
Open population datasets and open challenges. The Connectivity Lab team at Facebook is working on communication technologies aimed at connecting people in rural areas who currently do not have access to the internet.
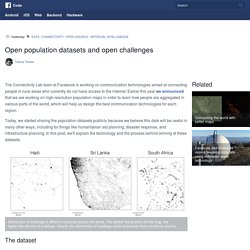
Earlier this year we announced that we are working on high-resolution population maps in order to learn how people are aggregated in various parts of the world, which will help us design the best communication technologies for each region. Today, we started sharing the population datasets publicly because we believe this data will be useful in many other ways, including for things like humanitarian aid planning, disaster response, and infrastructure planning.
In this post, we'll explain the technology and the process behind arriving at these datasets. The dataset Our population datasets are a joint effort between Facebook, Columbia University, and the World Bank. Dataset analysis From a first analysis of our dataset we extract how people are aggregated near urbanized areas that have more than 10,000 people. Enigma Public. Browse Editions. Data. Untitled. Some of these resources allow large data downloads for research purposes; others are intended for smaller scale research activities such as experimentation with visualization and development of tools to query journal and citation databases.
The use of the majority of these resources requires some programming skills. Datasets and APIs for Full-Text Retrieval arXiv arXiv provides open access to electronic pre-prints in Astrophysics, Physics, Mathematics, Computer Science, Quantitative Biology, Quantitative Finance and Statistics. Automated downloads using robots, spiders, accelerators, and similar tools are not permitted. Chronicling America API Chronicling America provides access to information about historic newspapers and select digitized newspaper pages. Digital Public Library of America (DPLA) API The Digital Public Library of America (DPLA) provides access to a wide range of content from America’s museums, libraries, and archives.
Europeana APIs. Zenodo - Research. Shared. Datasets. Datasets Learn More New Dataset Welcome to Kaggle Datasets.
Untitled. The prometheus Image Archive: High-quality images from the fields of arts, culture and history. Internet Library of Early Journals. We regret to inform users that this resource is no longer available.

The site has been withdrawn as the technologies which it is built with have reached end-of-life. An archived version of the site is available at Last update to original site: 1999 Date withdrawn: 1 April 2020 Please contact digitalsupport@bodleian.ox.ac.uk with any questions. OxLIP+ - Find Database. New Resources and Trials Statistics South Africa Open data portal maintained by the government of South Africa to produce and co-ordinate statistics on its economy and citizens and to assist in evidence-based policy making.

Data and publications based on a variety of census and survey sources are available and may be searched according to key themes, locations and indicators. Harmonized System Database Online An online resource for researching trade, commodities and in particular international tariff rates. Digital Miscellanies Index. Links ~ Digital Miscellanies Index. Our Project and Partners Digital Miscellanies Index Verse Miscellanies Online.

Humanities. Humanities Art Design Digital Humanities Disability Studies.
Data repositories - Open Access Directory. From Open Access Directory.
Open Access Text Sources - Text and Data Mining Library Databases - Subject Guides at Northeastern University. Human Mortality Database. A List of +2600 Open Data Portals around the World. Where can I find clean and usable data?
But the truth is, some Open Data portals can be hard to come by. We decided to put together a resource that would be truly useful for all the data geeks out there (and we know we are plenty ). Cross-National Time-Series Data Archive. Untitled. Academic Torrents. Dhresourcesforprojectbuilding [licensed for non-commercial use only] / Data Collections and Datasets. Guides to Digital Humanities | Tutorials | Tools | Examples | Data Collections & Datasets ● Demo Corpora (Small to moderate-sized text collections for teaching, text-analysis workshops, etc.) ● Quick Start (Common text analysis tools & resources to get instructors and students started quickly) Demo Corpora (Text Collections Ready for Use)
![dhresourcesforprojectbuilding [licensed for non-commercial use only] / Data Collections and Datasets](http://cdn.pearltrees.com/s/pic/th/commercial-collections-144839362)
Home - EASY. Digtrade/database at master · digtrade/digtrade. TAPAS Project. Linked Data - Connect Distributed Data across the Web. HISCO - History of Work. Central to social, economic and labour history is the world of work, as known by occupational activities and titles. Yet research, especially comparative research, is severely hampered by confusion regarding occupational terminology across time and space, within as well as between languages.This project aims at creating an occupational information system that is both international and historical, and simultaneously links to existing classifications used for present-day conditions. The information system will make available on the Web (link is external)a historical international classification of occupations (HISCO) combined with information on their tasks and duties in historical settings as well as images on the history of work.
Starting in the 1950s the International Labour Office has developed an International Standard Classification of Occupations (isco) allowing classification of occupational activities worldwide. Why the Work on HISCO started Long-term perspective Contacting us. DBpedia datasets. The DBpedia data set uses a large multi-domain ontology which has been derived from Wikipedia as well as localized versions of DBpedia in more than 100 languages. 1 Background Wikipedia has grown into one of the central knowledge sources of mankind and is maintained by thousands of contributors. Wikipedia articles consist mostly of free text, but also contain different types of structured information, such as infobox templates, categorisation information, images, geo-coordinates, and links to external Web pages. For instance, the figure below shows the source code and the visualisation of an infobox template containing structured information about the town of Innsbruck.
The DBpedia project extracts various kinds of structured information from Wikipedia editions in more than 100 languages and combines this information into a huge, cross-domain knowledge base. 3 Denoting or Naming "things" Starting with DBpedia release 3.8, we use IRIs for most DBpedia entity names. CORE. Chronicling America « Library of Congress. About the History Data Service Collection. About the History Data Service Collection The History Data Service data collection brings together over 650 separate studies transcribed, scanned or compiled from historical sources.
The studies cover a wide range of historical topics, from the seventh century to the twentieth century. Although the primary focus of the collection is on the United Kingdom, it also includes a significant body of cross-national and international data collections. Examples of topics covered include: nineteenth and twentieth century statistics, manuscript census records, state finance data, demographic data, mortality data, community histories, electoral history and economic indicators. Staff at the History Data Service will be happy to answer any queries you may have about the collection. Principal Resources. Polish Immigration Records : 1834 - 1897.
The Dataverse Project - Dataverse.org. Harvard Dataverse. Rundata - Wikipedia. History[edit] The origin of the Rundata project was a 1986 database of Swedish inscriptions at Uppsala University for use in the Scandinavian Languages Department.[2] At a seminar in 1990 it was proposed to expand the database to cover all Nordic runic inscriptions, but funding for the project was not available until a grant was received in 1992 from the Axel och Margaret Ax:son Johnsons foundation.[2] The project officially started on January 1, 1993 at Uppsala University.
After 1997, the project was no longer funded and work continued on a voluntary basis outside of normal work-hours.[2] In the current edition, published on December 3, 2008, there are over 6500 inscriptions in the database.[2] Work is currently underway for the next edition of the database. Format of entries[edit] Each entry includes the original text, its format, location, English and Swedish translations, information about the stone itself, et cetera. The first part describes the origin of the inscription. Untitled.