
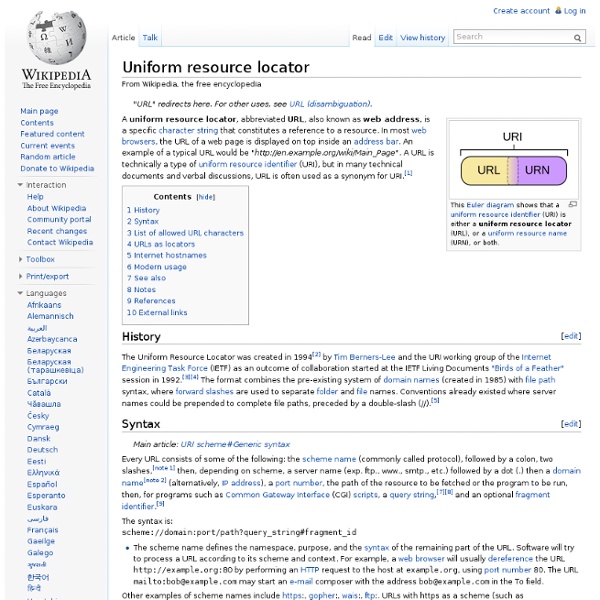
Uniform resource identifier Relationship to URL and URN[edit] URIs can be classified as locators (URLs), as names (URNs), or as both. A uniform resource name (URN) functions like a person's name, while a uniform resource locator (URL) resembles that person's street address. URLs and URNs[edit] A URL is a URI that, in addition to identifying a web resource, specifies the means of acting upon or obtaining the representation: providing both the primary access mechanism, and the network "location". A URN is a URI that identifies a resource by name, in a particular namespace. Syntax[edit] Percent-encoding can add extra information to a URI. History[edit] Naming, addressing, and identifying resources[edit] URIs and URLs have a shared history. Over the next three and a half years, as the World Wide Web's core technologies of HTML (the HyperText Markup Language), HTTP, and web browsers developed, a need to distinguish a string that provided an address for a resource from a string that merely named a resource emerged.
Turtle (syntax) Turtle (Terse RDF Triple Language) is a format for expressing data in the Resource Description Framework (RDF) data model with the syntax similar to SPARQL. RDF, in turn, represents information using "triples", each of which consists of a subject, a predicate, and an object. Each of those items is expressed as a Web URI. Turtle provides a way to group three URIs to make a triple, and provides ways to abbreviate such information, for example by factoring out common portions of URIs. < . SPARQL, the query language for RDF, uses a syntax similar to Turtle for expressing query patterns. In 2011, a working group of the World Wide Web Consortium (W3C) started working on an updated version of RDF, which is intended to be published along with a standardised version of Turtle. @prefix rdf: < . (Turtle examples are also valid Notation3).
Notation 3 Logic Up to Design Issues An RDF language for the Semantic Web This article gives an operational semantics for Notation3 (N3) and some RDF properties for expressing logic. These properties, together with N3's extensions of RDF to include variables and nested graphs, allow N3 to be used to express rules in a web environment. This is an informal semantics in that should be understandable by a human being but is not a machine readable formal semantics. This document is aimed at a logician wanting to a reference by which to compare N3 Logic with other languages, and at the engineer coding an implementation of N3 Logic and who wants to check the detailed semantics. These properties are not part of the N3 language, but are properties which allow N3 to be used to express rules, and rules which talk about the provenance of information, contents of documents on the web, and so on. The log: namespace has functions, which have built-in meaning for CWM and other software. See also: Motivation Formal syntax
RDFa 1.1 Distiller and Parser Warning: This version implements RDFa 1.1 Core, including the handling of the Role Attribute. The distiller can also run in XHTML+RDFa 1.0 mode (if the incoming XHTML content uses the RDFa 1.0 DTD and/or sets the version attribute). The package available for download, although it may be slightly out of sync with the code running this service. If you intend to use this service regularly on large scale, consider downloading the package and use it locally. What is it? RDFa 1.1 is a specification for attributes to be used with XML languages or with HTML5 to express structured data. As installed, this service is a server-side implementation of RDFa. Distiller options Output format (option: format; values: turtle, xml, json, nt; default: turtle) The default output format is Turtle. Warnings for non RDFa 1.1 Lite usage (option: rdfa_lite; values: true, false; default: false) Host language (option: host_language; values: xhtml, html, svg, atom, xml; default: html) Determination of host language type
RDF - Semantic Web Standards Overview RDF is a standard model for data interchange on the Web. RDF has features that facilitate data merging even if the underlying schemas differ, and it specifically supports the evolution of schemas over time without requiring all the data consumers to be changed. RDF extends the linking structure of the Web to use URIs to name the relationship between things as well as the two ends of the link (this is usually referred to as a “triple”). Using this simple model, it allows structured and semi-structured data to be mixed, exposed, and shared across different applications. This linking structure forms a directed, labeled graph, where the edges represent the named link between two resources, represented by the graph nodes. Recommended Reading The RDF 1.1 specification consists of a suite of W3C Recommendations and Working Group Notes, published in 2014. A number of textbooks have been published on RDF and on Semantic Web in general. Discussions on a possible next version of RDF
Resource Description Framework (RDF) Schema Specification 1.0 W3C Candidate Recommendation 27 March 2000 This Version: Latest Version: Previous Version: Editors: Dan Brickley, University of Bristol R.V. Acknowledgments Copyright ©1998,1999,2000 W3C® (MIT, INRIA, Keio), All Rights Reserved. Abstract This specification describes how to use RDF to describe RDF vocabularies. Status of this document This document is a Candidate Recommendation of the World Wide Web Consortium. This specification is a revision of the Proposed Recommendation of March 03 1999, incorporating editorial suggestions received in review comments. The Resource Description Framework is part of the W3C Metadata Activity. This section describes the status of this document at the time of its publication. It is inappropriate to use W3C Candidate Recommendations as reference material or to cite them as other than "work in progress". Table of Contents 1. 1.1. 1.1.1. 2.
Tutorial 3: Semantic Modeling Next: Introducing RDFS & OWL Whilst RDF offers a flexible, graph-based model for recording data that is interchangable globally, it doesn't offer any means to record semantics or meaning. Saving technical specifics for the next lesson, let's make a review of the models of data which are commonly available and explain what all the fuss is about. After this tutorial, you should be able to: Compare and contrast the properties of the various data modeling types and their typical scope.Recognise the benefits that the semantic web model offers over traditional modeling approaches.Understand the terms vocabulary and ontology in semantic web terms.Understand the role of metadata initiatives (e.g. You should have already understood the following lesson (and pre-requisites) before you begin: Tutorial 2: Introducing RDF There are various popular, mainstream ways to model data, some of which have emerged later than others. 3.1 Comparing The Popular Data Models 3.2 Why Include Semantics In Data?
The Semantic Web: Where is it now? – Rashif “Ray” Rahman Although there is no Gartner report to show for it, the period 2006 to 2010 marks the most exciting time yet for semantic (web) technologies. Peak of inflated expectations of the vision, perhaps? Freebase was in full swing, and would later go on to be acquired by Google and become the foundation for its very own proprietary Knowledge Graph. SPARQL v1.1,OWL v2 and SPIN were introduced to provide much needed RDF querying flexibility, ontology intelligence and reasoning capabilities. The years also saw the publication of three important books in the field: my personal favourite Foundations of Semantic Web Technologies, Semantic Web for the Working Ontologist, and Programing the Semantic Web (one of the few using Python, at a time when the field was dominated mostly by Java and still is). Universities were also integrating key topics into their degree programmes, and professional institutes started offering certifications.