
Drspeedo/vivoconf2013-dataingest. Linked Data. Finding Europeana audio with SPARQL. As a SPARQL geek's alternative to YouTube, the 166,872 video resources with a edm:type value of "VIDEO" look like a tempting way to kill some time.
When I first heard about the SPARQL endpoint for the Europeana aggregation of data about European cultural artifacts, the first example I heard about was an MP3 audio file of a Slovenian version of O sole mio. I happened to be in the middle of packing for a family visit over Christmas and immediately tweeted "Lots of holiday stuff to do, but the new Ontotext Europeana SPARQL endpoint points to MP3s! So tempting... " This past Sunday morning I finally made some time to explore it more, and I found 6,219 audio files. The following query pulls down data about 100 of them (which 100 you pull depends on the OFFSET value), and this XSLT stylesheet converts a SPARQL XML query result version of the results to a simple HTML file that shows the title, creator, and source of each one, with the title being a hypertext link to the audio file itself.
Richard Cyganiak's Homepage. ConverterToRdf - W3C Wiki. A Converter to RDF is a tool which converts application data from an application-specific format into RDF for use with RDF tools and integration with other data.
Converters may be part of a one-time migration effort, or part of a running system which provides a semantic web view of a given application. See also: RDFImportersAndAdapters Please add converters as you make them or hear of them. Formats. MARC Code List for Relators (Network Development and MARC Standards Office, Library of Congress) NOTE: The MARC Code Lists for Relators, Sources, Description Conventions have been reorganized.
Relator terms and codes can be accessed on this page (below). The source code list parts can now be accessed at Source Codes for Vocabularies, Rules, and Schemes. List identifier: marcrelator The purpose of this list of relator terms and associated codes is to allow the relationship between an agent and a resource to be designated in bibliographic records. MARC Genre Term List: Value Lists for Codes and Controlled Vocabularies (Network Development and MARC Standards Office, Library of Congress)
MARC Form of Item Term List: Value Lists for Codes and Controlled Vocabularies (Network Development and MARC Standards Office, Library of Congress) Proof Of Existence. Grants 2014 (texas OR a&m OR university) filetype:xls - National Institutes of Health Search Results. Vivo-project (VIVO: Enabling Network of Scientists Worldwide) Sgvizler - Javascript SPARQL result set visualizer. RDFa 1.1 Distiller and Parser. Warning: This version implements RDFa 1.1 Core, including the handling of the Role Attribute.

The distiller can also run in XHTML+RDFa 1.0 mode (if the incoming XHTML content uses the RDFa 1.0 DTD and/or sets the version attribute). The package available for download, although it may be slightly out of sync with the code running this service. If you intend to use this service regularly on large scale, consider downloading the package and use it locally. Storing a (conceptually) “cached” version of the generated RDF, instead of referring to the live service, might also be an alternative to consider in trying to avoid overloading this server… What is it? RDFa 1.1 is a specification for attributes to be used with XML languages or with HTML5 to express structured data. As installed, this service is a server-side implementation of RDFa. Distiller options Output format (option: format; values: turtle, xml, json, nt; default: turtle) The default output format is Turtle.
Text/html: HTML5+RDFa. SPARQL 1.1 Federated Query. Abstract RDF is a directed, labeled graph data format for representing information in the Web.

SPARQL can be used to express queries across diverse data sources, whether the data is stored natively as RDF or viewed as RDF via middleware. This specification defines the syntax and semantics of SPARQL 1.1 Federated Query extension for executing queries distributed over different SPARQL endpoints. The SERVICE keyword extends SPARQL 1.1 to support queries that merge data distributed across the Web. 1 Introduction The growing number of SPARQL query services offer data consumers an opportunity to merge data distributed across the Web. 1.1 Document Conventions 1.1.2 Result Descriptions Result sets are illustrated in tabular form as in the SPARQL 1.1 Query document.
VIVO Data - what and from where - VIVO. Introduction You've looked at VIVO, you've seen VIVO in action at other universities or organizations, you've downloaded and installed the code.
What next? How do you get information about your institution into your VIVO? The answer may be different everywhere – it depends on a number of factors. How big is your organization? Next – what is different about data in VIVO? As we've described, it's well worth learning the VIVO editing environment and creating sample data even if you know you will require an automated approach to data ingest and update. VIVO makes certain assumptions about data based largely on the types of data, relationships, and attributes described in the VIVO ontology. In VIVO, data about people, organizations, events, courses, places, dates, grants, and everything else are stored in one very simple, three-part structure – the RDF statement.
Symplectic/vivo. BabelNet 2.0 - A very large multilingual encyclopedic dictionary and ontology. Extending Google Refine for VIVO - VIVO. Dr.
Curtis L. Cole, Dan Dickinson, Kenneth Lee, Eliza Chan Weill Cornell Medical College Google Refine (previously Freebase Gridworks) is a freely available open source software package for manipulating datasets. Google Refine strives to provide an easy-to-use toolset to assist in the extraction, review, transformation, and export of datasets. A Direct Mapping of Relational Data to RDF. 1 Introduction Relational databases proliferate both because of their efficiency and their precise definitions, allowing for tools like SQL [SQLFN] to manipulate and examine the contents predictably and efficiently.

Resource Description Framework (RDF) [RDF-concepts] is a data format based on a web-scalable architecture for identification and interpretation of terms. This document defines a mapping from relational representation to an RDF representation. Strategies for mapping relational data to RDF abound. Bibliographic Ontology Usecase Examples. Reconciling DERI researchers using Sindice. In this example, I will reconcile a list of people working at the Digital Enterprise Research Institute DERI with the help of Sindice.
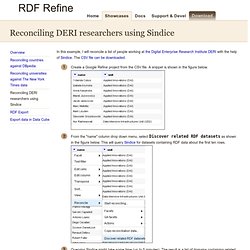
The CSV file can be downloaded. Create a Google Refine project from the CSV file. A snippet is shown in the figure below. From the "name" column drop down menu, select Discover related RDF datasets as shown in the figure below. This will query Sindice for datasets containing RDF data about the first ten rows. AgriVIVO ontology.