
Data Analytics using Cassandra and Spark - OpenCredo. In recent years, Cassandra has become one of the most widely used NoSQL databases: many of our clients use Cassandra for a variety of different purposes.

This is no accident as it is a great datastore with nice scalability and performance characteristics. However, adopting Cassandra as a single, one size fits all database has several downsides. The partitioned/distributed data storage model makes it difficult (and often very inefficient) to do certain types of queries or data analytics that are much more straightforward in a relational database. Typically, one cannot rely on Cassandra alone when performing aggregations, data analysis and the like.
We can use it to capture all the data we need, but on its own Cassandra’s capabilities are insufficient to use that data to its full extent. In this blog post I intend to show how adopting Spark alongside Cassandra can help solving these problems. Spark from ten thousand feet How does it work? Laying the foundations Option 1: Calculate on the fly . How big data is being mobilised in the fight against leukaemia. Healthy cell function relies on well orchestrated gene activity.
Via a fantastically complex network of interactions, around 30,000 genes cooperate to maintain this delicate balance in each of the 37.2 trillion cells in the human body. Broadly speaking, cancer is a disruption of this balance by genetic changes, or mutations. Mutations can trigger over-activation of genes that normally instruct cells to divide, or inactivation of genes that suppress the development of cancer. When a mutated cell divides, it passes the mutation down to its daughter cells. This leads to the accumulation of non-functioning, abnormal cells that we recognise as cancer. Our laboratory is focused on understanding how one particular cancer – chronic myeloid leukaemia or CML – works. But in the vast majority of patients CML is currently incurable and lifelong treatment means that patients must live with side effects and the chance of drug resistance arising.
A Simple Blood Test for Autism? Study’s Use Of ‘Big Data’ Validates Early Intervention. TROY, N.Y. — A new study conducted by the Center for Biotechnology and Interdisciplinary Studies (CBIS) at the Rensselaer Polytechnic Institute has resulted in the first physiological test for autism, paving the way for earlier diagnoses of the illness as well as more effective intervention and treatment.

The precise causes of autism, a neuro-developmental disorder that afflicts 1.5% of the US population, remain fuzzy at best. Experts in the field suspect a combination of biological and environmental factors, but most children are not formally diagnosed until age of four. By then, autism’s behavioral symptoms are more obvious but the condition is already well-advanced, making treatment more difficult. Many children never get diagnosed until they experience problems in school. Ingestion and Processing of Data for Big Data and IoT Solutions. By Navdeep Singh | March 03, 2017 | Big Data, IoT, Introduction.
New York City public datasets now available on Google BigQuery. By Reto Meier, Google Developer Advocate This rich dataset makes it easy to learn how to explore and visualize data using BigQuery.
New York City is home to 8.5 million residents, and more than 50 million people visit this vibrant and dynamic city each year. With so many sights and sounds, it’s easy to get lost in the details, and lose sight of the big picture: How do New Yorkers actually survive in the “concrete jungle?” What Is Data Science? A Beginner's Guide To Data Science. As the world entered the era of big data, the need for its storage also grew.
It was the main challenge and concern for the enterprise industries until 2010. The main focus was on building framework and solutions to store data. SQL is still superior for big-data analytics – rakam.io. Analyzing NYC Biking Data with Google BigQuery. Posted by Sara Robinson, Developer Advocate After moving to New York a few months ago I started using Citibike, New York’s bike share program.
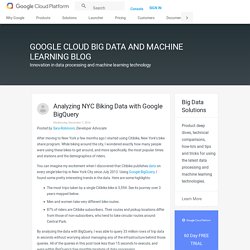
While biking around the city, I wondered exactly how many people were using these bikes to get around, and more specifically, the most popular times and stations and the demographics of riders. Data Wrangling at Slack – Several People Are Coding. By Ronnie Chen and Diana Pojar For a company like Slack that strives to be as data-driven as possible, understanding how our users use our product is essential.
The Data Engineering team at Slack works to provide an ecosystem to help people in the company quickly and easily answer questions about usage, so they can make better and data informed decisions: “Based on a team’s activity within its first week, what is the probability that it will upgrade to a paid team?” Or “What is the performance impact of the newest release of the desktop app?” The Dream. Top Big Data Skills To Future Proof Your Career – Become A Data Engineer Now. Dec 07, 2016 James Powell We live in an era of digital technology where information is key.
Définition : Qu’est-ce que le Big Data ? - LeBigData.fr. Le phénomène Big Data L’explosion quantitative des données numériques a obligé les chercheurs à trouver de nouvelles manières de voir et d’analyser le monde.
Il s’agit de découvrir de nouveaux ordres de grandeur concernant la capture, la recherche, le partage, le stockage, l’analyse et la présentation des données.