
42 Big Data Startups. Published by Jeff Vance at Startup50 .
Which ones are missing? I would add Pervasive, Tableau, Splunk, Lavastorm, Yottamine, Alteryx, Pivotal as well as non-product companies. For instance, publishers like DataScienceCentral (self-funded, profitable, with a large list of big data clients). This list contains (too) many Hadoop-related companies. Which companies would you add? Here's a compilation of the most analytic ones, compiled by Gregory . ビッグデータに関する事実 データは企業利益を生んでいるのか. ますます多くの企業が、戦略的リソースとしてのデータの重要性を再認識している。
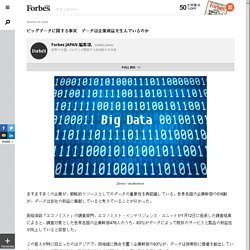
世界各国の企業幹部の約6割が、データは自社の利益に貢献していると考えていることが分かった。 英経済誌「エコノミスト」の調査部門、エコノミスト・インテリジェンス・ユニットが1月12日に発表した調査結果によると、調査対象とした世界各国の企業幹部476人のうち、83%がデータによって既存のサービスと製品の利益性が向上していると回答した。 この答えが特に目立ったのはアジアで、同地域に拠点を置く企業幹部の63%が、データは恒常的に価値を創出していると述べた。 米国では58%、欧州では56%の幹部がこれと同じ考えを示している。 塩野義製薬、SASの機械学習ツールを活用した人工知能技術による臨床試験解析のセミオートメーション化に着手. アナリティクスのリーディング・カンパニーであるSAS Institute Japan株式会社(本社:東京都港区、代表取締役社長:堀田徹哉、以下 SAS)は、塩野義製薬株式会社(本社:大阪市中央区、代表取締役社長:手代木 功、以下 塩野義製薬)が、SASのHadoop対応製品の一つである「SAS® In-Memory Statistics for Hadoop」の機械学習エンジンを活用し、臨床開発業務で使用されるSASプログラムとその関連文書を自動生成する人工知能(AI)アプリケーションの開発に着手したことを発表しました。
Google Statistician uses R and other programming tools. A great interview on the Simply Statistics blog with Google's Nick Chamandy, Phd in Statistics.

Explains that he mainly uses R among other tools to perform his work at Google. Also of note is the active data science community within Google that uses R as well as some other interesting tools. Note that they use a lot of data at Google, understandably, and that R usually can not handle the size. They do a lot of ad hoc reduction of the data with tools like map reduce, Go, and even an R API. I would love to see how they use the R API to assimilate data. An interesting insight from the interview is the amount of programming done by the Statisticians.
マクロミル、POSデータを集計・拡大推計処理するサービスを開始. 10種のオファリング 富士通のビッグデータ ~ Big Data Initiative ~:富士通. Big Data Preview Issue.pdf. 企業動向インフォコム,ビッグデータ領域におけるデータサイエンス事業に参入: Unlocking Big Government Data: Whose Job Is It? - Global-cio - It's not just a good idea for private-sector organizations to help open up the treasure trove of government big data.

It's a necessity. Big Data Talent War: 10 Analytics Job Trends (click image for larger view and for slideshow) As storage pundit Jon Toigo pointed out last week, "big data," like "the cloud" before it, actually meant something when the term was first coined, but it's quickly becoming meaningless. But I'm less concerned about imprecise definitions--that happens with all new technologies--and more concerned with making the reams of publicly owned data more widely available and easily accessible. BIC%20Advance%20Program%20Oct262010. Two McKinsey reports on Big Data. Big Money Says It Is A Paradigm Buster. Four different ways to solve a data science problem - case study. Here we discuss four approaches to solve the following marketing problem: identify, each day, the most popular Google groups, within a large list of target groups.
You want to post in these groups only. The only information that is quickly available for each group, is the time when the last posting occured. Intuitively, the newer the last posting, the most active the group. There are some caveats such as groups where all postings come from one single user - a robot - for instance groups that focus on posting job ads exclusively. Making Advanced Analytics Work for You. Artwork: Tamar Cohen, The Big Quick, 2010, silk screen collage on vintage book pages, 40" x 50" Big data and analytics have rocketed to the top of the corporate agenda.

Executives look with admiration at how Google, Amazon, and others have eclipsed competitors with powerful new business models that derive from an ability to exploit data. They also see that big data is attracting serious investment from technology leaders such as IBM and Hewlett-Packard. Meanwhile, the tide of private-equity and venture-capital investments in big data continues to swell. The trend is generating plenty of hype, but we believe that senior leaders are right to pay attention. 3 Big Data Startups: Locu, Essess, Coursera. 5 Big Data Startups to Watch in 2012. Big data, without question, is a 2011 buzz word finalist. But like all metaphors, it communicates a universal understanding that data dominates our lives and will increasingly do so in the years ahead. How can you deny that a company’s success will depend in great part on how they view data and its value? The belief is not lost on venture capitalists who have invested $350 million in Hadoop and NoSQL startups since 2008.
To commemorate this mega trend, we’ve picked five big data startups and one honorable mention that we believe are ones to watch in 2012. Big Data Is Great, but Don’t Forget Intuition. What Big Data is Really About. What Big Data is Really About Ignore the hype surrounding big data.
What's really important is to learn about the new models for data processing that big data is bringing so you can plan rather than react. By Mark MadsenJanuary 22, 2013 [Editor's note: Mark Madsen is leading several sessions at the TDWI World Conference in Las Vegas February 17-22, 2013. ] Big data isn't hype, but it is being hyped. Meeting the Big Data challenge: Don't be objective.
MasterCard Big Data For Shopping Habits.