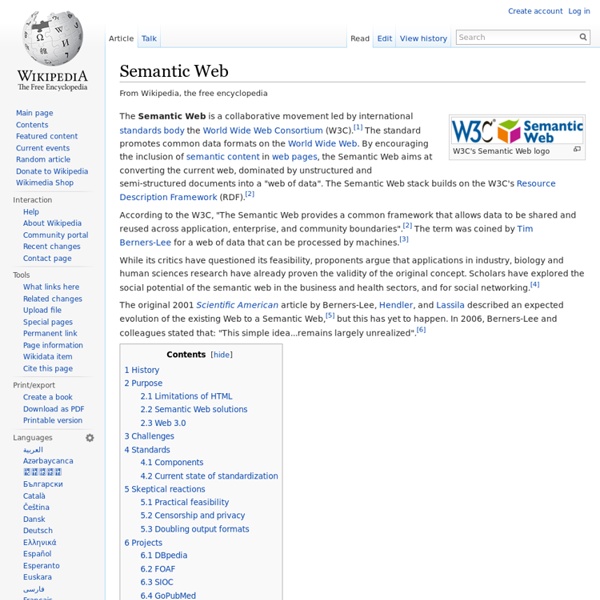
Visualizing the contents of social bookmarking systems
I’ve decided to post a few visualizations I’ve made some time ago as part of my PhD work. The method has been published, but more as a sidenote [1]; also, I’ve since applied it to additional datasets, so I thought it might be interesting to share those images. In my PhD thesis, I try to make sense of the large bodies of data that are accumulated by people saving resources online, tagging them with whatever words they choose in order to find them later on. Each time a user u saves a document d, using the tags t1, t2, and t3, three triples (d,u,t1), (d,u,t2), (d,u,t3) are created. In this way, the users of large social bookmarking sites like Delicious have created datasets of several hundreds of millions of triples. Over the last years, a whole body of literature has been created that’s concerned with making sense of this data (there’s an intuition that something valuable is in there; after all, each of these millions of triples means that somebody has thought *something*!).
MusicBrainz
MusicBrainz captures information about artists, their recorded works, and the relationships between them. Recorded works entries capture at a minimum the album title, track titles, and the length of each track. These entries are maintained by volunteer editors who follow community written style guidelines. Recorded works can additionally store information about the release date and country, the CD ID, cover art, acoustic fingerprint, free-form annotation text and other metadata.
The Invisible Web
What is the Invisible Web? How can you find it online? What makes the Invisible Web search engines and Invisible Web databases so special?
Resource Description Framework
The Resource Description Framework (RDF) is a family of World Wide Web Consortium (W3C) specifications[1] originally designed as a metadata data model. It has come to be used as a general method for conceptual description or modeling of information that is implemented in web resources, using a variety of syntax notations and data serialization formats. It is also used in knowledge management applications. RDF was adopted as a W3C recommendation in 1999. The RDF 1.0 specification was published in 2004, the RDF 1.1 specification in 2014. Overview[edit]
Microformats Role Play
Microformats have been getting a fair amount of attention these days. Between the new value class pattern, Google's Rich Snippets and the Associated Press's move to create hNews (though, technically not a microformat), not a day goes by that I don't see a blog post or article about microformats And yet, despite all this coverage, I’m still regularly asked to explain what microformats really are. My generic, high-level explanation is always something along the lines of: Microformats are simple, open design patterns based on existing standards that you use to describe and add meaning to common web content, such as that about people, places, events and links.
Tag (metadata)
The use of keywords as part of an identification and classification system long predates computers. Paper data storage devices, notably edge-notched cards, that permitted classification and sorting by multiple criteria were already in use prior to the twentieth century, and faceted classification has been used by libraries since the 1930s. Online databases and early websites deployed keyword tags as a way for publishers to help users find content.
Music
This article is about music as a form of art. For history see articles for History of music and Music history. The creation, performance, significance, and even the definition of music vary according to culture and social context. Music ranges from strictly organized compositions (and their recreation in performance), through improvisational music to aleatoric forms. Music can be divided into genres and subgenres, although the dividing lines and relationships between music genres are often subtle, sometimes open to personal interpretation, and occasionally controversial.
The Best Reference Sites
Whether you're looking for the average rainfall in the Amazon rainforest, researching Roman history, or just having fun learning to find information, you'll get some great help using my list of the best research and reference sites on the Web. About.com: I've found many answers to some pretty obscure questions right here at About.Reference.com.Extremely simple to use, very basically laid out.Refdesk.com.Includes in-depth research links to breaking news, Word of the Day,and Daily Pictures. A fun site with a ton of information.Encyclopedia.com. As stated on their site, Encyclopedia.com provides users with more than 57,000 frequently updated articles from the Columbia Encyclopedia, Sixth Edition.Encyclopedia Brittanica. One of the world's oldest encyclopedias online.Encarta.Put together by Microsoft. I like Encarta because it's very easy to use.Open Directory Reference.
Distributed computing
"Distributed Information Processing" redirects here. For the computer company, see DIP Research. Distributed computing is a field of computer science that studies distributed systems. A distributed system is a software system in which components located on networked computers communicate and coordinate their actions by passing messages.[1] The components interact with each other in order to achieve a common goal. Three significant characteristics of distributed systems are: concurrency of components, lack of a global clock, and independent failure of components.[1] Examples of distributed systems vary from SOA-based systems to massively multiplayer online games to peer-to-peer applications.
Managing your project's critical path - Project
You may wonder, "what ultimately determines the length of my project?" The answer is the critical path (critical path: The series of tasks that must be completed on schedule for a project to finish on schedule. Each task on the critical path is a critical task.), which is the series of tasks (or even a single task) that dictates the calculated finish date of the project in Project path and the resources assigned to them will help ensure that your project finishes on time. What does the critical path show about your project? What is a critical task? How does Project calculate the critical path?