
Sorting algorithm. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order);The output is a permutation (reordering) of the input.
Further, the data is often taken to be in an array, which allows random access, rather than a list, which only allows sequential access, though often algorithms can be applied with suitable modification to either type of data. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement.
For example, bubble sort was analyzed as early as 1956.[1] A fundamental limit of comparison sorting algorithms is that they require linearithmic time – O(n log n) – in the worst case, though better performance is possible on real-world data (such as almost-sorted data), and algorithms not based on comparison, such as counting sort, can have better performance. Classification[edit] Stability[edit] means. Heapsort. Heapsort is a comparison-based sorting algorithm.
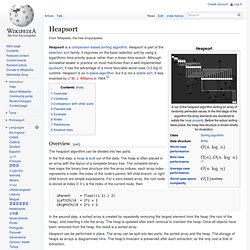
Heapsort is part of the selection sort family; it improves on the basic selection sort by using a logarithmic-time priority queue rather than a linear-time search. Although somewhat slower in practice on most machines than a well-implemented quicksort, it has the advantage of a more favorable worst-case O(n log n) runtime. Heapsort is an in-place algorithm, but it is not a stable sort. It was invented by J. W. Overview[edit] The heapsort algorithm can be divided into two parts. iParent = floor((i-1) / 2) iLeftChild = 2*i + 1 iRightChild = 2*i + 2 In the second step, a sorted array is created by repeatedly removing the largest element from the heap (the root of the heap), and inserting it into the array. Heapsort can be performed in place. Variations[edit] The most important variation to the simple variant is an improvement by R. Comparison with other sorts[edit] Heapsort also competes with merge sort, which has the same time bounds. 1. 2.
Quicksort. A divide and conquer sorting algorithm Quicksort (sometimes called partition-exchange sort) is an efficient sorting algorithm, serving as a systematic method for placing the elements of a random access file or an array in order.
Developed by British computer scientist Tony Hoare in 1959[1] and published in 1961,[2] it is still a commonly used algorithm for sorting. When implemented well, it can be about two or three times faster than its main competitors, merge sort and heapsort.[3][contradictory] Quicksort is a comparison sort, meaning that it can sort items of any type for which a "less-than" relation (formally, a total order) is defined. Merge sort. In computer science, merge sort (also commonly spelled mergesort) is an O(n log n) comparison-based sorting algorithm.
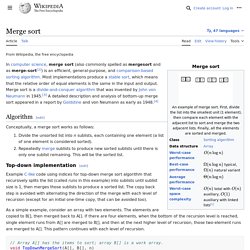
Most implementations produce a stable sort, which means that the implementation preserves the input order of equal elements in the sorted output. Mergesort is a divide and conquer algorithm that was invented by John von Neumann in 1945.[1] A detailed description and analysis of bottom-up mergesort appeared in a report by Goldstine and Neumann as early as 1948.[2] Counting sort. In computer science, counting sort is an algorithm for sorting a collection of objects according to keys that are small integers; that is, it is an integer sorting algorithm.
It operates by counting the number of objects that have each distinct key value, and using arithmetic on those counts to determine the positions of each key value in the output sequence. Its running time is linear in the number of items and the difference between the maximum and minimum key values, so it is only suitable for direct use in situations where the variation in keys is not significantly greater than the number of items. However, it is often used as a subroutine in another sorting algorithm, radix sort, that can handle larger keys more efficiently.[1][2][3] Input and output assumptions[edit] In applications such as in radix sort, a bound on the maximum key value k will be known in advance, and can be assumed to be part of the input to the algorithm. Radix sort. In computer science, radix sort is a non-comparative integer sorting algorithm that sorts data with integer keys by grouping keys by the individual digits which share the same significant position and value.
A positional notation is required, but because integers can represent strings of characters (e.g., names or dates) and specially formatted floating point numbers, radix sort is not limited to integers. Radix sort dates back as far as 1887 to the work of Herman Hollerith on tabulating machines.[1] Most digital computers internally represent all of their data as electronic representations of binary numbers, so processing the digits of integer representations by groups of binary digit representations is most convenient. Two classifications of radix sorts are least significant digit (LSD) radix sorts and most significant digit (MSD) radix sorts. LSD radix sorts process the integer representations starting from the least digit and move towards the most significant digit.