
Machine Learning Project at the University of Waikato in New Zealand Q-learning Model-free reinforcement learning algorithm For any finite Markov decision process, Q-learning finds an optimal policy in the sense of maximizing the expected value of the total reward over any and all successive steps, starting from the current state.[2] Q-learning can identify an optimal action-selection policy for any given finite Markov decision process, given infinite exploration time and a partly random policy.[2] "Q" refers to the function that the algorithm computes – the expected rewards for an action taken in a given state.[3] Reinforcement learning[edit] Reinforcement learning involves an agent, a set of states , and a set of actions per state. , the agent transitions from state to state. The goal of the agent is to maximize its total reward. As an example, consider the process of boarding a train, in which the reward is measured by the negative of the total time spent boarding (alternatively, the cost of boarding the train is equal to the boarding time). Algorithm[edit] After ).
Data that lives forever is possible: Japan's Hitachi As Bob Dylan and the Rolling Stones prove, good music lasts a long time; now Japanese hi-tech giant Hitachi says it can last even longer—a few hundred million years at least. The company on Monday unveiled a method of storing digital information on slivers of quartz glass that can endure extreme temperatures and hostile conditions without degrading, almost forever. And for anyone who updated their LP collection onto CD, only to find they then needed to get it all on MP3, a technology that never needs to change might sound appealing. "The volume of data being created every day is exploding, but in terms of keeping it for later generations, we haven't necessarily improved since the days we inscribed things on stones," Hitachi researcher Kazuyoshi Torii said. "The possibility of losing information may actually have increased," he said, noting the life of digital media currently available—CDs and hard drives—is limited to a few decades or a century at most.
World of lights in the microcosmos - Research News 06-2010-Topic 6 Television screens are becoming increasingly flatter - some have even become almost as thin as a sheet of paper. Their size takes impressive dimensions, much to the delight of home cinema fans. Cellphones and laptops also have ever brighter and more brilliant displays. All of these developments owe their thanks to miniature light-emitting diodes – LEDs – that beam background lighting into a multitude of devices. However, LED technology does have a disadvantage. It is a point light source. To do so, the researchers of IPT developed a process chain with which they can populate large-scale sheets with the necessary microstructures. »It‘s an ultraprecise process,« says Dr. In order to determine if the microstructured master possesses the desired characteristics, it must first be tested based on a few parameters. »The machine can accomplish this task as well,« says Wenzel.
Recurrent neural network A recurrent neural network (RNN) is a class of neural network where connections between units form a directed cycle. This creates an internal state of the network which allows it to exhibit dynamic temporal behavior. Unlike feedforward neural networks, RNNs can use their internal memory to process arbitrary sequences of inputs. This makes them applicable to tasks such as unsegmented connected handwriting recognition, where they have achieved the best known results.[1] Architectures[edit] Fully recurrent network[edit] This is the basic architecture developed in the 1980s: a network of neuron-like units, each with a directed connection to every other unit. For supervised learning in discrete time settings, training sequences of real-valued input vectors become sequences of activations of the input nodes, one input vector at a time. Hopfield network[edit] The Hopfield network is of historic interest although it is not a general RNN, as it is not designed to process sequences of patterns.
Google DeepMind Artificial intelligence research laboratory DeepMind Technologies Limited,[1] trading as Google DeepMind or simply DeepMind, is a British–American artificial intelligence research laboratory which serves as a subsidiary of Alphabet Inc. Founded in the UK in 2010, it was acquired by Google in 2014[8] and merged with Google AI's Google Brain division to become Google DeepMind in April 2023. DeepMind introduced neural Turing machines (neural networks that can access external memory like a conventional Turing machine),[11] resulting in a computer that loosely resembles short-term memory in the human brain.[12][13] The start-up was founded by Demis Hassabis, Shane Legg and Mustafa Suleyman in November 2010.[2] Hassabis and Legg first met at the Gatsby Computational Neuroscience Unit at University College London (UCL).[19] In 2014, DeepMind received the "Company of the Year" award from Cambridge Computer Laboratory.[31] Logo from 2015–2016 Logo from 2016–2019 Products and technologies [edit]
She's Not Talking About It, But Siri Is Plotting World Domination | Gadget Lab Photo: Alex Washburn/Wired Apple has a vision of a future in which the disembodied voice of Siri is your constant companion. It goes something like this: You arrive home at the end of a long day and plop down on the couch. A beer in one hand, your phone in the other, you say, “Siri, open Netflix and play The IT Crowd.” Midway through the program, you feel a draft. This is where Apple is headed with Siri, as the nascent voice-activated AI spreads from our phones to our desktops, our homes and even our dashboards to become our concierge to the digital world. So far, Apple’s results have been a mixed bag at best. “We spend so much time with our cellphones that having an effective personal assistant could be revolutionary,” said Andrew Ng, director of Stanford University’s AI Lab. To do this, Apple must catch up with, and then overtake, Google, which offers voice search capabilities and natural language understanding far superior to Apple’s. But there are signs of progress.
How to Buy a Cheap 27-Inch Monitor from Korea Crossover is a brand you've probably never heard of before. There are a million 21-inch monitors out there, but around 27 inches the choices start to thin out. Big names take over. If you want anything over 1920x1200 pixels, choices are slim. Dell's UltraSharps and Apple's Thunderbolt Display are the go-tos. The rising stars of the monitor world are a group of Korean brands available for import via eBay. The screen is flawless--not a single dead pixel in sight--and after weeks of working, gaming and movie watching, I think the Crossover is the second-best PC upgrade I've ever made, behind a blazing fast SSD. That's part of the dilemma: Korean import monitors are cheap, but the trade-off is risk. The first half of this feature contains my impressions using the Crossover 27Q as my primary monitor for a few months. A Few Months with the Crossover 27Q The Crossover 27Q doesn't look or feel like a cheap $400 monitor. But the Crossover's stand is good out of the box. Crossover 27Q: About $400
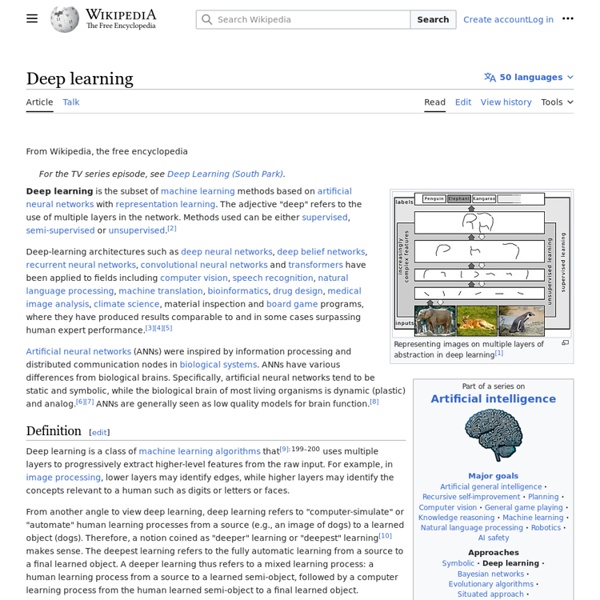
Artificial neural network An artificial neural network is an interconnected group of nodes, akin to the vast network of neurons in a brain. Here, each circular node represents an artificial neuron and an arrow represents a connection from the output of one neuron to the input of another. For example, a neural network for handwriting recognition is defined by a set of input neurons which may be activated by the pixels of an input image. After being weighted and transformed by a function (determined by the network's designer), the activations of these neurons are then passed on to other neurons. This process is repeated until finally, an output neuron is activated. Like other machine learning methods - systems that learn from data - neural networks have been used to solve a wide variety of tasks that are hard to solve using ordinary rule-based programming, including computer vision and speech recognition. Background[edit] There is no single formal definition of what an artificial neural network is. History[edit] and
Demis Hassabis Demis Hassabis (born 27 July 1976) is a British computer game designer, artificial intelligence programmer, neuroscientist and world-class games player.[4][3][5][6][7][1][8][9][10][11] Education[edit] Career[edit] Recently some of Hassabis' findings and interpretations have been challenged by other researchers. A paper by Larry R. In 2011, he left academia to co-found DeepMind Technologies, a London-based machine learning startup. In January 2014 DeepMind was acquired by Google for a reported £400 million, where Hassabis is now an Engineering Director leading their general AI projects.[12][23][24][25] Awards and honours[edit] Hassabis was elected as a Fellow of the Royal Society of Arts (FRSA) in 2009 for his game design work.[26] Personal life[edit] Hassabis lives in North London with his wife and two sons. References[edit]
Can A Computer Finally Pass For Human? “Why not develop music in ways unknown…? If beauty is present, it is present.” That’s Emily Howell talking – a highly creative computer program written in LISP by U.C. Santa Cruz professor David Cope. (While Cope insists he’s a music professor first, “he manages to leverage his knowledge of computer science into some highly sophisticated AI programming.”) Classical musicians refuse to perform Emily’s compositions, and Cope says they believe “the creation of music is innately human, and somehow this computer program was a threat…to that unique human aspect of creation.” The article includes a sample of her music, as intriguing as her haiku-like responses to queries. Share Dimensionality reduction In machine learning and statistics, dimensionality reduction or dimension reduction is the process of reducing the number of random variables under consideration,[1] and can be divided into feature selection and feature extraction.[2] Feature selection[edit] Feature extraction[edit] The main linear technique for dimensionality reduction, principal component analysis, performs a linear mapping of the data to a lower-dimensional space in such a way that the variance of the data in the low-dimensional representation is maximized. In practice, the correlation matrix of the data is constructed and the eigenvectors on this matrix are computed. The eigenvectors that correspond to the largest eigenvalues (the principal components) can now be used to reconstruct a large fraction of the variance of the original data. Principal component analysis can be employed in a nonlinear way by means of the kernel trick. Dimension reduction[edit] See also[edit] Notes[edit] Jump up ^ Roweis, S. References[edit]
Silk Road Creator Ross Ulbricht Sentenced to Life in Prison Ross Ulbricht conceived of his Silk Road black market as an online utopia beyond law enforcement’s reach. Now he’ll spend the rest of his life firmly in its grasp, locked inside a federal penitentiary. On Friday Ulbricht was sentenced to life in prison without the possibility of parole for his role in creating and running Silk Road’s billion-dollar, anonymous black market for drugs. Judge Katherine Forrest gave Ulbricht the most severe sentence possible, beyond what even the prosecution had explicitly requested. The minimum Ulbricht could have served was 20 years. “The stated purpose [of the Silk Road] was to be beyond the law. In addition to his prison sentence, Ulbricht was also ordered to pay a massive restitution of more than $183 million, what the prosecution had estimated to be the total sales of illegal drugs and counterfeit IDs through the Silk Road—at a certain bitcoin exchange rate—over the course of its time online. Go Back to Top.
Robot learns ‘self-awareness’ Who’s that good-looking guy? Nico examines itself and its surroundings in the mirror. (Credit: Justin Hart / Yale University ) “Only humans can be self-aware.” Another myth bites the dust. Why is this important? Using knowledge that it has learned about itself, Nico is able to use a mirror as an instrument for spatial reasoning, allowing it to accurately determine where objects are located in space based on their reflections, rather than naively believing them to exist behind the mirror. Nico’s programmer, roboticist Justin Hart, a member of the Social Robotics Lab, focuses his thesis research primarily on “robots autonomously learning about their bodies and senses,” but he also explores human-robot interaction, “including projects on social presence, attributions of intentionality, and people’s perception of robots.” “Only humans can be self-aware” joins “Only humans can recognize faces” and other disgarded myths. Nico in the looking glass References: Justin W.