
XQuery/Regular Expressions. Motivation[edit] You want to test to see if a text matches a specific pattern of characters You want to replace patterns of text with other patterns.
You have text with repeating patterns and you would like to break the text up into discrete items. Method[edit] To deal with the above three problems, XQuery has the following functions: matches($input, $regex) - returns a true if the input contains a regular expressionreplace($input, $regex, $string) - replaces an input string that matches a regular expression with a new stringtokenize($input, $regex) - returns a sequence of items matching a regular expression Through these functions we have access to the powerful syntax of regular expressions. Summary of Regular Expressions[edit] What can XPath do for me? Nokogiri as a command-line tool — The blog of Rob Miller, Ruby developer. Most Rubyists are familiar with Nokogiri.

It’s a combination XML and HTML parsing tool most commonly used for “screen scraping”: that is, fetching a web page, and searching through it to extract information of interest. When a website you’re interested in doesn’t offer an API, it’s often the only way to extract information from it. Nokogiri offers both XPath and CSS interfaces to the documents you load into it; both are enormously powerful, and allow you to quickly hone in on the areas of the page that you want to retrieve. Its CSS selectors will be familiar to anyone who’s written advanced CSS or used jQuery, and are a quick and clear way of zipping down into the page hierarchy to fetch a specific element or set of elements. As an example, we might want to fetch the name of the currently featured article on the English language Wikipedia.
<div id="mp-tfa" style="padding:2px 5px"><div style="float: left; margin: 0.5em 0.9em 0.4em 0;"><! Piping input Interactive mode Voila! XPath Tutorial. In this tutorial, you will be given a gentle introduction to XPath , a query language that can be used to select arbitrary parts of HTML documents in calibre. XPath is a widely used standard, and googling it will yield a ton of information. This tutorial, however, focuses on using XPath for ebook related tasks like finding chapter headings in an unstructured HTML document. The simplest form of selection is to select tags by name. For example, suppose you want to select all the <h2> tags in a document. The XPath query for this is simply: //h:h2 (Selects all <h2> tags) The prefix // means . Select tr>3 with nokogiri. XPather Cheatsheet. Parsing HTML with Nokogiri. Nokogiri The Nokogiri gem is a fantastic library that serves virtually all of our HTML scraping needs.

Once you have it installed, you will likely use it for the remainder of your web-crawling career. Installing Nokogiri Unfortunately, it can be a pain to install because it has various other dependences, libxml2 among them, that may or may not have been correctly installed on your system. Follow the official Nokogiri installation guide here. Hopefully, this step is as painless as typing gem install nokogiri. For the remainder of this section, assume that the first two lines of every script are: require 'rubygems'require 'nokogiri' Opening a page with Nokogiri and open-uri Passing the contents of a webpage to the Nokogiri parser is not much different than opening a regular textfile. If the webpage is stored as a file on your hard drive, you can pass it in like so: page = Nokogiri::HTML(open("index.html")) puts page.class # => Nokogiri::HTML::Document The open-uri module. Rest-client/rest-client. Module: RestClient — Documentation for rest-client (1.6.1)
Defined in: lib/restclient.rb, lib/restclient/payload.rb, lib/restclient/request.rb, lib/restclient/response.rb, lib/restclient/resource.rb, lib/restclient/exceptions.rb, lib/restclient/raw_response.rb, lib/restclient/abstract_response.rb more...
Overview This module's static methods are the entry point for using the REST client. Many Mechanize Examples. Extracting HTML5 data attributes from a tag - ruby pressing answers. Category: ruby, xml, html5, nokogiri Possible Duplicate: Best way to use html5 data attributes with rails content_tag helper?
I want to extract all the HTML5 data attributes from a tag, just like this jQuery plugin. For example, given: <span data-age="50" data-location="London" class="highlight">Joe Bloggs</span> I want to get a hash like: { 'data-age' => '50', 'data-location' => 'London' } Ruby - Nokogiri how to get the parent text and not the childs text and reference the text back to its parent. Andrew!: Web Scraping: How to harvest web data using Ruby and Nokogiri. In this post I will walk through how to use Nokogiri to harvest data from retailer web pages and save that data into a spreadsheet, instead of copying and pasting by hand.
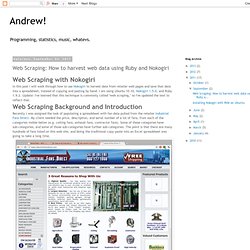
I am using Ubuntu 10.10, Nokogiri 1.5.0, and Ruby 1.9.2. Update: I've learned that this technique is commonly called "web scraping," so I've updated the text to reflect that. Recently I was assigned the task of populating a spreadsheet with fan data pulled from the retailer Industrial Fans Direct. My client needed the price, description, and serial number of a lot of fans, from each of the categories visible below (e.g. ceiling fans, exhaust fans, contractor fans). Some of these categories have sub-categories, and some of those sub-categories have further sub-categories. If we wanted to change that h1 heading to red text, we would use CSS.
An important lesson here: know how to use CSS selectors. First, save a local copy of the HTML document, so that we can play around with its CSS. Nokogiri. Nokogiri parse HTML table in Ruby.