
Don’t use a hammer to screw in a nail: Alternatives to REGEX in SPARQL. In the past I’ve talked about some tips for tuning SPARQL performance, but one interesting type of query that I didn’t touch on comes up time and again as a SPARQL performance problem.

In fact, more often than not, it is actually user naiveté that is the real cause. So what does this horrible query look like? Strangely, it is quite innocuous, and I bet a good number of you have written exactly this at some point in the past: While this looks like a perfectly sane query, the fact of the matter is that it is really anything but.
Any kind of FILTER in SPARQL involves iterating over all the possible solutions found at the point where the filter is applied and evaluating the expression. Your SPARQL engine has to look up the actual string value of the variable in question for every possible solution.It has to evaluate a regular expression over that string value. But wait, lots of functions look up the actual value, so why is that such a big issue for REGEX? [1] [2] [3] [4] [5] [6] [7] [8] Web des données - Introduction. Pour aller plus loin avec RDFa. Je répète à longueur de temps que structurer un contenu en XML, et a fortiori en HTML, ne constitue pas une sémantisation, mais permet d'indiquer le rôle joué par la portion d'information dans le contexte d'un document.
Les normes du Web sémantique ont à l'inverse vocation à aider à la sémantisation du contenu. WebSem : outils de recherche. RDF & RDA (RDF pour les bib) ... quand tu descendras du ciel... 17 – RDA & FRBR. Ce billet a pour objet de donner un aperçu de ce que représente le modèle FRBR dans la "philosophie" des RDA.
Pour une meilleure compréhension du discours contenu dans ce post, un rappel des différentes caractéristiques du modèle FRBR s’impose, pour cela voir le billet N° 08 qui lui est consacré dans ce blog. Pour rappel ce modèle est un "cadre conceptuel permettant de comprendre clairement, sous une forme précisément exprimée et dans un langage qui soit parlant pour tout le monde, l’essence même de ce sur quoi la notice bibliographique est censée renseigner ". RDA Vocabularies: Process, Outcome, Use. D-Lib Magazine January/February 2010 Volume 16, Number 1/2Table of Contents RDA Vocabularies: Process, Outcome, Use Printer-friendly Version Abstract The Resource Description and Access (RDA) standard, due to be released this coming summer, has included since May 2007 a parallel effort to build Semantic Web enabled vocabularies.

Introduction RDA (Resource Description and Access) is a new standard for metadata describing resources held in the collections of libraries, archives, museums, and other information management organizations [RDA prospectus]. MADS/RDF (Metadata Authority Description Schema) Référentiels et données d’autorité à l’heure du Web sémantique. Groupe technique sur l'adoption de RDA. The Strongest Link: Libraries and Linked Data. D-Lib Magazine November/December 2010 Volume 16, Number 11/12Table of Contents The Strongest Link: Libraries and Linked Data Gillian Byrne and Lisa Goddard Memorial University Libraries, St.

John's, Newfoundland and Labrador {gbyrne,lgoddard}@mun.ca. Les catalogues sur le Web. RDA and OPACs. Following on from my previous post, about the gap between the standards we apply when creating data and the ways in which we want to use it, I would like to give some thought to what lies in the middle - our OPACs.
We are all data creators - we all create data and edit data and hold it in databases - and we all follow some sort of rules (AACR, RDA, ONIX, DC or whatever) to structure that data. Equally, we all have views on how we want to make the data usable, the ways in which we want to make it available, the things we want people to be able to do with it. We don't necessarily agree about either the kind of data we want, or what we want to do with it. But the fact is that in the middle, for most of us, sits our OPAC - which dictates both the structure we use and what we can do with it. I often curse our LMS supplier into heaps - why can't our OPAC do this, or that? You see, I think that is what RDA is trying to do. CRFCB Tlse - Philippe le Pape "les catalogues changent d'ère" CRFCB Tlse - Françoise Leresche "modelisation des catalogues : les données d'autorité FRAD" CRFCB Tlse - Marc Maisonneuve "quels outils informatiques pour les bibliothèques?"
Use Cases - Library Linked Data. Use Cases. This page lists use cases for the DBpedia knowledge base together with references to ongoing work into these directions. 1.

Revolutionize Wikipedia Search Wikipedia currently only supports keyword-based search and does not allow more expressive queries like “Give me all cities in New Jersey with more than 10,000 inhabitants” or “Give me all Italian musicians from the 18th century.” This lowers the overall utility of Wikipedia. One major application domain for the DBpedia data set is to enable sophisticated queries against Wikipedia, which could revolutionize the access to this valuable knowledge source. Here are three prototypical search interfaces using different approaches to improve Wikipedia search: DBpedia Faceted Search – allows you to explore Wikipedia via a faceted browsing interface. Les technologies du Web appliquées aux données structurées (1ère pa... Les technologies du Web appliquées aux données structurées (2ème pa...
LIBRIS. Semantic Web: Who is who in the field - A bibliometric analysis. SPAR : présentation du projet. Conserver : le projet SPAR et l'archivage numérique Au même titre que les manuscrits, imprimés, estampes ou photographies, il est essentiel d'entreposer de manière sécurisée et pérenne les objets numériques en s'appuyant sur un socle solide et performant, SPAR pour Système de Préservation et d'Archivage Réparti.
La récente accélération de l’accroissement des collections numériques (supérieure à 100 Téraoctets par an aujourd’hui) et la diversité de leurs formats placent la BnF devant le défi de leur conservation. Après plus d'une année d'étude, la BnF a lancé le projet SPAR , véritable magasin numérique. SPAR : a data-first preservation strategy : Datamanagement in SPAR. ARQ - SPARQL Tutorial. Découverte de Sparql pour info-bibliothécaires. SPARQL, comment illuminer vos mashups en consommant les données du ... Documentation D2RQ (mettre sa BDD en RDF) Dewey Fencing, and Getting Started With Bibliographica Linked Data.
If you follow @redjets on Twitter, you can follow the departure and arrival of the Red Funnel catamarans as they travel between Southampton and Cowes.
The service, put together by @andysc, tracks shipping movements on the Solent (AIS is the keyword, if you want to find out how;-) and watches out for the RedJet identifiers entering or leaving geographical areas around the ports. These virtual, digitally created boundaries are often referred to as geofences. So for example, my ‘find folk tweeting near a location’ hack uses the Twitter search API to construct a geofenced locale and then search for tweets within that boundary. But what does that have to do with Dewey? Simply this: if we have easy access to standardised classmarks, such as Dewey Decimal Classification ranges, or sets of Dewey classifications, we can create “Dewey fences” to search for books on a particular topic. The SPARQL page itself gives an example query, which identifies several of the key vocabularies (ontologies? Formation Web sémantique, mise en œuvre et publication de données : formation Web, stratégie, conception avec Orsys.
EA37 - Web sémantique. Le tutoriel SPARQL. L'objectif de ce tutoriel SPARQL est de donner un cours rapide en SPARQL. Le tutoriel couvre les fonctionnalités majeures du langage de requête au travers d'exemples, mais ne vise pas à être complet. Si vous cherchez une courte introduction à SPARQL et Jena, essayez Recherche de données RDF avec SPARQL . SPARQL est un langage de requêtes et un protocole pour accéder au RDF conçu par le groupe de travail du W3C RDF Data Access . Comme un langage de requête, SPARQL est « orienté données » en ce sens qu'il interroge uniquement les informations détenues dans des modèles ; il n'y a pas d'inférence dans le langage de requête lui-même. Évidemment, le modèle Jena peut être « intelligent » en ce sens qu'il fournit l'impression que certains triplets existent en les créant à la demande, y compris le raisonnement OWL.
Commentez Tout d'abord, il faut être clair sur quelles données sont interrogées. Il est important de réaliser que ce sont les triplets qui importent, pas la sérialisation. My Understanding of SPARQL, the First Attempt… (This one’s for Mike…) [Disclaimer: some or all of this post may be wrong...;-)] So (and that was for Niall)… so: here’s what I think I know about SPARQL; or at least, here’s what I think I know about SPARQL and what I think is all you need to know to get started with SPARQL SPARQL is a query language that can interrogate an RDF triple store.
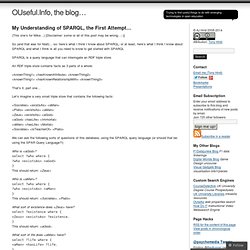
An RDF triple store contains facts as 3 parts of a whole: That’s it, part one… Let’s imagine a very small triple store that contains the following facts: Réutilisation des données publiques. Peu de collectivités se sont à ce jour lancées dans l’open data. Pourtant, la réutilisation des données publiques, qui est un droit depuis 2005, est riche de potentiels pour l’enrichissement des services rendus aux usagers. Mais elle peut bousculer certaines pratiques des administrations. La réutilisation des données culturelles soulève ses propres questions. Eurostat Home. Eurostat RDF datasets - Datasets. Insee - Espace RDF. WOLF (WorldNet français) Accueil.