
French stemming algorithm. Letters in French include the following accented forms, â à ç ë é ê è ï î ô û ù The following letters are vowels: a e i o u y â à ë é ê è ï î ô û ù Assume the word is in lower case.

Then put into upper case u or i preceded and followed by a vowel, and y preceded or followed by a vowel. u after q is also put into upper case. (The upper case forms are not then classed as vowels — see note on vowel marking.) If the word begins with two vowels, RV is the region after the third letter, otherwise the region after the first vowel not at the beginning of the word, or the end of the word if these positions cannot be found. For example, a i m e r a d o r e r v o l e r t a p i s |...| |.....| |.....| | R1 is the region after the first non-vowel following a vowel, or the end of the word if there is no such non-vowel.
For example: f a m e u s e m e n t |......R1.......| |...R2 Note that R1 can contain RV (adorer), and RV can contain R1 (voler). Start with step 1 Step 1: Standard suffix removal delete if in R2. SnowballC.pdf. Porter Stemming Algorithm. Performance - Counting Words in Files - MATLAB style. For my Matlab class I'm taking, I was given the task to write a function ReadAndCountWords that takes in the name of a text file (specifically from this zip file) as an input argument and then prints out the words contained in that file in order of how many times the word occurs.
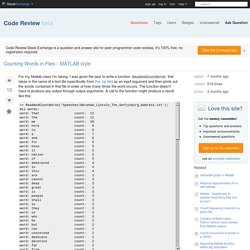
The function doesn't have to produce any output through output arguments. A call to the function might produce a result like this: Some guidelines I was given: The code should drop all punctuation, except for ' (contraction) marks. For example, "don't" should be considered one word. And for extra credit: The Speeches folder contains one more file: stop_words.txt. Example output for extra credit: My implementation (what I'm looking to have reviewed): ReadAndCountWords.m: And the driver (don't review this please): Word_Count_Speeches.m: Running my code with tic; Word_Count_Speeches; toc;, my code ran in 3.047776 seconds.
Are there ways that I can clean up my function more? Estimation non param´etrique de la fonction de d´ependance extr´emale. Competitions. Michael A. Gelbart. Bayesian Optimization is an optimization algorithm that is used when three conditions are met: (1) you have a black box that evaluates the objective function (2) you do not have a black box (or any box) that evaluates the gradient of your objective function (3) your objective function is expensive to evaluate.

Expensive could be in time or money or any other resource that you care about. Because it is expensive to evaluate the objective function, it would be a big waste of resources to numerically estimate the gradient and then use some sort of gradient algorithm. A key observation is that if it is so expensive to evaluate the objective function, then it is reasonable to put substantial effort into deciding where to evaluate the objective function next, since you want few but very informative evaluations.
This is done by using a Gaussian Process (GP) to model the (unknown) objective function. The GP has a mean and variance at every point. Coming soon (submit your own definition here) Apache Spark™ - Lightning-Fast Cluster Computing.