
Le Knowledge Graph de Google n'est pas sémantique, il est "sémantique" Cette note fait suite à un article du JDN « La recherche sémantique, le défi SEO de 2013 ?
» (signé par Virgile Juhan), présentant l’opinion de « l’expert » SEO David Degrelle. Impossible de laisser un commentaire, le texte s’affiche comme définitif et interdit tout débat. Comme si nous en savions assez sur la question pour que l’opinion prétende au marbre de la vérité. C’est parce que je n’en suis pas convaincu que le débat, aussi modeste soit-il, est poursuivi ici. Sur certains aspects de l’article et des jugements qu’il présente, je disconviens respectueusement. Grâce au Knowledge Graph (KG) de Google, nous serions de plain-pied dans le « web sémantique ». Le but derrière KG serait de « mieux comprendre le sens des mots, leur subtilité et leur intention, pour toujours mieux répondre aux questions de l’internaute et donc à ses requêtes ». Une question majeure qui mérite d’être traitée dans une large perspective, les réponses trop hâtives pouvant être trompeuses.
Et pour cause. Ceci n’est pas le Web sémantique. Le Google Knowledge Graph a fait du chemin depuis sa première annonce au printemps dernier.
Beaucoup de choses ont été écrites sur la portée de l’événement, qui entérinerait l’adhésion officielle de Google aux principes de base du Web sémantique, résumés par la formule choc things, not strings. Avec des chiffres qui se veulent impressionnants : des centaines de millions de choses et des milliards de faits (propriétés des choses et relations entre elles). Selon une déclaration de Larry Page le mois dernier, le Knowledge Graph n’est encore qu’à 1% de ses objectifs. Au passage le patron de Google souligne que la tâche est ardue, en particulier dans ses aspects multilingues. Nul ne peut nier que le Knowledge Graph ajoute une vraie valeur à la recherche, avec une expérience utilisateur agréable et fluide qui permet de rebondir par exemple d’un peintre à ses oeuvres, de celles-ci aux musées où elles sont exposées etc.
Qu’est-ce que le Web Sémantique ? Utiliser la plateforme Datalift pour publier un jeu de données sur le Web - Datalift Wiki. From Datalift Wiki La plateforme Datalift a été conçue pour publier des jeux de données de qualité ***** sur le Web.
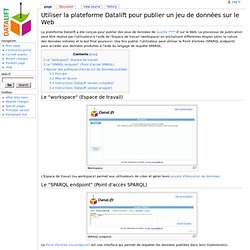
Le processus de publication peut être réalisé par l'utilisateur à l'aide de l'Espace de travail (workspace) en enchaînant différentes étapes selon la nature des données initiales et le but final poursuivi. Une fois publié, l'utilisateur peut utiliser le Point d'entrée (SPARQL endpoint) pour accéder aux données produites à l'aide du langage de requête SPARQL. Le "workspace" (Espace de travail) Workspace L'Espace de travail (ou workspace) permet aux utilisateurs de créer et gérer leurs projets d'élévation de données. URI Debugger. Defining the Semantic Web in a Few Sentences. A Quora user posed this challenge to the network: “How do you explain semantic web to a nine-year old child in one sentence?”
The challenge was followed by a quote from Albert Einstein: “If you can’t explain it to a six year old, you don’t understand it yourself.” Le web sémantique : un projet pour amener le web à son plein potentiel. Le web sémantique (généralement associé au terme « web 3.0 »), est une notion que l’on rencontre de plus en plus.
Que désigne cette association des mots « web » et « sémantique » qui appartiennent tous deux à des disciplines relativement éloignées que sont l’informatique et la linguistique ? Le web du futur sera-t-il « intelligent » et capable de juger de la pertinence d’une réponse en analysant la sémantique de la question correspondante ? Nous offrira-t-il la possibilité d’exploiter l’ensemble des contenus du web de façon parfaitement pertinente et précise ? Le web sémantique est un projet initié en 2001 par Tim Berners Lee1, inventeur du World Wide Web. Ce projet s’est développé sous l’égide du W3C qui est un organisme de standardisation des formats informatiques utilisés sur internet.
What is the Structured Web? The structured Web is object-level data within Internet documents and databases that can be extracted, converted from available forms, represented in standard ways, shared, re-purposed, combined, viewed, analyzed and qualified without respect to originating form or provenance.

Un petit panorama des triplestores. Concepts élémentaires Un triplestore (ou triple store) est une base de données destinée au stockage des données du web de données : les triplets. Ces derniers sont des déclarations dont la structure est invariablement de la forme de sujet-prédicat-objet, par exemple “Jean a 3 enfants”, “Jean est marié à Marie”. Dans un triplestore, le format des triplets est celui de métadonnées RDF (Resource Description Framework). Tout comme dans une base de données relationnelle classique, on stocke l’information dans un triplestore et on la récupère à l’aide d’un langage de requête. Jena Semantic Web Framework. RDFa Lite 1.1. Status of This Document This section describes the status of this document at the time of its publication.

Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at This is an Editorial Revision of the Recommendation published on the 7th of June, 2012. Using RDFa to Annotate Images. RDFa in the Browser. RDFa 1.1 pour corriger les erreurs de jeunesse ? RDFa. Introduction à RDFa. Résumé.

Interopérabilité. (LOV) Linked Open Vocabularies. Richard.cyganiak.de/2007/10/lod/lod-datasets_2011-09-19_colored.html. Welcome to the Bibliographic Ontology Website. Time Ontology in OWL. Abstract This document presents an ontology of temporal concepts, OWL-Time (formerly DAML-Time) [4,10], for describing the temporal content of Web pages and the temporal properties of Web services.

The ontology provides a vocabulary for expressing facts about topological relations among instants and intervals, together with information about durations, and about datetime information. We also demonstrate in detail, using the Congo.com and Bravo Air examples from OWL-S [11], how this time ontology can be used to support OWL-S, including use cases for defining input parameters and (conditional) output parameters. A use case for meeting scheduling is also shown. SKOS Simple Knowledge Organization System - home page. OWL API. RDF pour les nuls. Préambule du 27 août 2007 : à la suite d'un bon billet de David sur RDF, je voulais ajouter en commentaire la référence vers ce billet que j'avais écrit le 8 septembre 2006 ; je me suis alors aperçu qu'il n'avait pas été récupéré lors de l'import de mon ancien blog.
Comme j'avais un peu la flemme de rechercher dans mes archives persos, mon sauveur se nomme Internet Archive dont le crawler salutaire avait indexé cette page. Qu'il en soit remercié. Les métadonnées sémantiques : RDF, RDFa et les microdonnées « archivEngines. Le W3C (World Wide Web Consortium) débute dès 1994 ses travaux sur le Web sémantique ou Web des données. Il s’agit d’un projet à long terme visant à répertorier les connaissances stockées dans les pages du web afin d’en permettre la restitution par des applications. Les langages sémantiques RDF, RDFa et les microdonnées sont successivement spécifiés. Implémentés dans les logiciels des bibliothèques, des éditeurs, des centres d’archivage et des musées, mais aussi dans les gestionnaires de contenu, ils peuvent servir pour les échanges de métadonnées entre logiciels ou être reconnus par les moteurs de recherche.
4. Quelques applications et outils RDF. Map4rdf – Maps viewer of RDF resources with Geometrical Information. ChronoSIDORE : explorons les données d’ISIDORE avec SPARQL #2 – sp.Blog, le blog de Stéphane Pouyllau. Posté le 31 août 2012 ChronoSIDORE n’est pas le nom d’une nouvelle espèce de dinosaures, c’est le nom d’une application web qui utilise les ressources d’Isidore. ChronoSIDORE est donc un petit « mashup » que j’ai programmé pendant mes congés d’été. L’idée est double, poursuivre l’exploration concrète des possibilités d’un outil comme Isidore et donner des idées à d’autres personnes, en particulier dans le monde des bibliothèques et de la documentation, pour développer d’autres mashups s’appuyant soit sur l’API d’Isidore soit sur son SPARQL endpoint.
Timeline. Gephi, an open source graph visualization and manipulation software. Le tutoriel SPARQL. L'objectif de ce tutoriel SPARQL est de donner un cours rapide en SPARQL. Le tutoriel couvre les fonctionnalités majeures du langage de requête au travers d'exemples, mais ne vise pas à être complet. Si vous cherchez une courte introduction à SPARQL et Jena, essayez Recherche de données RDF avec SPARQL .
GeoSPARQL SWG. GeoLinkedData.es - map4rdf. Protocol.