
How to Make Sense of Weak Signals. 2008 MAY - A03.pdf. Rapid - I. Weak signal research 4. Part IV: Evolution and Growth of the Weak Signal to Maturity Bryan S.

Coffman January 21, 1997 back to Part I: Introduction back to Part II: Information Theory back to Part III: Sampling, Uncertainty and Phase Shifts in Weak Signals Weak Signal Source [For stories and more information on the emergence of weak signals in Silicon Valley, check out the San Jose Mercury News series called The Revolutionaries. Where do weak signals come from, and how do they become strong signals? Signals must have sources. Many new ideas are conceived not by one individual or isolated team, but by many individuals and teams that may or may not be aware of each other's work. But where do the new ideas come from? Growth of a Weak Signal All of the messages whose synthesis will result in a new weak signal or idea come to us from the past.
So Phase I in the growth of a weak signal is placing yourself in the path of high-novelty signals in an uncertain environment. First, the signals must be gathered and stored.
Browser Automation. Web mining. Text mining. A typical application is to scan a set of documents written in a natural language and either model the document set for predictive classification purposes or populate a database or search index with the information extracted.
Text mining. Fouille de textes. Un article de Wikipédia, l'encyclopédie libre.
La fouille de textes ou "l'extraction de connaissances" dans les textes est une spécialisation de la fouille de données et fait partie du domaine de l'intelligence artificielle. Cette technique est souvent désignée sous l'anglicisme text mining. C'est un ensemble de traitements informatiques consistant à extraire des connaissances selon un critère de nouveauté ou de similarité dans des textes produits par des humains pour des humains. Dans la pratique, cela revient à mettre en algorithmes un modèle simplifié des théories linguistiques dans des systèmes informatiques d'apprentissage et de statistiques.
Announcing the PLOS Text Mining Collection. Hello there!
If you enjoy the content on EveryONE, consider subscribing for future posts via email or RSS feed. Post authored by Casey M. Bergman, Lawrence E. Introduction au Text-mining. ClearForest Gnosis. KEEL: A software tool to assess evolutionary algorithms for Data Mining problems (regression, classification, clustering, pattern mining and so on) National Centre for Text Mining — Text Mining Tools and Text Mining Services. Classification Trees Software. Retail + Social + Mobile = @WalmartLabs. Eric Schmidt famously observed that every two days now, we create as much data as we did from the dawn of civilization until 2003.

A lot of the new data is not locked away in enterprise databases, but is freely available to the world in the form of social media: status updates, tweets, blogs, and videos. At Kosmix, we’ve been building a platform, called the Social Genome, to organize this data deluge by adding a layer of semantic understanding. Conversations in social media revolve around “social elements” such as people, places, topics, products, and events. For example, when I tweet “Loved Angelina Jolie in Salt,” the tweet connects me (a user) to Angelia Jolie (an actress) and SALT (a movie). By analyzing the huge volume of data produced every day on social media, the Social Genome builds rich profiles of users, topics, products, places, and events.
Quite a few of us at Kosmix have backgrounds in ecommerce, having worked at companies such as Amazon.com and eBay. Theeasybee.com. Konstanz Information Miner. Center for Intelligent Information Retrieval. Chris Harrison - Web Trigrams Visualization. Back in late 2006, Google released a massive set of web n-gram data (basically pieces of sentences).

A trigram (n=3), for example, might be "I like food" or "frog is tasty. " Each n-gram is also labeled with the number of times it appeared in Google's corpus. The entire archive, which is almost 100GB uncompressed, has unigrams (n=1) through fivegrams (n=5). The data set is offered through the LDC for those who are interested (link). As soon as I got my hands on the data, I quickly got to work on some straight forward visualizations.
These visual comparisons allow us to see differences in how the two subjects are used - both where they are similar and diverge. I also created a little series of visualizations that shows how six common subjects are used. Very simple, but kind of cool. Cluster Execution. Compute clusters often run idle because of a lack of applications that can be run in the cluster environment and the enormous effort required to operate, maintain, and support applications on the grid.
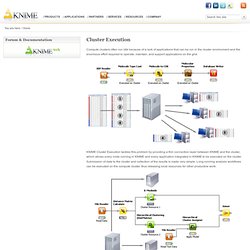
KNIME Cluster Execution tackles this problem by providing a thin connection layer between KNIME and the cluster, which allows every node running in KNIME and every application integrated in KNIME to be executed on the cluster. Submission of data to the cluster and collection of the results is made very simple. Long-running analysis workflows can be executed on the compute cluster, thus releasing local resources for other productive work. Recherche d'information. Un article de Wikipédia, l'encyclopédie libre.
La recherche d'information (RI[1]) est le domaine qui étudie la manière de retrouver des informations dans un corpus. Celui-ci est composé de documents d'une ou plusieurs bases de données, qui sont décrits par un contenu ou les métadonnées associées. Les bases de données peuvent être relationnelles ou non structurées, telles celles mises en réseau par des liens hypertexte comme dans le World Wide Web, l'internet et les intranets.
Le contenu des documents peut être du texte, des sons, ses images ou des données. Carrot Search: document clustering and visualization software. AlchemyAPI - Transforming Text Into Knowledge. What is Maltego - Paterva Wiki. From Paterva Wiki What is Maltego?
With the continued growth of your organization, the people and hardware deployed to ensure that it remains in working order is essential, yet the threat picture of your “environment” is not always clear or complete. In fact, most often it’s not what we know that is harmful - it’s what we don’t know that causes the most damage. This being stated, how do you develop a clear profile of what the current deployment of your infrastructure resembles?
What are the cutting edge tool platforms designed to offer the granularity essential to understand the complexity of your network, both physical and resource based? Maltego is a unique platform developed to deliver a clear threat picture to the environment that an organization owns and operates. Maltego offers the user with unprecedented information. Maltego 3.