
QVT. Un article de Wikipédia, l'encyclopédie libre.
QVT (Query/View/Transformation)] est un standard défini par l'OMG. Il s'agit d'un langage standardisé pour exprimer des transformations de modèles. La notion de transformation de modèles est essentielle en Ingénierie dirigée par les modèles ou MDA (Model driven architecture). Détails[modifier | modifier le code] Le standard QVT définit un ensemble de langages permettant d'exprimer des transformations de modèles à modèles : QVT-Relation est un langage déclaratif ;QVT-Operational est un langage hybride qui propose une structure déclarative à base de règles et permet l'utilisation d'expressions impératives ;QVT-Core définit la sémantique des concepts déclaratifs.
Métadonnée. Le catalogue de la bibliothèque universitaire de Graz en Autriche.
La carte présentée renvoie à un texte de Schleimer qui a défini les règles de ce catalogue. Historique[modifier | modifier le code] Tous les établissements qui ont à gérer de l'information, bibliothèques, archives ou médiathèques ont déjà une longue pratique dans la codification du signalement ou des contenus des documents qu'ils manipulent.
Avant l'arrivée de l'informatique on utilisait des fiches cartonnées dont la structure a été normalisée en 1954 sous la référence ISBD (International standard bibliographic description). Ces descriptions ont ensuite été informatisées sous la forme de notices bibliographiques et normalisées (voir par exemple les formats MARC en 1964 utilisant la norme ISO 2709 dont la conception a démarré en 1960). Les bibliothèques numériques ont eu recours aux mêmes dispositifs pour gérer et localiser des documents électroniques. Web des données. Un article de Wikipédia, l'encyclopédie libre.
Le Web des données (Linked Data, en anglais) est une initiative du W3C (Consortium World Wide Web) visant à favoriser la publication de données structurées sur le Web, non pas sous la forme de silos de données isolés les uns des autres, mais en les reliant entre elles pour constituer un réseau global d'informations. Il s'appuie sur les standards du Web, tels que HTTP et URI - mais plutôt qu'utiliser ces standards uniquement pour faciliter la navigation par les êtres humains, le Web des données les étend pour partager l'information également entre machines. Cela permet d'interroger automatiquement les données, quels que soient leurs lieux de stockage, et sans avoir à les dupliquer[1]. Tim Berners-Lee, directeur du W3C, a inventé et défini le terme Linked Data et son synonyme Web of Data au sein d'un ouvrage portant sur l'avenir du Web sémantique[2].
JSON-LD. JSON-LD, or JavaScript Object Notation for Linked Data, is a method of transporting Linked Data using JSON.
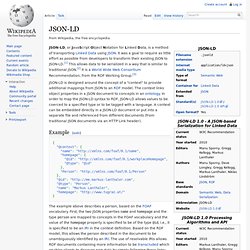
It was a goal to require as little effort as possible from developers to transform their existing JSON to JSON-LD.[1] This allows data to be serialized in a way that is similar to traditional JSON.[2] It is a World Wide Web Consortium Recommendation, from the RDF Working Group.[3] Example[edit] By having all data semantically annotated as in the example, a RDF processor can identify that the document contains information about a person (@type) and if the processor understands the FOAF vocabulary it can determine which properties specify the person’s name and the homepage of the person. JSON-LD - JSON for Linking Data. Resource Description Framework. Un article de Wikipédia, l'encyclopédie libre.
Pour les articles homonymes, voir RDF. En annotant des documents non structurés et en servant d'interface pour des applications et des documents structurés (par exemple bases de données, GED, etc.) RDF permet une certaine interopérabilité entre des applications échangeant de l'information non formalisée et non structurée sur le Web. Principes fondamentaux[modifier | modifier le code] Un document structuré en RDF est un ensemble de triplets. Un triplet RDF est une association : (sujet, prédicat, objet) Le sujet, et l'objet dans le cas où c'est une ressource, peuvent être identifiés par une URI ou être des nœuds anonymes. Les documents RDF peuvent être écrits en différentes syntaxes, y compris en XML. Un document RDF ainsi formé correspond à un multigraphe orienté étiqueté. {sujet, objet, prédicat} ⇔ prédicat(objet, sujet) ce qui est équivalent à : ∃ objet, ∃ sujet tq prédicat(objet, sujet)
Web sémantique. Logo du W3C pour le Web sémantique Le Web sémantique, ou toile sémantique[1], est une extension du Web standardisée par le World Wide Web Consortium (W3C)[2].
Ces standards encouragent l'utilisation de formats de données et de protocoles d'échange normés sur le Web, en s'appuyant sur le modèle Resource Description Framework (RDF). Le web sémantique est par certains qualifié de web 3.0 . Alors que ses détracteurs ont mis en doute sa faisabilité, ses promoteurs font valoir que les applications réalisées par les chercheurs dans l'industrie, la biologie et les sciences humaines ont déjà prouvé la validité de ce nouveau concept[5].
L'article original de Tim Berners-Lee en 2001 dans le Scientific American a décrit une évolution attendue du Web existant vers un Web sémantique[6], mais cela n'a pas encore eu lieu.