
A megalopolis six times the size of New York, JingJinJi will ease the pressures being faced by China’s capital Beijing.

If you thought that China’s cities are massive, think again. China’s urban planners are hard at work creating new megalopolises that will redefine our understanding of cities as we know them. One of them—nicknamed JingJinJi—will transform Beijing and its surrounding areas into a city six times the size of New York. So what is JingJinJi? It stands for Beijing (‘Jing’), Tianjin (‘Jin’) and Heibei Province (Hebei is known by the one character abbreviation ‘Ji’, which was its name during the Han dynasty).
China’s Politburo officially approved the JingJinJi Common Development Guideline on April 30th, 2015. Beijing, Tianjin and Hebei together account for up to 2.3% of China’s territory and 8% of China’s 1.37 billion population. The signs are already there. Poor quality of life due to such inconveniences have forced many to leave the capital. Maven Tutorial for Beginners : with Eclipse. Untitled. Eigenvectors and Eigenvalues explained visually. Explained Visually By Victor Powell and Lewis Lehe Eigenvalues/vectors are instrumental to understanding electrical circuits, mechanical systems, ecology and even Google's PageRank algorithm.

Dive Into NLTK, Part IV: Stemming and Lemmatization – Text Mining Online. This is the fourth article in the series “Dive Into NLTK“, here is an index of all the articles in the series that have been published to date: Part I: Getting Started with NLTKPart II: Sentence Tokenize and Word TokenizePart III: Part-Of-Speech Tagging and POS TaggerPart IV: Stemming and Lemmatization (this article)Part V: Using Stanford Text Analysis Tools in PythonPart VI: Add Stanford Word Segmenter Interface for Python NLTKPart VII: A Preliminary Study on Text ClassificationPart VIII: Using External Maximum Entropy Modeling Libraries for Text Classification Stemming and Lemmatization are the basic text processing methods for English text.

The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form. Here is the definition from wikipedia for stemming and lemmatization: Stemming: Lemmatization: Speech recognition - Hello world for spoken NLP interaction (like Siri)? CMUSphinx Tutorial For Developers [CMUSphinx Wiki] The Project Gutenberg EBook of The Adventures of Sherlock Holmes by Sir Arthur Conan Doyle (#15 in our series by Sir Arthur Conan Doyle) Copyright laws are changing all over the world.
Be sure to check the copyright laws for your country before downloading or redistributing this or any other Project Gutenberg eBook. This header should be the first thing seen when viewing this Project Gutenberg file. Please do not remove it. Nlp - NLTK Named Entity recognition to a Python list. User Ashwini Chaudhary. Building Language Model [CMUSphinx Wiki] There are several types of models that describe language to recognize - keyword lists, grammars and statistical language models, phonetic statistical language models.
![Building Language Model [CMUSphinx Wiki]](http://cdn.pearltrees.com/s/pic/th/building-language-cmusphinx-129496559)
You can chose any decoding mode according to your needs and you can even switch between modes in runtime. Keyword lists Pocketsphinx supports keyword spotting mode where you can specify the keyword list to look for. The advantage of this mode is that you can specify a threshold for each keyword so that keyword can be detected in continuous speech. All other modes will try to detect the words from grammar even if you used words which are not in grammar. GitHub - attardi/wikiextractor: A tool for extracting plain text from Wikipedia dumps. Carinh’s Documents on SlideShare. Buy Authentic Louis Vuitton Handbags from Factory Outlet. Using colours in LaTeX. There are several elements in LaTeX whose colour can be changed to improve the appearance of the document.
Colours can be manually defined to a desired tone using several models, this article explains how. [edit] Introduction The simplest manner to use colours in your LaTeX document is by importing the package color or xcolor. Both packages provide a common set of commands for colour manipulation, but the latter is more flexible and supports a larger number of colour models. Coursera - Free Online Courses From Top Universities. Word Search II. Given a 2D board and a list of words from the dictionary, find all words in the board.
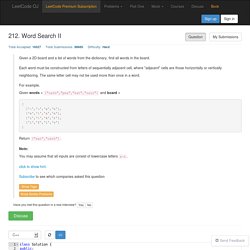
Each word must be constructed from letters of sequentially adjacent cell, where "adjacent" cells are those horizontally or vertically neighboring. The same letter cell may not be used more than once in a word. For example, Given words = ["oath","pea","eat","rain"] and board = [ ['o','a','a','n'], ['e','t','a','e'], ['i','h','k','r'], ['i','f','l','v'] ] Return ["eat","oath"]. A Guide to Python Frameworks for Hadoop - Cloudera Engineering Blog. I recently joined Cloudera after working in computational biology/genomics for close to a decade.
My analytical work is primarily performed in Python, along with its fantastic scientific stack. It was quite jarring to find out that the Apache Hadoop ecosystem is primarily written in/for Java. So my first order of business was to investigate some of the options that exist for working with Hadoop from Python. In this post, I will provide an unscientific, ad hoc review of my experiences with some of the Python frameworks that exist for working with Hadoop, including: Hadoop Streamingmrjobdumbohadoopypydoopand others. Machine Learning vs. Natural Language Processing, part 1 - Lexalytics. (Note: Updated July 2, 2015) What is Machine Learning?
Machine Learning (in the context of text analytics) is a set of statistical techniques for identifying some aspect of text (parts of speech, entities, sentiment, etc). The techniques can be expressed as a model that is then applied to other text (supervised), or could be a set of algorithms that work across large sets of data to extract meaning (unsupervised). Supervised Machine Learning Take a bunch of documents that have been “tagged” for some feature, like parts of speech, entities, or topics (classifiers).
A Guide to Python Frameworks for Hadoop. Writing An Hadoop MapReduce Program In Python. In this tutorial I will describe how to write a simple MapReduce program for Hadoop in the Python programming language. Even though the Hadoop framework is written in Java, programs for Hadoop need not to be coded in Java but can also be developed in other languages like Python or C++ (the latter since version 0.14.1). However, Hadoop’s documentation and the most prominent Python example on the Hadoop website could make you think that you must translate your Python code using Jython into a Java jar file.
Obviously, this is not very convenient and can even be problematic if you depend on Python features not provided by Jython. Another issue of the Jython approach is the overhead of writing your Python program in such a way that it can interact with Hadoop – just have a look at the example in $HADOOP_HOME/src/examples/python/WordCount.py and you see what I mean. Our program will mimick the WordCount, i.e. it reads text files and counts how often words occur. Creating a great data science resume. I hear a familiar story from a lot of aspiring data scientists: “I have sent out my resume to 25 companies, and I haven’t heard back from any of them!
I have pretty good skills, and I think I have a pretty good resume. I don’t know what’s going on!” Your resume probably sucks My immediate conclusion after hearing your story: your resume probably sucks. If you are not getting any responses from any companies, and your skills are a reasonable match for the job description, then it almost certainly means that you are getting sabotaged by a bad resume. LaTeX Templates. TikZ and PGF. Webmail: Max-Planck-Institut für Informatik - You must be logged in to access this page.
海外申请护照在线预约. 海外申请护照在线预约. Practical Programming for Total Beginners. Automate the Boring Stuff with Python Programming. If you're an office worker, student, administrator, or just want to become more productive with your computer, programming will allow you write code that can automate tedious tasks.
This course follows the popular (and free!) Book, Automate the Boring Stuff with Python. Automate the Boring Stuff with Python was written for people who want to get up to speed writing small programs that do practical tasks as soon as possible. You don't need to know sorting algorithms or object-oriented programming, so this course skips all the computer science and concentrates on writing code that gets stuff done. This course is for complete beginners and covers the popular Python programming language.
Web scrapingParsing PDFs and Excel spreadsheetsAutomating the keyboard and mouseSending emails and textsAnd several other practical topics. Improve Your Python: Python Classes and Object Oriented Programming. The class is a fundamental building block in Python. It is the underpinning for not only many popular programs and libraries, but the Python standard library as well. Understanding what classes are, when to use them, and how the can be useful is essential, and the goal of this article. In the process, we'll explore what the term Object-Oriented Programming means and how it ties together with Python classes.
40 Terminal Tips and Tricks You Never Thought You Needed. The Terminal is an exceptionally powerful tool, providing a command line interface to the underpinnings of OS X. It’s a topic we’ve covered at length before with our popular series Taming the Terminal. There’s a great deal that Terminal can do, from moving large numbers of files to changing preferences that we didn’t even know exist. To demonstrate just how versatile the Terminal is, I’ve rounded up 40 truly excellent Terminal tips and tricks that can come in very handy. All of the Terminal commands I’ll be showing you are perfectly safe to use and, when it comes to changing preferences, are completely reversible. Gensim: Tutorials. The tutorials are organized as a series of examples that highlight various features of gensim. It is assumed that the reader is familiar with the Python language, has installed gensim and read the introduction.
Preliminaries All the examples can be directly copied to your Python interpreter shell. IPython’s cpaste command is especially handy for copypasting code fragments, including the leading >>> characters. Semantic role labeling part 1 naacl 2013 tutorial. Sentiment Tutorial Demo: Word-vector similarity. Profile of Mood States (POMS) POMS is a standard validated psychological test formulated by McNair et al. (1971)[1]. The questionnaire contains 65 words/statements that describe feelings people have. The test requires you to indicate for each word or statement how you have been feeling in the past week including today. Gensim: Topic modelling for humans. Practnlptools 1.0. Practical Natural Language Processing Tools for Humans. Dependency Parsing, Syntactic Constituent Parsing, Semantic Role Labeling, Named Entity Recognisation, Shallow chunking, Part of Speech Tagging, all in Python. District Data Labs - Modern Methods for Sentiment Analysis.
Modern Methods for Sentiment Analysis Michael Czerny Sentiment analysis is a common application of Natural Language Processing (NLP) methodologies, particularly classification, whose goal is to extract the emotional content in text. Sentiment Symposium Tutorial: Vector-space models. Overview This section introduces some basic techniques from the study of vector-space models. Collaborative Filtering : Implementation with Python! - Artificial Intelligence in Motion. Continuing the recommendation engines articles series, in this article i'm going to present an implementation of the collaborative filtering algorithm (CF), that filters information for a user based on a collection of user profiles. Users having similar profiles may share similar interests.
Airfare tips: cutting the price of travel in half. In the past year I have flown 20 times: from North America to Europe, the Middle-East and North Africa, to Asia and back.
Yiannis Demiris' webpage. Imperial College London. Applications for 2015 entry are now open. Imperial College Business School operates a number of application deadlines throughout the year. For more information please see their website. News and Events: PhD candidate in Computational Linguistics and Dialogue Processing - The Institute for Logic, Language and Computation. Newsitem added on 10 September 2015. The ILLC is looking for a highly motivated, creative and talented PhD candidate to join the newly established Dialogue Modelling Group led by Raquel Fernández. The mission of the group is to understand dialogical interaction by developing empirically-motivated formal and computational models that can be applied to various dialogue processing tasks and to human-machine interaction.
» Shop Online » Blue Sky Bio: Compatibility. Innovation. Value. Arun et al measure with NPR data · GitHub. Skip to content. Finding the natural number of topics for Latent Dirichlet Allocation - Christopher Grainger. Update (July 13, 2014): I’ve been informed that I should be looking at hierarchical topic models (see Blei’s papers here and here). Thanks to Reddit users /u/GratefulTony and /u/EdwardRaff for bringing this to my attention. However, Redditor /u/NOTWorthless says HDPs do not provide a ‘posterior on the correct number of topics in any meaningful sense’. What is a good way to perform topic modeling on short text? Writing An Hadoop MapReduce Program In Python. Python Map Reduce on Hadoop - A Beginners Tutorial. 8 Regular Expressions You Should Know.
Prediction of intent in robotics and multi-agent systems - Springer. Profile Page. Regular Expression HOWTO. Getting started with Latent Dirichlet Allocation in Python — chris' sandbox. James Caverlee. Right Relevance : Influencers, Articles and Conversations. Top Datasets on Reddit. 60+ Free Books on Big Data, Data Science, Data Mining, Machine Learning, Python, R, and more. Reduce Computer-Caused Eye Strain with the 20-20-20 Rule. How can I force division to be floating point in Python? 饺子的制作秘诀,一分钟变高手!_美食专题_专辑菜谱. Big Data Trainers — Your Search for World Class Big Data Training Programs Ends Here! A Brief Intro of Hanfu. Pragmatic Unicode. TikZ examples feature: Matrices. National Geographic Travel. MLTK: Machine Learning Tool Kit. Added comma condition to PunktWordTokeniser by smithsimonj · Pull Request #746 · nltk/nltk. Python spell-checker for twiter stream · GitHub. 50+ Data Science and Machine Learning Cheat Sheets. A special UC Berkeley iSchool course.
Sentdex Analysis. The Largest List of Chat Acronyms and Text Message Shorthand (IM, SMS) found of the Web - kept current and up-to-date by NetLingo The Internet Dictionary: Online Dictionary of Computer and Internet Terms, Acronyms, Text Messaging, Smileys ;-) Nlp - python module to remove internet jargon/slang/acronym. Text - Creating Vocabulary in python. An Introduction to Text Mining using Twitter Streaming API and Python // Adil Moujahid // Data Analytics and more. The Largest List of Chat Acronyms and Text Message Shorthand (IM, SMS) found of the Web - kept current and up-to-date by NetLingo The Internet Dictionary: Online Dictionary of Computer and Internet Terms, Acronyms, Text Messaging, Smileys ;-) Steps For Effective Text Data Cleaning. Step By Step Guide To Extract Information. Building A Word Cloud Using R.
A beginners guide to streamed data from Twitter. Tweets. AIML Tutorial. A Visual Introduction to Machine Learning. 三个诀窍做出让你要死要活的卤肉饭. Explicit cookie consent. Install Python, NumPy, SciPy, and matplotlib on Mac OS X. Tung-Wei Lin. UNIX Tutorial Three. Up in the Air: Meet the Man Who Flies Around the World for Free. Keynote 2013 Full Tutorial. Google-Ergebnis für. Conditional Random Field (CRF) Tutorial. Introduction to Conditional Random Fields. Max-Planck-Institut für Informatik: Data Mining and Matrices. User Manual for Casio Watch Module 2568 - Owner's Guide & Instructions. Best Ever Smoothie Recipes!