
Schema Creator for 'Event' schema.org microdata. Structured data is a way for search engine machines to make sense of content in your HTML.
Google and other search engines created a structured data standard called Schema.org. Often these Schema elements trigger specialized SERP features and Rich Cards that can increase the amount of click through you get from your site’s ranking. Schema creator tools When Schema.org was originally released, the core way of including it in your pages was to use microdata inside your HTML elements. The Schema.org vocabulary and method of using microdata attributes was foreign to most web designers. Using microdata attributes seemed elegant at the time, because it meant that you could markup your existing HTML without changing the content or appearance of the pages. It still wasn’t perfect though, and it could become cumbersome to integrate depending on how your pages were originally coded. Comment déposer une marque à l’INPI. Un mot, un slogan, un logo, des chiffres, votre marque peut prendre des apparences différentes.

Quoi qu’il en soit elle représentera l’identité de votre entreprise et sera votre élément distinctif. Recherche catégorie "activites" Recherche catégorie "activites" Événements de Conférence à Paris gratuit/s Paris Conferences Events Meetings. Conférence - Salons Paris - Sortir à Paris. Assister à des conférences gratuites Paris. Ville d’art et de culture, Paris ne manque pas d’animations et d’activités pour s’instruire.
De nombreux espaces culturels et musées proposent des conférences gratuites, par exemple l’auditorium de la Cité des Sciences et de l’Industrie, certains jours et dans la limite des places disponibles. Les Archives de Paris organisent des cycles de conférences tout au long de l’année dont l’accès est totalement gratuit. Histoire, généalogie, patrimoine parisien, personnages célèbres : les thèmes sont variés. Le Cnam (Conservatoire National des Arts et Métiers) accueille très souvent des conférences sur des sujets d’actualité, de sciences sociales et de société. Les invitations gratuites sont à télécharger sur le site.
A l’Université de La Sorbonne, les colloques et les conférences sont libres d’accès. Pour apprendre une langue gratuitement, le Snax Kfé accueille les curieux qui souhaitent converser avec des étrangers lors de ses soirées polyglottes. Musée Quartier : La Villette Monument Snax Kfé Bar. What is import·io? – import.io Knowledge Base. Welcome to import.io!
You're new here right? And you're wondering what we're all about? Well you've come to the right place, let us explain! Import.io is a platform that allows anyone, regardless of technical ability, to get structured data from any website. On this platform we have built an app to help you get all the data you’ve been wanting, but that is locked away on webpages. Our mission is to bring order to the web and make web data available to everyone. Import.io allows you to structure the data you find on webpages into rows and columns, using simple point and click technology. First you locate your data: navigate to a website using our browser (download it from us here: Then, enter our dedicated data extraction workflow by clicking the pink IO button in the top right of the Browser. We will guide you through structuring the data on the page. The data you collect is stored on our cloud servers to be downloaded and shared.
There isn't one! Venez à un scrapathon pour recueillir et transformer des données. Jets.js. Scrapers. To learn more about actually using scrapers in Kodi, please look at: And to learn more about creating scrapers, please look at this article: HOW-TO Write Media Info Scrapers Kodi come with several scrapers for Movies, TV shows and Music Videos which are stored in xbmc\system\scrapers\video.
They are just specially formatted XML files. The location of the scrapers has changed for EDEN Beta 3 - the \scrapers directory is old. The scraper XML file consists of text processing operations that work over a set of text buffers, labelled $$1 to $$20. Web scraping. Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites.[1] Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
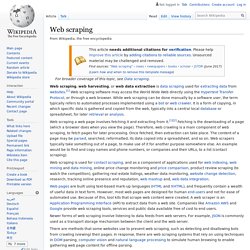
While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis. Web scraping a web page involves fetching it and extracting from it.[1][2] Fetching is the downloading of a page (which a browser does when you view the page). OpenSearchServer Search. OpenSearchServer plugin The OpenSearchServer Search Plugin enables OpenSearchServer full-text search in WordPress-based websites.
OpenSearchServer is an high-performance search engine that includes spell-check, facets, filters, phonetic search, and auto-completion. This plugin automatically replaces the WordPress built-in search function. Key Features. Documentation - Discovering. OpenSearchServer (OSS) is a search engine running on a Windows, Linux or Solaris server.
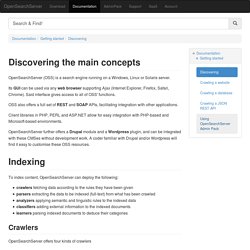
Its GUI can be used via any web browser supporting Ajax (Internet Explorer, Firefox, Safari, Chrome). Said interface gives access to all of OSS' functions. OSS also offers a full set of REST and SOAP APIs, facilitating integration with other applications. Client libraries in PHP, PERL and ASP.NET allow for easy integration with PHP-based and Microsoft-based environments. OpenSearchServer further offers a Drupal module and a Wordpress plugin, and can be integrated with these CMSes without development work. FAQs - Heritrix - IA Webteam Confluence. Web crawler. Not to be confused with offline reader.
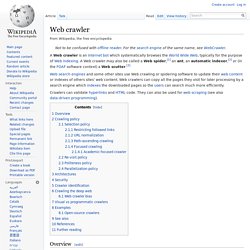
For the search engine of the same name, see WebCrawler. Crawlers can validate hyperlinks and HTML code. They can also be used for web scraping (see also data-driven programming). Overview[edit] How to write a crawler? How To Build A Basic Web Crawler To Pull Information From A Website (Part 1) The Google web crawler will enter your domain and scan every page of your website, extracting page titles, descriptions, keywords, and links – then report back to Google HQ and add the information to their huge database.
Today, I’d like to teach you how to make your own basic crawler – not one that scans the whole Internet, though, but one that is able to extract all the links from a given webpage. Generally, you should make sure you have permission before scraping random websites, as most people consider it to be a very grey legal area. Still, as I say, the web wouldn’t function without these kind of crawlers, so it’s important you understand how they work and how easy they are to make.
To make a simple crawler, we’ll be using the most common programming language of the internet – PHP. Don’t worry if you’ve never programmed in PHP – I’ll be taking you through each step and explaining what each part does.