible Dependency Grammar (XDG) is a general framework for dependency grammar, with multiple levels of linguistic representations called dimensions, e.g. grammatical function, word order, predicate-argument structure, scope structure, information structure and prosodic structure.
Dependency Parsing: Recent Advances (Artificial Intelligence) Annotated data have recently become more important, and thus more abundant, in computational linguistics . Part of speech. Operator grammar.
Nlp theories. Model theory. First-order logic. Jason Shaw, Author at Theory of Thought. Mind. Genetic enhancement of learning and memory : the NMDA receptor NR2B. Cell signaling. Definitions of Basic Sentence Parts: Word Functions and Usage Notes. Definitions of Basic Sentence Parts: Word Functions and Usage Notes. Context Free Grammar - Introduction to Software - Free Computer Science Tutorials - Provided by Laynetworks.com. Context Free Grammar - Introduction to Software - Free Computer Science Tutorials - Provided by Laynetworks.com. Www.semanticsoftware.info/system/files/cai11-saeclipse.pdf. XML Parser. Rodos.cs.pitt.edu:8090/aps/bib/02b15eaa1a5ce8ff011a5f79c49a0037/QS.pdf. Comparison of parser generators. LING 1330 Introduction to Computational Linguistics, University of Pittsburgh.
NLPInterfacePack: C++ Interfaces and Implementation for Non-Linear Programs: NLPInterfacePack. Natural Language Toolkit — NLTK 3.0 documentation. Syntactic Analysis - Context-Free Grammars and Parsing. Context-free grammar. The Stanford NLP (Natural Language Processing) Group. Wiredesignz / codeigniter-modular-extensions-hmvc. OpenJDK: Project Jigsaw. OpenJDK: Project Jigsaw. Linker (computing) OpenNLP - Solr Wiki. Code in JavaScript the smart, modular way.
Code in JavaScript the smart, modular way. XML for the absolute beginner. XML Tutorial. Acl.ldc.upenn.edu/W/W02/W02-1706.pdf. Acl.ldc.upenn.edu/W/W02/W02-1706.pdf. XML-based NLP tools for analysing and annotating medical language. Knowledge representation and reasoning. Context searching using Clojure-OpenNLP. SharpNLP - open source natural language processing tools - An easy(ish) alternative to porting OpenNlp to C# Tools.doccat (OpenNLP Tools 1.5.0 API) Overview (OpenNLP Tools 1.5.0 API) Getting started with OpenNLP (Natural Language Processing) Statistical parsing of English sentences. AI effect.
Applications of artificial intelligence. Knowledge engineering. Knowledge engineering. Machine learning for an expert system to predict preterm birth risk. Outline of artificial intelligence. Expert system. Home Page. The hearsay speech understanding system. Faculty.cns.uni.edu/~wallingf/teaching/162/readings/hearsay-ii.pdf. Www.cse.psu.edu/~bhuvan/teaching/fall06/uuv/papers/Optimizations-Evaluations/DavisBrutzman - THE AUTONOMOUS UNMANNED VEHICLE WORKBENCH MISSION.pdf.
Expert system. Knowledge Engineering Environment. French Institute for Research in Computer Science and Automation. Www.aclweb.org/anthology/O/O06/O06-1004.pdf. Anthology/A/A00/A00-2036.pdf. Pdf/cs/0112018v1.pdf. Pdf/cs/0112018v1.pdf. Acl.ldc.upenn.edu/P/P02/P02-1015.pdf. Context-Free Grammar Parsing by Message Passing.
Context-free grammar.