
New open-source Machine Learning Framework written in Java. Machine Learning & Statistics Programming 331 314 618Share436Share2286Share2 I am happy to announce that the Datumbox Machine Learning Framework is now open sourced under GPL 3.0 and you can download its code from Github!
What is this Framework? The Datumbox Machine Learning Framework is an open-source framework written in Java which enables the rapid development of Machine Learning models and Statistical applications. It is the code that currently powers up the Datumbox API. The main focus of the framework is to include a large number of machine learning algorithms & statistical methods and be able to handle small-medium sized datasets.
What types of models/algorithms are supported? The framework is divided in several Layers such as Machine Learning, Statistics, Mathematics, Algorithms and Utilities. New open-source Machine Learning Framework written in Java. Gensim: Topic modelling for humans. Large Scale Machine Learning and Other Animals. PyBrain. PredictionIO/PredictionIO. Gusto - gusto - What is Gusto? - Gusto is a set of APIs for building intelligent web applications with semantic similarity, collaborative filtering, recommandation, etc. Gusto is a set of APIs for building intelligent web 2.0 applications more easily.
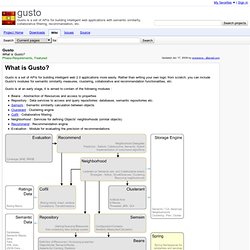
Rather than writing your own logic from scratch, you can include Gusto's modules for semantic similarity measures, clustering, collaborative and recommendation functionalities, etc. Gusto is at an early stage, it is aimed to contain of the following modules : Beans : Abstraction of Resources and access to properties Repository : Data services to access and query repositories: databases, semantic repositories etc. Semsim : Semantic similarity calculation between objects Clusterant : Clustering engine Colfil : Collaborative filtering Neighborhood : Services for defining Objects' neighborhoods (similar objects) Recommend : Recommendation engine Evaluation : Module for evaluating the precision of recommendations Figure - Gusto Architecture and modules At this early stage, the distribution focuses on the Semsim module APIs.
Semsim is the module for measuring the similarity between resources/objects. Python Data Analysis Library — pandas: Python Data Analysis Library. 100 days of web mining. In this experiment, we collected Google News stories at regular 1-hour intervals between November 22, 2010, and March 8, 2011, resulting in a set of 6,405 news stories.
We grouped these per day and then determined the top daily keywords using tf-idf, a measurement of a word's uniqueness or importance. For example: if the word news is mentioned every day, it is not particularly unique at any single given day. To set up the experiment we used the Pattern web mining module for Python.The basic script is simple enough: Your code will probably have some preprocessing steps to save and load the mined news updates. In the image below, important words (i.e., events) that occured across multiple days are highlighted (we took a word's document frequency as an indication). See full size image Simultaneously, we mined Twitter messages containing the words I love or I hate – 35,784 love-tweets and 35,212 hate-tweets in total.
Daily drudge. Pattern. Pattern is a web mining module for the Python programming language.
It has tools for data mining (Google, Twitter and Wikipedia API, a web crawler, a HTML DOM parser), natural language processing (part-of-speech taggers, n-gram search, sentiment analysis, WordNet), machine learning (vector space model, clustering, SVM), network analysis and <canvas> visualization. The module is free, well-document and bundled with 50+ examples and 350+ unit tests.
Download Installation Pattern is written for Python 2.5+ (no support for Python 3 yet). To install Pattern so that the module is available in all Python scripts, from the command line do: > cd pattern-2.6 > python setup.py install If you have pip, you can automatically download and install from the PyPi repository: If none of the above works, you can make Python aware of the module in three ways: Quick overview pattern.web.
About. Background Open source tools have recently reached a level of maturity which makes them suitable for building large-scale real-world systems.

At the same time, the field of machine learning has developed a large body of powerful learning algorithms for a wide range of applications. Inspired by similar efforts in bioinformatics (BOSC) or statistics (useR), our aim is to build a forum for open source software in machine learning. If you want more background about why open source software is important for machine learning, read our position paper about the need for open source software in machine learning. If you have written machine learning software, consider adding it to the projects at mloss.org. Goals Our goal is to support a community creating a comprehensive open source machine learning environment. Related Resources. GraphLab: A New Parallel Framework for Machine Learning. MBSP for Python. MBSP is a text analysis system based on the TiMBL and MBT memory based learning applications developed at CLiPS and ILK.
It provides tools for Tokenization and Sentence Splitting, Part of Speech Tagging, Chunking, Lemmatization, Relation Finding and Prepositional Phrase Attachment. The general English version of MBSP has been trained on data from the Wall Street Journal corpus. Download Documentation Introduction Quick overview MBSP parses a string of characters into words and sentences, and determines the grammatical structure of the sentence. The module uses a client-server architecture for performance. If that doesn't work you'll need to follow the steps in the installation instructions. Put the MBSP folder in the same folder as your Python script and import the module. Each word has been tagged with grammatical information. The tag codes may seem cryptic at first, but consider that it is more concise to say NNS than PLURAL NOUN over and over. Something went wrong? Purpose.
Machine learning in Python — scikit-learn v0.11 documentation. Apache Mahout: Scalable machine learning and data mining.