
OWL API. Semantic Technology Developer. EdUcational Curriculum for the usage of LInked Data. Welcome to exascale.info. Home - schema.org. Enabling Networked Knowledge. Main Page - SIOC Wiki. TaskForces/CommunityProjects/LinkingOpenData/CommonVocabularies - W3C Wiki. Ontology Design Patterns . org (ODP) - Odp. Semantic Web Standards. C Semantic Web Interest Group (SWIG) Semantic Web | charter | semantic-web | #swig weblog | ESW Wiki | planetrdf weblogs This is the homepage of W3C's Semantic Web Interest Group (SWIG), previously known as the RDF Interest Group.

It provides a public forum to discuss the use and development of the Semantic Web. See the group's charter for details of its role and purpose. The Semantic Web Interest Group is designed as a forum to support developers and users of Semantic Web technologies (RDF, OWL, SPARQL, etc). The group in particular serves to help developers create vocabularies and applications to support a Web data marketplace combining harvesting, syndication, metadata and Web Service techniques. Membership of the group is open to all interested parties who accept the group's charter; W3C Membership is not a prerequisite. The Interest Group functions primarily through public email lists hosted by W3C. The mailing lists are used for technical discussions. Task Forces Blogs, Wikis, Directories, Meetups.
Rdfabout/intro-to-rdf.md at gh-pages · JoshData/rdfabout. NLPub. NLPub — каталог лингвистических ресурсов для обработки русского языка.
Цель NLPub заключается в предоставлении каталога электронных материалов, направленного на удовлетворение информационных потребностей пользователей, исследователей и разработчиков в области компьютерной лингвистики. Польза для сообщества Требуется помощь. YAGO - D5: Databases and Information Systems (Max-Planck-Institut für Informatik) Overview YAGO is a huge semantic knowledge base, derived from Wikipedia WordNet and GeoNames.
Currently, YAGO has knowledge of more than 10 million entities (like persons, organizations, cities, etc.) and contains more than 120 million facts about these entities. YAGO is special in several ways: The accuracy of YAGO has been manually evaluated, proving a confirmed accuracy of 95%. Every relation is annotated with its confidence value.YAGO combines the clean taxonomy of WordNet with the richness of the Wikipedia category system, assigning the entities to more than 350,000 classes.YAGO is an ontology that is anchored in time and space.
URDF - Scalable Inference in Uncertain RDF Knowledge Bases D5: Databases and Information Systems (Max-Planck-Institut für Informatik) Rdf3x - RISC-style RDF database engine. PARIS - Probabilistic Alignment of Relations, Instances, and Schema. PARIS is a system for the automatic alignment of RDF ontologies.

PARIS aligns not only instances, but also relations and classes. Alignments at the instance level cross-fertilize with alignments at the schema level. Thereby, our system provides a truly holistic solution to the problem of ontology alignment. The heart of the approach is probabilistic, i.e., we measure degrees of matchings based on probability estimates. This allows PARIS to run without parameter tuning. Contributors. DBWeb Team at Télécom ParisTech. YAGO-NAGA - D5: Databases and Information Systems (Max-Planck-Institut für Informatik)
AIDA is a method, implemented in an online tool, for disambiguating mentions of named entities that occur in natural-language text or Web tables.

AMIE (Association Rule Mining under Incomplete Evidence in Ontological Knowledge Bases) is a joint project with the Ontologies group. ANGIE is an active knowledge system for interactive exploration. DEANNA is a framework for natural language question answering over structured knowledge bases. MQL Reference Guide: Table of Contents.
Ontology & Systems Engineering. Comprehensive Listings of Semantic Enterprise Tools. From MIKE2.0 Methodology Here is a starting listing of more than 1000 semantic enterprise and -related tools from a variety of sources. These are mostly links to comprehensive tools listings rather than individual tools. (Individual tools added to the list will likely be migrated over time to their logical listing area.) The Sweet Compendium of Ontology Building Tools. Download as PDF Well, for another client and another purpose, I was goaded into screening my Sweet Tools listing of semantic Web and -related tools and to assemble stuff from every other nook and cranny I could find.

The net result is this enclosed listing of some 140 or so tools — most open source — related to semantic Web ontology building in one way or another. Ever since I wrote my Intrepid Guide to Ontologies nearly three years ago (and one of the more popular articles of this site, though it is now perhaps a bit long in the tooth), I have been intrigued with how these semantic structures are built and maintained. That interest, in no small measure, is why I continue to maintain the Sweet Tools listing. As far as I know, the following is the largest and most comprehensive listing of ontology building tools available. There are some 140 tools, perhaps 90 or so are still in active use. The Protégé Ontology Editor and Knowledge Acquisition System. WebProtégé.
Open source data structs and semantic frameworks. The Open Semantic Framework is a complete and integrated software stack that combines external open source components with specific enhancements developed by Structured Dynamics.
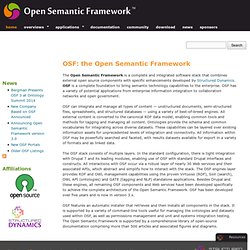
OSF is a complete foundation to bring semantic technology capabilities to the enterprise. OSF has a variety of potential applications from enterprise information integration to collaboration networks and open government. OSF can integrate and manage all types of content — unstructured documents, semi-structured files, spreadsheets, and structured databases — using a variety of best-of-breed engines. All external content is converted to the canonical RDF data model, enabling common tools and methods for tagging and managing all content. Ontologies provide the schema and common vocabularies for integrating across diverse datasets. Vitro - Integrated Ontology Editor and Semantic Web Application.
Data Governance Open Framework - Mike2.0 Methodolgy Wiki. From MIKE2.0 Methodology Introduction The Semantic Enterprise Solution Offering provides a layer for the enterprise to establish coherence, consistency, and interoperability across its information assets.
Applicable information assets may range fully from structured to unstructured (text and document) sources. The methodology of this Offering is: inherently incrementallayered onto existing capabilities and resourcesflexible to accommodate expansions in scope, new learning, and changes the continuum As an implementation proceeds and extends across the enterprise, there are exciting prospects to shift the locus of knowledge management and tools from vendors and the IT function to practicing knowledge workers. Executive Summary The Semantic Enterprise Offering provides an incremental approach to bring interoperability and common understandings with respect to enterprise information. These can be applied to the issues related information interoperability. Solution Offering Purpose. MIKE2.0 - Data and Social Methodology, Open Framework.
From MIKE2.0 Methodology Method for an Integrated Knowledge Environment (MIKE2.0) is an open source delivery framework for Enterprise Information Management. It provides a comprehensive methodology (868 significant articles so far) that can be applied across a number of different projects within the Information Management space. CTRL Semantic Content Enrichment Tool. Semantic Web. I have an idea that I think is very important but I haven’t yet polished to the point where I’m comfortable sharing it.

I’m going to share it anyway, unpolished, because I think it’s that useful. So here I am, handing you a dull, gray stone, and I’m saying there’s a diamond inside. Maybe even a dilithium crystal. Submission Request to W3C: Linked Data Basic Profile 1.0. | Submissions Submission request to W3C ( W3C Team Comment ) Submitted Materials We, W3C Member(s) IBM, DERI, EMC, Oracle, Red Hat, SemanticWeb.com, and Tasktop, hereby submit to the Consortium the following specification, comprising the following document(s) attached hereto: which collectively are referred to as "the Submission". We request the Submission be known as the Linked Data Basic Profile Submission. Abstract The Linked Data Basic Profile 1.0 specification defines a set of best practices and a simple approach for a read-write Linked Data architecture, based on HTTP access to web resources that describe their state using RDF.
Intellectual Property Statements The below statements concerning Copyrights, Trade and Service Marks, and Patents, have been made by the following people on behalf of themselves and their affiliated organizations: Copyrights. Semanticweb.com - The Voice of Semantic Web Business. Sindice - The semantic web index. SIREn: Semantic Information Retrieval Engine. Semantic web. World Wide Web, Online First™ Welcome on the LIRIS website — LIRIS. Information retrieval. Information retrieval is the activity of obtaining information resources relevant to an information need from a collection of information resources.
Searches can be based on metadata or on full-text (or other content-based) indexing. Automated information retrieval systems are used to reduce what has been called "information overload". Many universities and public libraries use IR systems to provide access to books, journals and other documents. Web search engines are the most visible IR applications. Overview[edit] An information retrieval process begins when a user enters a query into the system.
An object is an entity that is represented by information in a database. Most IR systems compute a numeric score on how well each object in the database matches the query, and rank the objects according to this value. History[edit] Model types[edit] For effectively retrieving relevant documents by IR strategies, the documents are typically transformed into a suitable representation. Recall[edit] Evaluation of ranked retrieval results. Next: Assessing relevance Up: Evaluation in information retrieval Previous: Evaluation of unranked retrieval Contents Index Precision, recall, and the F measure are set-based measures. Future Generation Computer Systems - Scalable service discovery in ubiquitous and pervasive computing architectures: A percolation-driven approach. 1. Introduction 2. Related work.