
Analyse des données. Un article de Wikipédia, l'encyclopédie libre.
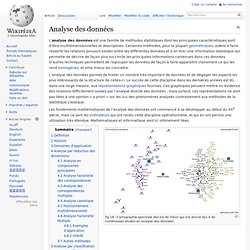
L’analyse des données permet de traiter un nombre très important de données et de dégager les aspects les plus intéressants de la structure de celles-ci. Le succès de cette discipline dans les dernières années est dû, dans une large mesure, aux représentations graphiques fournies. Ces graphiques peuvent mettre en évidence des relations difficilement saisies par l’analyse directe des données ; mais surtout, ces représentations ne sont pas liées à une opinion « a priori » sur les lois des phénomènes analysés contrairement aux méthodes de la statistique classique. Les fondements mathématiques de l’analyse des données ont commencé à se développer au début du XXe siècle, mais ce sont les ordinateurs qui ont rendu cette discipline opérationnelle, et qui en ont permis une utilisation très étendue. Mathématiques et informatique sont ici intimement liées. Définition[modifier | modifier le code] Exploration de données.
Système de gestion de base de données. Un article de Wikipédia, l'encyclopédie libre.
En informatique un système de gestion de base de données (abr. SGBD) est un logiciel système destiné à stocker et à partager des informations dans une base de données, en garantissant la qualité, la pérennité et la confidentialité des informations, tout en cachant la complexité des opérations. NoSQL.
Un article de Wikipédia, l'encyclopédie libre.
En informatique, NoSQL désigne une famille de systèmes de gestion de base de données (SGBD) qui s'écarte du paradigme classique des bases relationnelles. L'explicitation du terme la plus populaire de l'acronyme est Not only SQL (« pas seulement SQL » en anglais) même si cette interprétation peut être discutée[1]. La définition exacte de la famille des SGBD NoSQL reste sujette à débat. Le terme se rattache autant à des caractéristiques techniques qu'à une génération historique de SGBD qui a émergé à la fin des années 2000/début des années 2010[2]. Cloud computing. Un article de Wikipédia, l'encyclopédie libre.

Le cloud computing[1], ou l’informatique en nuage ou nuagique ou encore l’infonuagique (au Québec), est l'exploitation de la puissance de calcul ou de stockage de serveurs informatiques distants par l'intermédiaire d'un réseau, généralement Internet. Ces serveurs sont loués à la demande, le plus souvent par tranche d'utilisation selon des critères techniques (puissance, bande passante, etc.) mais également au forfait. Le cloud computing se caractérise par sa grande souplesse : selon le niveau de compétence de l'utilisateur client, il est possible de gérer soi-même son serveur ou de se contenter d'utiliser des applicatifs distants en mode SaaS[2],[3],[4]. Selon la définition du National Institute of Standards and Technology (NIST), le cloud computing est l'accès via un réseau de télécommunications, à la demande et en libre-service, à des ressources informatiques partagées configurables[5].
Informatique décisionnelle. Un article de Wikipédia, l'encyclopédie libre.

Pour les articles homonymes, voir DSS et BI. Big data. Un article de Wikipédia, l'encyclopédie libre.
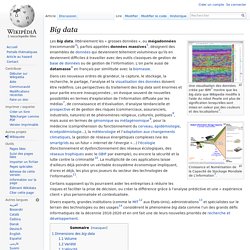
Une visualisation des données créée par IBM[1] montre que les big data que Wikipedia modifie à l'aide du robot Pearle ont plus de signification lorsqu'elles sont mises en valeur par des couleurs et des localisations[2]. Croissance et Numérisation de la Capacité de Stockage Mondiale de L'information[3]. Dans ces nouveaux ordres de grandeur, la capture, le stockage, la recherche, le partage, l'analyse et la visualisation des données doivent être redéfinis. Certains supposent qu'ils pourraient aider les entreprises à réduire les risques et faciliter la prise de décision, ou créer la différence grâce à l'analyse prédictive et une « expérience client » plus personnalisée et contextualisée. Dimensions des big data[modifier | modifier le code] Le Big Data s'accompagne du développement d'applications à visée analytique, qui traitent les données pour en tirer du sens[15].
Volume[modifier | modifier le code] Variété[modifier | modifier le code] Calcul distribué. MapReduce. Un article de Wikipédia, l'encyclopédie libre.
Les termes « map » et « reduce », et les concepts sous-jacents, sont empruntés aux langages de programmation fonctionnelle utilisés pour leur construction (map et réduction de la programmation fonctionnelle et des langages de programmation tableau). MapReduce permet de manipuler de grandes quantités de données en les distribuant dans un cluster de machines pour être traitées. Ce modèle connaît un vif succès auprès de sociétés possédant d'importants centres de traitement de données telles Amazon ou Facebook. Il commence aussi à être utilisé au sein du Cloud computing.
Parallélisme (informatique) Un article de Wikipédia, l'encyclopédie libre.

En informatique, le parallélisme consiste à implémenter des architectures d'électronique numérique permettant de traiter des informations de manière simultanée, ainsi que les algorithmes spécialisés pour celles-ci. Ces techniques ont pour but de réaliser le plus grand nombre d'opérations en un temps le plus petit possible. Les architectures parallèles sont devenues le paradigme dominant pour tous les ordinateurs depuis les années 2000. En effet, la vitesse de traitement qui est liée à l'augmentation de la fréquence des processeurs connait des limites.
La création de processeurs multi-cœurs, traitant plusieurs instructions en même temps au sein du même composant, résout ce dilemme pour les machines de bureau depuis le milieu des années 2000. Les premiers ordinateurs étaient séquentiels, exécutant les instructions l'une après l'autre. Superordinateur. Un article de Wikipédia, l'encyclopédie libre.

Superordinateur à la NASA. Le superordinateur JET. Un superordinateur, ou supercalculateur, est un ordinateur conçu pour atteindre les plus hautes performances possibles avec les technologies connues lors de sa conception, en particulier en termes de vitesse de calcul. La science des superordinateurs est appelée « calcul à haute performance » (en anglais high-performance computing, HPC). Historique[modifier | modifier le code] Les premiers superordinateurs sont apparus dans les années 1960, conçus par Seymour Cray pour le compte de la société Control Data Corporation (CDC), premier constructeur mondial de superordinateurs jusque dans les années 1970.