
Mistaeks I Hav Made: Faster Word Puzzles with Neo4J. When I used Neo4J to create and solve Word Morph puzzles, I brute-forced the algorithm to find and link words that differ by one letter.

I was lucky – my dataset only contained four-letter words and so was small enough for my O(n2) algorithm to run in a reasonable amount of time.
SQL2Gremlin. Introduction SQL2Gremlin teaches the Gremlin graph traversal language using typical patterns found when querying data with SQL.
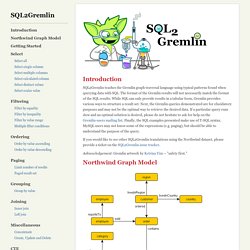
The format of the Gremlin results will not necessarily match the format of the SQL results. While SQL can only provide results in a tabular form, Gremlin provides various ways to structure a result set. Next, the Gremlin queries demonstrated are for elucidatory purposes and may not be the optimal way to retrieve the desired data. If a particular query runs slow and an optimal solution is desired, please do not hesitate to ask for help on the Gremlin-users mailing list. If you would like to see other SQL2Gremlin translations using the Northwind dataset, please provide a ticket on the SQL2Gremlin issue tracker. Acknowledgement: Gremlin artwork by Ketrina Yim -- "safety first. " Northwind Graph Model You can visually examine the graph by viewing the Northwind Graph Visualization. Getting Started. Orientdb - rexster questions.
Ranking - popularity ranking of graph DBMS. Kenny Bastani. Better Software Development. Posted by Michael Hunger on Oct 18, 2014 in cypher, import, neo4j | I have to admit that using our LOAD CSV facility is trickier than you and I would expect.

Several people ran into issues that they could not solve on their own. My first blog post on LOAD CSV is still valid in it own right, and contains important aspects that I won’t repeat here. Both in terms of data quality checking (broken CSV files, misspelt header names or incorrect data types) as well as the concern of transaction size, where PERIODIC COMMIT comes to the rescue.
To address the most frequent issues and questions, I decided to write this follow up post. In general you might have better experience using Neo4j-Enterprise as it contains some components which are more memory efficient. If you want to import much more than 10-15 million lines of data, you might consider using our non-transactional batch-insertion facilities: Clean and Check your CSV-Files Some tools that can help you checking and fixing your CSV: Personalization with Cypher. You hopefully have seen a TV commercial from “The Man Your Man Could Smell Like” marketing campaign put on by Old Spice, and you may have seen some of the over 100 videos Isaiah Mustafa appeared in responding to comments made on Twitter.
This is a great example of personalization, and today you’ll learn how you can bring some personalization to your application, and you won’t need muscles or a horse. We’re going to dust off the Neoflix project from the beginning of the year and add a few features. It has been updated to work on Neo4j version 1.7 and allows searching for movies that have a quote. Thanks to Jenn Alons and Vince Cima for the bug fixes during WindyCityDB.Personalization Strategies When we are looking at an unregistered user (somebody just browsing the site) using the Item based recommendation we already built is all we have to go on.
Opinosis: A Graph Based Approach to Abstractive Summarization of Highly Redundant Opinions. Abstract We present a novel graph-based summarization framework (Opinosis) that generates concise abstractive summaries of highly redundant opinions.
Evaluation results on summarizing user reviews show that Opinosis summaries have better agreement with human summaries compared to the baseline extractive method. The summaries are readable, reasonably well-formed and are informative enough to convey the major opinions. Download Links. Full-Text-Indexing (FTS) in Neo4j 2.0.
Posted by Michael Hunger on Mar 17, 2014 in neo4j | With Neo4j 2.0 we got automatic schema indexes based on labels and properties for exact lookups of nodes on property values.

Fulltext and other indexes (spatial, range) are on the roadmap but not addressed yet. As you probably don’t want to add nodes to an index manually, the existing “auto-index” mechanism should be a good fit. Natural Language Analytics Made Simple and Visual with Neo4j. By Michael Hunger | January 14, 2015 Originally posted on Michael’s Blog I was really impressed by this blog post on Summarizing Opinions with a Graph from Max and always waited for Part 2 to show up The blog post explains a really interesting approach by Kavita Ganesan which uses a graph representation of sentences of review content to extract the most significant statements about a product.
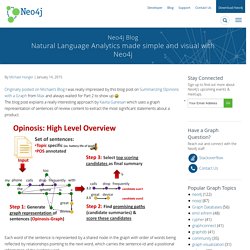
Each word of the sentence is represented by a shared node in the graph with order of words being reflected by relationships pointing to the next word, which carries the sentence-id and a positional information of the leading word. By just looking at the graph structure, it turns out that the most significant statements (positive or negative) are repeated across many reviews. Differences in formulation or inserted fill words only affect the graph structure minimally but reinforce it for the parts where they overlap. In Cypher: The Cypher features used so far: