
A Beginner’s Guide to Optimizing Pandas Code for Speed. 28 Jupyter Notebook tips, tricks and shortcuts. Jupyter Notebook Jupyter notebook, formerly known as the IPython notebook, is a flexible tool that helps you create readable analyses, as you can keep code, images, comments, formulae and plots together. In this post, we’ve collected some of the top Jupyter notebook tips to quickly turn you into a Jupyter power user! (This post is based on a post that originally appeared on Alex Rogozhnikov’s blog, ‘Brilliantly Wrong’. We have expanded the post and will continue to do so over time — if you have a suggestion please let us know. Welcome to PyGMO — PyGMO 1.1.7dev documentation. PyGMO (the Python Parallel Global Multiobjective Optimizer) is a scientific library providing a large number of optimisation problems and algorithms under the same powerful parallelization abstraction built around the generalized island-model paradigm.
What this means to the user is that the available algorithms are all automatically parallelized (asynchronously, coarse-grained approach) thus making efficient use of the underlying multicore architecture. The user can also program his own solvers ... they also will be parallelized by PyGMO!! PyGMO’s implementation of the generalized migration operator allows the user to easily define “migration paths” (topologies) between a large number of “islands” (CPU cores). Many complex-networks topologies (Hypercube, Ring, Barabasi-Albert, Watts-Strogatz, Erdos-Renyi, etc.) are built-in and may be used to define the migration pathways of good solutions among islands. Using C++ in Cython — Cython 0.25.2 documentation. A simple Tutorial An example C++ API Here is a tiny C++ API which we will use as an example throughout this document.
Let’s assume it will be in a header file called Rectangle.h: and the implementation in the file called Rectangle.cpp: This is pretty dumb, but should suffice to demonstrate the steps involved. Cython/Python/C++ - Inheritance: Passing Derived Class as Argument to Function expecting base class. WrappingSetOfCppClasses · cython/cython Wiki. Wrapping a set of C++ classes Overview This page demonstrates how to wrap a more complicated pair of C++ classes than the basic example.
We have two classes, one of which inherits from the other, and both constructors can take a pointer to an instance of the base class to act as a parent to the new instance. A Dramatic Tour through Python’s Data Visualization Landscape (including ggplot and Altair) – Regress to Impress. Why Even Try, Man?
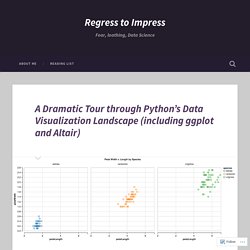
I recently came upon Brian Granger and Jake VanderPlas’s Altair, a promising young visualization library. Altair seems well-suited to addressing Python’s ggplot envy, and its tie-in with JavaScript’s Vega-Lite grammar means that as the latter develops new functionality (e.g., tooltips and zooming), Altair benefits — seemingly for free! Indeed, I was so impressed by Altair that the original thesis of my post was going to be: “Yo, use Altair.” Piping results with IPython parallel. Pipe and follow are stored on edges.
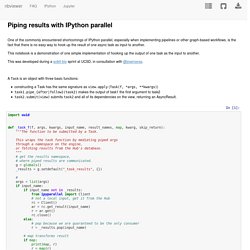
If there is an edge connecting two nodes, if nothing else is specified, it will be a time dependency (after), so the downstream task will run after the upstream task, on any engine. If follow is True, the downstream task will run on the same engine as the upstream task. If pipe is True, the result of the upstream task will be passed as an argument to the downstream task. Unit Testing with Python. Mpi4py parallel IO example. For about 9 months I have been running python jobs in parallel using mpi4py and NumPy.
I had to write a new algorithm with MPI so I decided to do the IO in parallel. Below is a small example of reading data in parallel. Python.org.